Status Report: Cloud Computing Activities
October 2017 - March 2018
Julien Chastang, Ward Fisher, Michael James, Ryan May, Jen Oxelson, Mohan Ramamurthy, Christian Ward-Garrison, Jeff Weber, Tom Yoksas
Areas for Committee Feedback
We are requesting your feedback on the following topics:
- What clouds are our community using, either commercial (e.g., Amazon) or non-for-profit (e.g., NSF XSEDE Jetstream)?
- What new cloud technologies are our community using and investigating on their own initiative?
- Who would like to volunteer to beta test CloudIDV?
- Who would like to volunteer to beta test: https://jupyter-jetstream.unidata.ucar.edu
Activities Since the Last Status Report
Updates to NEXRAD in AWS
Two separate requests were received from the community (NCAR, Oklahoma) to enhance the AWS Simple Notification Service topic for the realtime (i.e., individual chunk) S3 bucket. The goal was to allow users to utilize message filters in order to only subscribe for a subset of the data; for example to only request data for a particular site or sites. Ryan May worked with AWS and NCAR to prototype a new topic, and the new AWS API calls have been added and deployed to the AWS NEXRAD processing software.
Serverless Experiment
Ryan May has begun experimenting with so-called “serverless” cloud technology. The idea with “serverless” is that, instead of managing a virtual machine running in the cloud, various other cloud infrastructure services are leveraged to create an application that runs in an event-driven fashion, without the need for a VM that is idle much of the time; for simple applications, this can represent significant cost savings over running a compute instance. As a concrete example, AWS provides API Gateway as a service for routing web requests and Lambda as a service for running code (e.g. Python, Java). Using these services, Ryan has put together a web application (for syncing GitHub issues to the Asana project management tool) that requires no continuously running server. Ryan plans to continue to explore this space as a way for creating simple, scalable web services running affordably in the commercial cloud.
Unidata Science Gateway on Jetstream
Building upon our previous containerization efforts, we are continuing to enhance the Unidata Science Gateway on NSF-funded XSEDE Jetstream Cloud: http://science-gateway.unidata.ucar.edu/. A collection of Unidata related technologies can be found here for our community to make use of directly or with client applications such as the IDV. The following resources are available on this gateway:
- An experimental JupyterHub server containing Unidata Jupyter notebook projects (see Python status report for more information).
- A TDS supplying a good portion of the data available on the IDD with a five day archive.
- EDEX server
- RAMADDA containing IDV bundles that retrieve data from Jetstream data servers.
- Two LDM nodes
- ADDE Server
- IDV Jetstream plugin that allows easy access to Jetstream installations of the TDS, RAMADDA and ADDE from the IDV.
Gateway users, coupled with XSEDE HPC resources, can achieve complete end-to-end scientific computing workflows. In the past six months, we have done three presentations on this work:
- Gateways 2017 | October 23–25, 2017 – Ann Arbor, MI USA
- 2017 AGU Fall Meeting | December 11–15, 2017 – New Orleans, LA USA
- 2018 AMS Annual Meeting | January 7–11, 2018 – Austin, TX USA
A complete bibliography of this effort is available here.
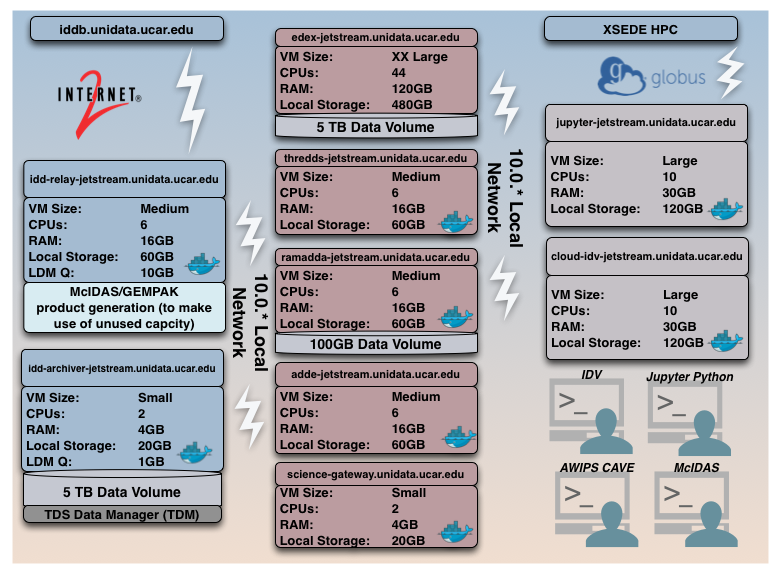
Dependencies, challenges, problems, and risks include:
- We would like to transition from an experimental and research and development approach, to an operational mode. To achieve this objective, we are working with the Jetstream team to improve VM uptime availability. To that end, Unidata has ameliorated its monitoring of Jetstream VMs so that we have accurate metrics concerning VM availability that we can communicate to the Jetstream team.
- Unidata software staff continues to work closely with Unidata system administrators to ensure cloud VMs (especially on Jetstream) are adhering to Unidata security standards.
