Document context for translatable user interface strings in Kolibri
Organization or Project: Kolibri
Organization Description: Learning Equality (LE) is a non-profit organization based in the United States that creates and supports tools to enable equitable access to high-quality educational opportunities, with an emphasis on supporting effective education technology interventions in low-connectivity contexts. Learning Equality’s work emerged out of the recognition that the same global populations that have the least access to quality education also have the least access to the growing wealth of learning resources available online.
We work closely to co-design the product with a core network of collaborators, including national NGOs, UN agencies, government, and corporate partners, while also taking a needs-based approach to its development through insights gathered from Kolibri’s global user community. Through its do-it-yourself adoption model and strategic collaborations, Kolibri has reached learners and educators in more than 205 countries and territories.
Launched in 2017, Kolibri is an end-to-end suite of open-source tools, content, and DIY support materials, designed for offline-first teaching and learning. Centered around an offline learning platform that runs on a variety of low-cost and legacy devices, the Kolibri Product Ecosystem also includes a curricular tool, a library of open educational materials, and a toolkit of resources to support training and implementation. These tools are available in a variety of languages, to better support learners and educators globally.
Problem Statement
In the spirit of LE’s mission to support the varied learning needs of the underserved populations in their own local languages, we often rely on translations by volunteers and grassroot crowdsourced contributions, instead of professional localization services.
Crowdin, the platform we have been using for the localization of Kolibri, offers two features to aid translators to better understand the meaning and setting where each of the strings is located in the Kolibri user interface (UI): string context, and UI screenshot.
Without context, when translators do not fully understand a word or a phrase that appears in the Kolibri UI, they have the option to raise an issue with LE’s i18n team, and ask for support to comprehend the string in order to provide the most appropriate translation. The main purpose of providing context on Crowdin is to enable an optimal translation experience (even by non-professional translators), decrease the number of support questions and issues, and ultimately provide better user experience in localized versions of Kolibri.
Project Description
Creating the proposal
LE successfully participated in the first edition of GSoD in 2019, and repeated with two projects during the 2020 edition. GSoD organization administrator Radina Matic has also been supporting Kolibri community translators on Crowdin for several years, and has been aware of the challenges for localization contributors. When GSoD 2021 was announced, she suggested to the team that LE this year could apply with a documentation project to support the internationalization and localization processes of Kolibri.
The initial idea received positive opinions from the wider team, and Carine Diaz (LE Internalization Lead), Jacob Pierce (Full Stack Developer), and Devon Rueckner (Product Manager) reviewed the draft org application proposal written by Radina Matic. Sarah Setiawan (Operations Manager) reviewed the GSoD program administrative requirements, and steps needed to set up the Open Collective account to manage the grant payments.
Budget
For the past two releases of Kolibri all the new strings went through the i18n audit process during which we also wrote the context for strings. We relied on the experience from these audits to estimate the time needed to describe a string and add a screenshot.
On the other hand, we used Crowdin’s tracking features to calculate that around 1,750 of strings are the legacy ones that lacked the proper context to enable easier translation. We expected some variance between our estimation and the final hours the writer would have needed to invest, as the time needed to describe the context and take the screenshot can vary considerably between strings. Some strings are fairly easy to find in the UI and describe, others require stronger familiarity with various Kolibri workflows, and a specific set of conditions to trigger them.
However, the final account of hours needed to complete the project by the writer was just slightly under our estimated budget (91%).
Participants
The core team working on this project was:
- Radina Matic - Main PoC and Project Coordinator
- Carine Diaz - LE Internalization Lead
- Jacob Pierce - Full Stack Developer
- Ian Cowley - GSoD technical writer
Once the LE proposal was accepted, we circulated the project job description on various online channels like Write the Docs Slack, LE’s newsletter and social media and through personal networks to reach the widest possible group of potential candidates. Radina Matic reviewed the Season of Docs GitHub repository list and contacted a selection of writers who expressed interest, asking them to read the LE GSoD project idea and apply for the position if interested.
We maintained a similar selection process format as it has proved successful during the previous years:
- All applicants who expressed interest were invited to our team's Slack workspace, so communication could be centralized in one space and not fragmented on DMs or emails.
- In addition to the project job description on GitHub, we prepared detailed guidelines for writing the statement of interest, a document that specified all the required and optional steps during the selection process.
- Applicants needed to complete and submit the context writing task in order to be considered for the project.
Of the 25 applicants who asked to join the LE Slack, 19 submitted the application and finished the context writing task. After reviewing their task submissions and the statements of interest, we invited Ian Cowley to join the project and work with LE on improving the context of UI strings of Kolibri. Ian brought a specific skill-set that matched those required by our project, a strong previous experience in the software localization field, specifically around glossary and terminology maintenance.
At the end of the selection process we sent personalized replies to all the applicants who submitted the required tasks, with feedback around what they could work on to keep improving their technical writing skills for future job opportunities. It was satisfying to see that the majority of applicants reported a good experience during the selection process and a spirit of community bonding (see screenshot below).
