24 AI SUPPORT OF EVALUATION IN PLANNING
The necessity of information technology assistance
A planning discourse support platform aiming at accommodating projects that cannot be handled by small face-to-face ‘teams’ or deliberation bodies, must use advanced information technology, if only just to handle communication among participating parties. Also, the examination of evaluation in the planning discourse has shown that thorough deliberation and evaluation can become so complex that information technology assistance will become absolutely necessary, whether in the form of simple data management or more sophisticated AI, ‘Artificial Intelligence‘ or ‘Augmented Intelligence’.
What role can or should AI tools play in the evaluation functions of such a platform? It may be useful, as a first step, to distinguish between the simpler data management (‘house-keeping’) aspects of such a system, ‘research’ tasks, and more ambitious ‘analysis’ AI functions, based on whether or how much the tools are involving thinking and judgments: understanding and especially evaluation judgments. Can the former (‘housekeeping’) be seen as having little or no direct bearing on the latter -- and thus not creating much in the way of controversy? This raises serious questions about the proper boundary between human judgment and (a perception of) substituting machine calculations for judgments that should be seen as human prerogative and responsibility. This study – an individual effort without external funding that could not draw on AI expertise, will just be able to raise some questions and considerations based on some of the less familiar insights of the evaluation exploration – using the proposed rough distinction.
‘House-keeping’ tasks
File maintenance.
A first ‘simple’ data management task will of course be to receive and store contributions to the discourse, for record-keeping, retrieval and reference. This will apply to all entries, in formal professional or scientific form or contributions in conversational language, depending on the nature of the project being discussed. The contributions may be stored for reference, in simple chronological order as they are entered, with date and author information. A separate file will keep track of authors and cross-reference them with entries and other actions. A log of activities will also be needed.
‘Ordered’ or ‘formatted’ files.
For a meaningfully orchestrated evaluation in the discourse, it will be necessary to sort the entries, for example according to issues, proposals, arguments, factual information, and to check for and eliminate duplication of essential the same information, perhaps already in some formatted manner, and to keep the resulting files updated. This may already involve some ‘translation’ (from disciplinary jargon into conversational language) as well as formatting the content of ‘verbatim’ entries. This may already be seen as crossing the border between mere ‘house-keeping’ and more sophisticated ‘analysis’.
Preparation of displays of ‘maps’ and diagrams
The provision of visual ‘maps’, diagrams, and graphics is important for participants to gain and keep an overview of the discourse process. This will involve displays of ‘candidates’ for decision, the resulting agenda of accepted candidates; topic and issue maps of the evolving discussion, evaluation and decision results and statistics, as well as systems diagrams. Some such material will be provided by participants (in the form of expert reports that habitually contain diagrams and graphs, and of course in disciplinary language). Should the platform offer such overview and translation services for non-expert participants, or will gaining that understanding be a participant responsibility?
Preparation of evaluation worksheets
Most evaluation techniques involve ‘worksheets’ for entering judgments – aspect lists, weights, performance quality or plausibility scores that must be provided by the support functions of the platform.
Tabulating, aggregating evaluation results for statistics and displays
The judgment results of evaluation procedures will have to be processed: tabulated, aggregated, and statistical results prepared and presented according to the requirements of the technique that has been agreed upon by a project participant group.
‘Research’ tasks
This important aspect is an area where most information technology advances have already been achieved and are constantly evolving. A simple distinction of different ‘research tasks is that between
a) Finding answers to discourse questions in data bases of existing documented information, (‘re-search’): searching for available pertinent information already documented, using information technology tools (‘googling’) is by now a common expectation; and
b) Using observation technology to ‘search’ and find new data not yet collected and documented. This may require actual research, observation, measurement, collection and presentation of data that are not yet documented.
Both tasks are complicated by the growth of databases that use different ‘storage’ methodologies as well as languages both natural and technical ‘jargon’, and of the organizations involved in actually carrying out the collection of new data. The use and interpretation of the data for the discourse may be more adequately described as ‘analysis’ in the following:
‘Analysis’ tasks
Translation
Verbatim entries submitted in different languages, as well as their formatted content will have to be translated into the natural languages of all participants. Also, entries expressed in ‘discipline jargon’ will have to be translated into conversational language. Translation algorithms used for cc subtitles of videos, TV shows and the like are becoming common expectations, but are still imperfect and the output of current tools must be checked for distortions of meaning. Improved tools for discipline jargon translation into conversational language will be needed for a fully functional platform. This will also include the task of checking contributions for duplication (that was listed above as ‘housekeeping’ but will need more sophisticated support for entries that express the same content in different language, discipline jargon, and vocabulary.
