Object Detection Networks on Convolutional Feature Maps (2016)
작성일자 : 20200416
INTRODUCTION
- Faster R-CNN(ResNet) + new network

1.1. A prevalent strategy for object detection
- region-independent features 추출 → classification을 위하여, ROI pooling 후 region-wise multi-layer perceptrons (MLPs) 또는 fully connected (fc) layers에 통과
- MLP classifiers 끝나는 전형적인 pre-trained classification architectures(AlexNet, VGGNets)와 유사함
1.2. Networks on Convolutional feature maps (NoCs)
- region-wise classifier architectures
ABLATION EXPERIMENTS
3.1. Using MLP as NoC

- NoC : fc layer만 사용
- 2~4개의 fc layer 실험
- pre-training 없음
- last fc layer는 (n+1)-d softmax, 나머지 fc layer는 4096-d (+ReLU)
- 3fc layer 구조는 SPPNet, Fast/Faster R-CNN(region-wise)과 유사함
3.2. Using ConvNet as NoC

- 1~3개의 conv layer (+ReLU) 실험
- VOC 07 trainval set는 데이터량이 작아서, deeper model 학습 힘듬(VOC 07+12 trainval set도 실험)
- 성능 하락은 overfitting의 결과
- 3개 layer를 추가하였을때 성능이 가장 좋음
3.3. Maxout for Scale Selection (From Maxout to Maxout NoC)
- Maxout

- “Maxout Networks”(2013)
- purple-pink : Maxout Network
- activation functions으로 사용
- 입력값의 최대값을 출력하고, 이로 인하여 자연스럽게 dropout 효과를 얻음
- maxout feature map : k-affine feature maps 최대값을 사용하여 구성
- Maxout NoC


- two feature maps (for the two scales)은 element-wise max를 사용하여, single feature으로 병합
- Maxout전 두개의 feature map은 공유됨
- 4 variants of Maxout better
- alternative ways to merge two feature maps
- Simply element-wise added together
- Concatenation with/without L2 normalization, then 1×1 convolution to reduce the dimension just like U-Net or ParseNet
- element-wise multiplication just like DSSD
3.4. Other Analyses for NoC
- Fine-Tuning

- VGG-16 and fc layers in the pre-trained model
- additional conv layers initialized to the identity mapping
- initial network state is equivalent to the pre-trained three fc structure
- Error Analysis

- The localization error is substantially reduced
- Localization-sensitive information is only extracted after RoI pooling
Results of NoC for Faster R-CNN With ResNet / GoogLeNet
4.1. MS COCO

- Faster R-CNN With ResNet or GoogLeNet
- ResNet-101 (feature map enlarged by hole algorithm) feature extracted at res4b22(=ConvNet as NoC (res5a,5b,5c,fc81)) : 27.2%
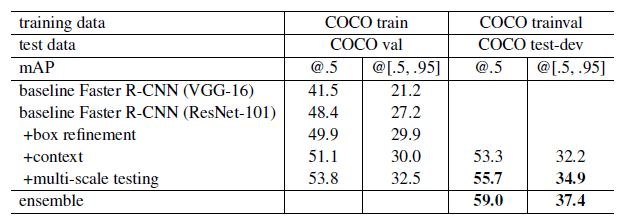
- Box Refinement(inference) : regressed box, new classification score, new regressed box로부터 새로운 feature를 pooling
- Global Context : full-image conv feature map에서 global Spatial Pyramid Pooling(“single-level SPPNet”) 후 original per-region feature과 합병함
- Multi-Scale Testing(train) : conv feature maps을 image pyramid로 생성시 짧은축이 {200, 400, 600, 800, 1000} 범위를 갖음. 2개의 인접한 스케일(= selected pyramid)는 ROI-pooled 후 Maxout(merge)
- Ensemble : ensemble of 3 networks, 37.4% mAP(test-dev set 포함)
4.2. PASCAL VOC


- COCO dataset + PASCAL VOC sets(=fine-tuned)
- “baseline+++” : Box Refinement, Global Context, and Multi-Scale Testing 포함 (No ensembling, only single model, 6.1 상승)
4.3. ILSVRC Detection (DET) Task
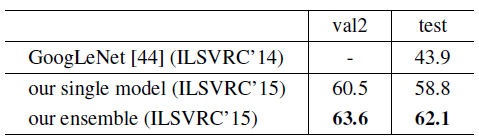
- pre-trained on the 1000-class ImageNet classification + DET data(=fine-tuned)
- Box Refinement, Global Context, and Multi-Scale Testing 사용(= single model)
ETC
정리할것 : hole algorithm
참고