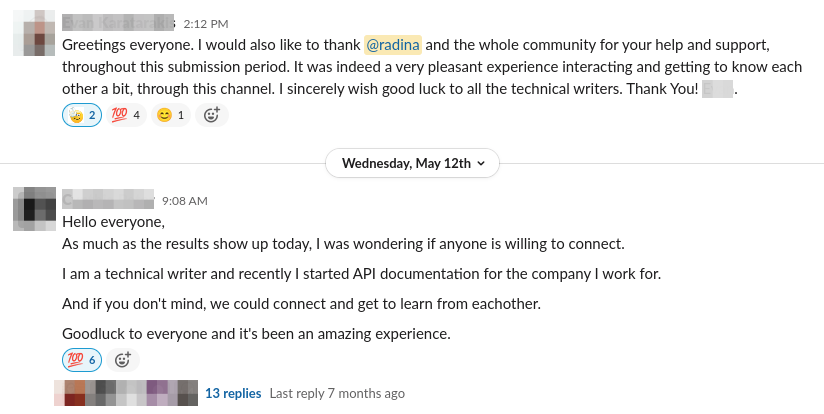
Ian is located in the same timezone as Radina, and they maintained a weekly sync-up meeting on Mondays to go over the progress and clear up any issues or doubts that arose during the week. They also often communicated async on Slack with the rest of LE team members involved in the project, to exchange questions and answers.
On top of following Ian’s progress on Crowdin, Radina invited Ian on several team Notion pages to support his work, as he kept a running list of string issues that needed to be addressed during the work on the new version of Kolibri.
It was a pleasure to work with Ian during the past 6 months, he has made great contributions to our project, and we hope to have an opportunity to work again in the future.
Timeline
Before the GSoD Doc development phase begun, we reviewed the legacy strings and decided the priority of the strings, taking into account these criteria:
- user roles (core and learner-facing strings first, backend strings last)
- term complexity (some strings with common words did not necessarily require a detailed context description).
Project progressed with the following schedule:
Stage | Completed By |
Phase I (onboarding) | 18 May |
Phase II (core user- and learner-facing strings) | 15 June |
Phase III (coach user-facing strings) | 30 June |
Phase IV (admin user-facing strings) | 31 July |
Phases II-IV progress reviewed by Radina Matic | 16 August |
Screenshots (core user- and learner-facing strings) | 10 September |
Screenshots (coach user-facing strings) | 15 October |
Screenshots (admin user-facing strings) | 5 November |
Screenshots reviewed by Radina Matic | 16 November |
In the Contractor Agreement we had stipulated that the technical writer would spend up to 40 hours a month working on our project. Ian kept records of time spent and averaged 34 hours per month.
Results
Reviewing the current status of source UI strings on Crowdin reveals only 86 strings without the described context:
kolibri.core.default_frontend-messages.csv | 13 |
kolibri.plugins.demo_server.main-messages.csv | 0 |
kolibri.plugins.user.app-messages.csv | 2 |
kolibri.plugins.learn.app-messages.csv | 6 |
media viewer plugins (epub, pdf, h5p, html, video, etc.) | 1 |
kolibri_exercise_perseus_plugin.main-messages.csv | 45 |
kolibri.plugins.coach.app-messages.csv | 7 |
kolibri.plugins.facility.app-messages.csv | 11 |
kolibri.plugins.setup_wizard.app-messages.csv | 0 |
kolibri.plugins.device.app-messages.csv | 1 |
django.po (backend) | - |
Total | 86 |
More than half of strings without the described context correspond to the Perseus library, which is a prerequisite to be able to render the Khan Academy exercises in Kolibri. Given that only some complex software architecture constraints force us to maintain Perseus together with the Kolibri code, but we do not have the possibility to fully manage the strings inside, it becomes unattainable to properly describe the context or take a screenshot for all of them.
Metrics
In our project description, we proposed two metrics:
- Decreased number of support requests and issues raised by the translators on Crowdin as a result of newly documented context, and ultimately a downstream user feedback on improved translation accuracy.
- Total number (or overall percentage) of P0 prioritized strings that have the context documented during the GSoD project.
The results from the table under the previous heading correspond fully to our expectations around the second completion metric of the project.
We have also already experienced a lower number of support requests and issues raised by the translators on Crowdin. Not all comments on Crowdin platform indicate that the string in question was unclear for translators (there are some with technical doubts around ICU pluralization formatting, while some support requests may also come by email), but asking questions in comments on Crowdin is the main venue for the translators to reach out for clarification around the string context. Reviewing the number of comments for Kolibri version 0.14 (where only a fraction of strings had their context described) to compare it with the comments on the upcoming Kolibri version 0.15 (for which we just wrapped up the string freeze and the translation round) reveals the following status:
version | total number of strings | strings with comments | % | ~ratio |
Kolibri 0.14 | 1840 | 279 | 15.16 | 1:7 |
Kolibri 0.15 | 1853 | 67 | 3.62 | 1:28 |
Analysis
Parallel to describing legacy strings on Crowdin, Ian kept detailed notes on all the inconsistencies in the terminology used in the user interface, recording duplicate or unclear strings he encountered. This audit allowed us to correct and improve these string instances, and consolidate the UX writing in the codebase for the version 0.15, which resulted in smaller final word count, less time pressure on the translation teams, and a decrease of the i18n costs for the LE budget.