Analysis of new or researched data
Data collected by actual research investigation (‘new’ data) must be examined and interpreted by statistical analysis tools for validity and significance, providing evidence or support for claims in the discourse, but increasingly also for their potential of exhibiting patterns of coherence to suggest or generate new hypotheses that can help solve problems – in other words, potentially play a role in planning arguments. Likewise, the discovery of logical inferences or inconsistencies of claims in chains of inferences in the Knowledge Bases of documented information; the identification of conflicting support claims that is not in quantitative form but just postulated relationships of cause-effect or association appears to need better tools, especially when deontic claims are involved.
Construction of plans, arguments, and other discourse elements
There seem to be considerable expectations about the potential of AI to actually become a constructive party in the planning discourse. It seems plausible that algorithms given the data about problems, existing regulations and technological knowledge will be able to construct ‘solution proposals’. In a sense, every simulation model can be seen as doing just that: Any intervention on a ‘leverage point in the model produces a ‘solution’ consisting of the values of every variable in the model.
AI role in ‘generating’ arguments
A more detailed example is the possibility of machine construction of ‘planning arguments’ from information in the knowledge bases: Finding (thus far unrelated, separate) claims of the kinds of premises of such arguments: “Whenever actions of type A are done in situations C, they will have effect B”; ‘Effects B are desirable, ought to be pursued’; and “The current state of affairs includes conditions C” can obviously be combined into the argument: “A ought to be implemented because A will produce B in conditions C; B ought to be pursued; and conditions C are present”.
The boundary between artificial, even ‘augmented’ and human judgment?
The important question for all such possibilities is the evaluation of the produced solutions, resulting in decisions. The current tendency to accept a solution that ‘maximizes’ some selected system variable (declared to represent as a goal or as ‘the purpose’ of the system) ignores the human valuation judgments (and potential disagreements): As has become clear in the examples of evaluation approaches, the variable(s) to be used as decision criteria will have to be aggregated from the subjective evaluation judgments of human participants. For the algorithm (as well as any human decision-maker) to claim to make decisions ‘on behalf of’ others, it will have to demonstrate that the decision results from the evaluation process that other humans would have been using.
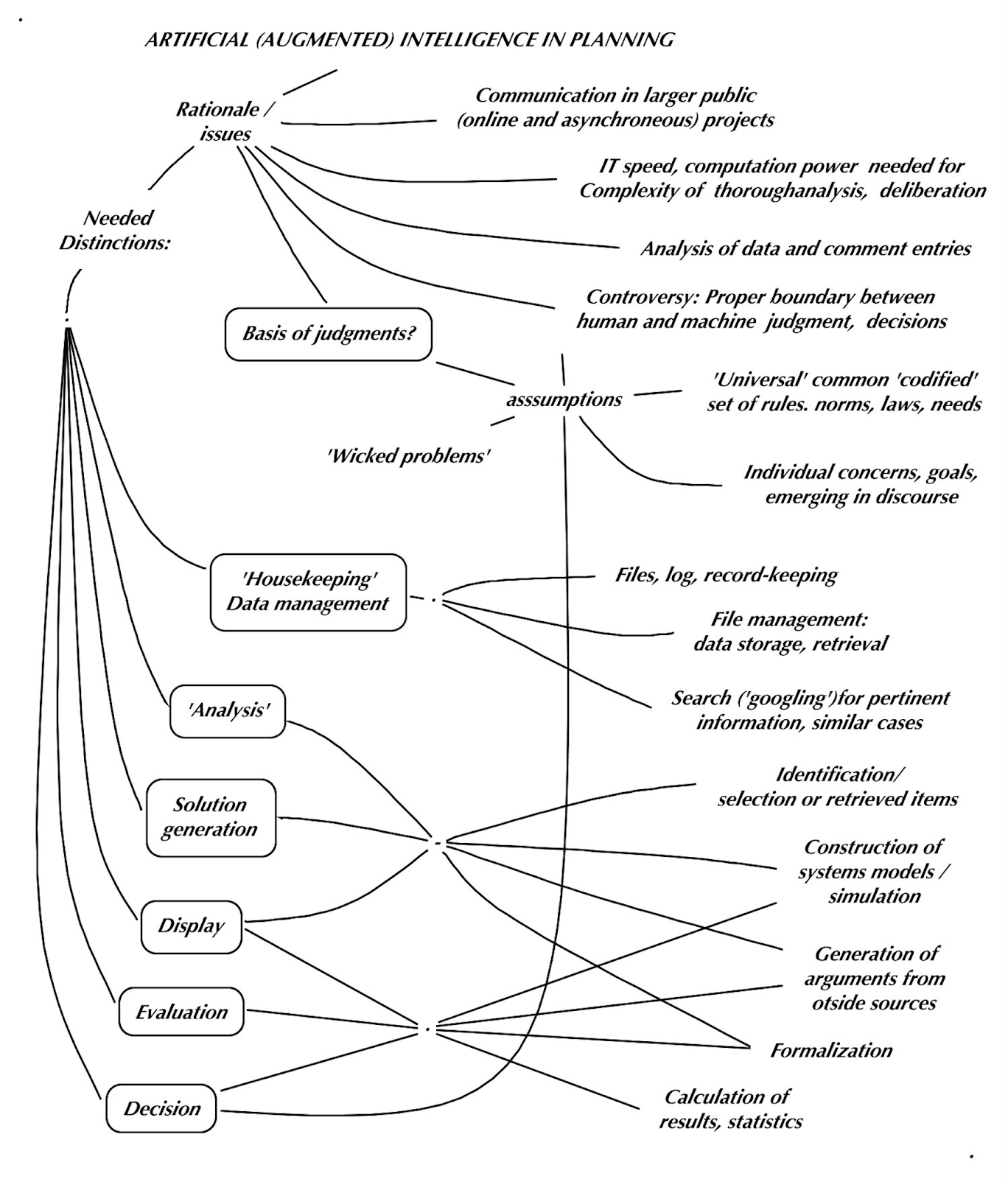
Figure 23 - 1 Artificial (augmented) intelligence in planning evaluation
Decision making tasks
The last item in this sketchy exploration of AI involvement in the planning discourse points at the critical question of human versus machine judgments that support and legitimize planning decisions. The quest to develop such tools -- to exploit the amazing capability of machines to pursue complex goals in rapidly moving circumstances (and evasive targets – rests on some controversial assumptions. One such assumption is that the basis of human judgments for which plans are needed can be adequately described and stated in the algorithms. This would be possible given further assumptions: Either, it would call for the humans in question to describe and explain their basis of judgment in sufficient detail to allow it to be coded into the algorithm. Or that it would be possible to find, determine, and describe what the community or society as a whole ‘ought’ to pursue as its “Common Good”, overriding any individual ‘mere opinions’, and express its aspects in the