The timing of this program also worked wonderfully, as during the second half of September we had the string freeze for the new version of Kolibri, release 0.15, so the translators for the 4 new locales we introduced in this version had a benefit of having the context of almost all the strings fully described and many of them underpinned by a UI screenshot.
Summary
LE’s third participation in the Season of Docs program has been another great experience for our team, and the technical writer who contributed to our project. Results reflected in our metrics speak clearly of success, and great benefits from the outcome: we already received direct recognition from translators that the context description and screenshots are very helpful features (see screenshot below).
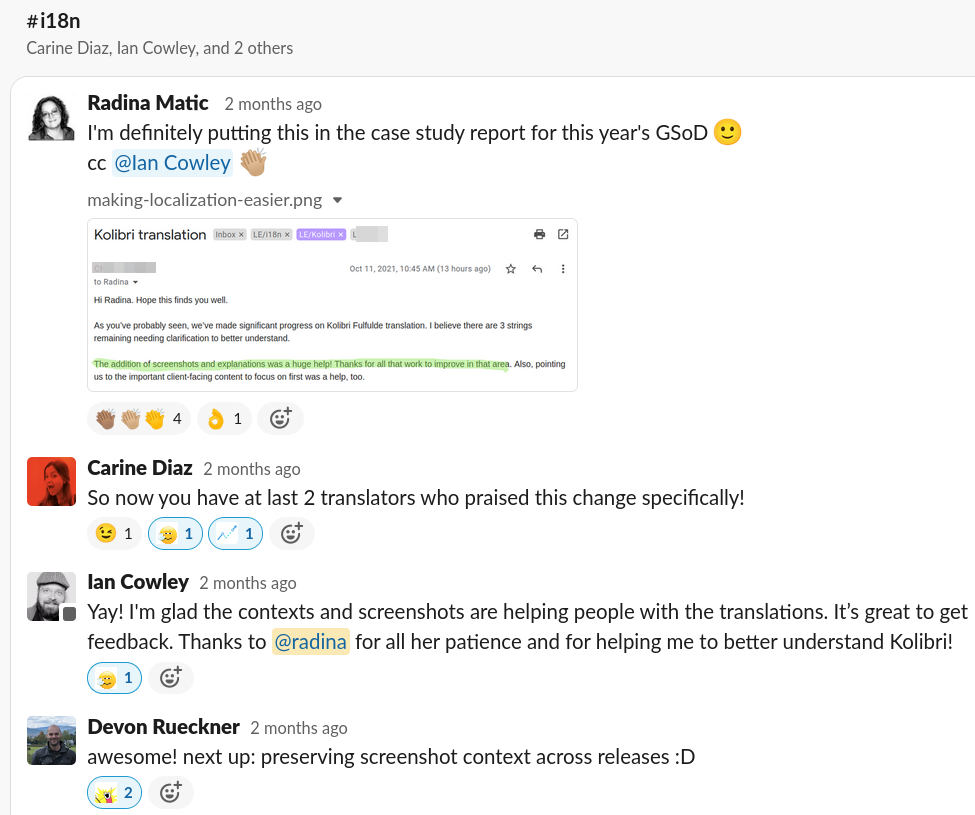
Keys to successful participation in the Season of Docs program according to the LE experience:
- Wide team buy-in around the proposed writing tasks that will address a real problem or an unmet project need. This will ensure strong team support and help easier transitions in case a team or community member designated as a primary PoC has to step down unexpectedly.
- Putting diversity upfront in the selection process! Make a point of using:
- inclusive language in your project job descriptions, communications and interviews
- targeted positive action to encourage candidates from under-represented backgrounds to apply
- branch out beyond the obvious places to share the project and job descriptions
- Making the project expectations, tasks, stages and outcomes crystally clear both during the selection process, and the docs development phases. In the several years that LE has been participating in GSoD and GSoC programs, we found that all candidates, whether developers or writers, benefit from and are grateful for having a clear and comprehensive onboarding/guidelines documentation, and a centralized channel for the information exchange.
- It has been said many times, but worth repeating: make the writer feel like a member of the community! Invite them to the relevant communication channels, stand-up, full team meetings and gatherings (time zones permitting), and always offer attentive and timely support whenever it is sought.
Acknowledgments
Learning Equality team thanks Ian Cowley for the time, patience and enthusiasm while contributing to Kolibri during the 2021 Season of Docs program.
The LE team is grateful to all community code contributors, translation volunteers and partners. Thanks to all of them, the new Kolibri 0.15 will be flying in 27 languages!
Google Season of Docs 2021 Case Study