algorithm as accepted ‘rules’ ‘laws’, regulations. The basis of this alternative would be a theory held to embody this set of laws, -- held by an entity with sufficient power to impose and enforce it. This implies overriding any differing opinions, concerns, and corresponding judgments of part of the community. The community can of course agree to such arrangements (constitutional tenets) thereby making decisions ‘legitimate’ – but at the expense of the principle of decisions based on the (judged, evaluated) merit of the information contributed. Such agreements can of course become the operating rules of decision-making algorithms. Should they be pursued?
At this point it becomes clear that algorithms designed and allowed to make decisions become political instruments. AI planning decisions will be decisions ‘on behalf’ of humans – individuals or groups, communities. As the study tries to make clear, the validity of claims of one decision-making entity to decide on behalf of another entity (‘as the other would have decided’) rests on the demonstration that the decision is indeed based on the other’s judgment basis. Several ways of describing a person’s judgment basis have been explored. One common denominator was the distinction between performance criteria of plans and the human ‘good/bad’ (‘quality’) judgments about those. Another finding was that collective ‘quality’ judgment ‘decision indicators’ or guides must be based on some collectively accepted aggregation functions of individual judgments. The choice between different ‘indicators’ to become decision criteria for the actual decisions -- that may include other general (e.g. political) considerations – is another decision that arguably should be made and agreed upon by humans involved in the respective projects, not algorithms.
What this second view (of universal basis of judgment representing the entire community) is missing is the basic fact that we argue about plans with the expectation that our mutual comments will actually influence, change our basis of judgment: that we can learn from others’ information and concerns, and ultimately change what we initially held to be the obviously right decision. Our basis of judgment changes during the discourse. Will it be possible for AI tools to actually follow discussions and continually and correctly update their models of all participants’ basis of judgment, to be able to claim to justly compute its decision recommendations ‘on behalf’ of the community?
AI and ‘Wicked Problems’
It is useful in this connection to review Rittel’s list of properties of ‘wicked problems’ [1] ‘WP’s – for example the fact that planning problems are not ‘correct or false’ but good or bad; that they have unique features (information and questions not yet covered in documented Knowledge Base information); that there are no finite sets of permissible (‘legal’) operations for developing solutions for WP’s, or that there is no ‘stopping rule’ inherent in the problem. The latter alone would be contrary to any understanding of an algorithm (A sequence of steps leading from an initial statement to a final ‘Stop’ output): Would an AI algorithm have to keep running (“we can always do better, find a better solution”…) until stopped by a problem-extraneous intervention ( e.g. ‘time’s up’) that humans always use to stop working?
The questions whether AI programs can be developed to meet these requirements, can only be raised and suggested for discussion, but not decided by this study. But perhaps the stated difficulties can be used to examine whether a given AI program falls short, and human decision-making should take over.
References, Notes
[1] Rittel, H. and M. Webber: “Dilemmas in a General Theory of Planning: Policy Sciences #4, 1973.
Properties of WP’s: see ‘Wicked Problem’ in the ‘Glossary’ section.
A review of the implications of Wicked Problems for Public Planning is in preparation. (T. Mann)
-- o –