AWIPS EDEX in the Cloud
Unidata continues to maintain an EDEX data server on the Jetstream cloud, serving real-time AWIPS data to CAVE clients and through the python-awips data access framework (API). The distributed architectural concepts of AWIPS allow us to easily scale EDEX in the cloud to account for the size of incoming data feeds. By isolating the database/request processes to a single machine, we avoid data serving competing with data decoding on the same machine, minimizing the chance of reaching system memory limits which can result in EDEX shutdown.
We continue work using Jetstream to develop cloud-deployable AWIPS instances, both as imaged virtual machines (VMIs) available to users of Atmosphere and OpenStack, and as docker containers available on Docker Hub and deployable (soon) with the xsede-jetstream toolset.
Jetstream AWIPS EDEX Standalone VMI
This EDEX image can serve either as a full standalone server or as a database/request server.
Jetstream AWIPS EDEX Ingest Node VMI
This image contains all AWIPS Python and EDEX software, but nothing database or http-related. This VMI makes it easy to deploy datatype-specific ingest nodes (Grid, Radar, Satellite, etc.) with simple edits to ldmd.conf and modes-ingest.xml
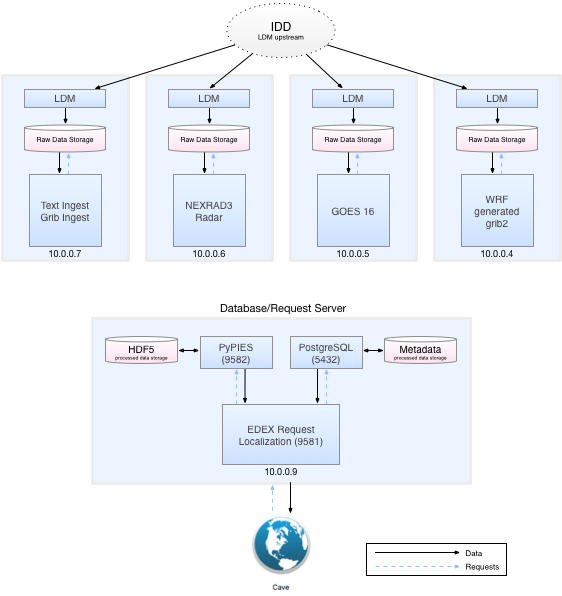
Nexus Server on Jetstream
Unidata continues to run a Nexus Server on Jetstream for the distribution of netCDF-Java artifacts (e.g., netcdfAll.jar, toolsUI.jar, ncIdv.jar): https://artifacts.unidata.ucar.edu. netCDF-Java documentation is also hosted at that location.
On February 26, 2018, the VM that hosts this server experienced a 12 hour downtime due to a Jetstream network issue. We are working with Jetstream staff to avoid these lengthy downtimes in the future.
Preparing for Renewal of Research Allocation on Jetstream
Unidata is preparing to renew its Research allocation starting on March 15, 2018. Our current $425,000 allocation in cloud computing resources is on schedule to be totally consumed by June 30, 2018. We plan on requesting an allocation of equal or greater size to the original allocation.
Docker Containerization of Unidata Technology
We continue to employ Docker container technology to streamline building, deploying, and running Unidata technology offerings in cloud-based environments. Specifically, we are refining and improving Docker images for the IDV, LDM, ADDE, RAMADDA, THREDDS, AWIPS, and Python with Unidata Technologies. In addition, we also maintain a security-hardened Unidata Tomcat container inherited by the RAMADDA and THREDDS containers. Independently, this Tomcat container has gained use in the geoscience community.
Unidata / NOAA Docker Collaborations
We have been collaborating with NOAA in two different containerization efforts:
- We have been advising Evan Polster on Docker technology and the containerization of AWIPS and the LDM.
- We recently worked with Marcus England on use of the LDM Docker container. Marcus found several problems with this container that we were able to quickly resolve. We thank Marcus for reporting these problems so that we can improve these containers.
Progress has been made on the following:
Unix permission issues have been a long-standing problem with Docker technology with permission “mismatches” involving the user running the container, and the non-root user inside the container. These issues resulted in frequent and frustrating “permission denied” errors in situations where a directory on the Docker host was mounted in the container. We recently made significant progress in this area by allowing the user running the container to supply a Unix user ID and group ID to the container thereby allowing the user inside the container to effectively be the same as the user running the container. The end result is permission problems of this type are now resolved with this new technique. This amelioration is implemented in most Unidata Docker containers.
Dependencies, challenges, problems, and risks include:
It is unlikely that most of our community will use these containers directly. Rather they will be leveraged by experts on behalf of the community, or they will be abstracted from users by being integrated into a user-friendly workflow. For example, on Jetstream we have a JupyterHub server currently in development: https://jupyter-jetstream.unidata.ucar.edu. This server was deployed with the aid of cloud computing technologies including Docker. These details, however, are hidden from the user.
In addition, there are overlapping (perhaps, competing or complementary) technologies such as Ansible that are emerging alongside Docker that need to be investigated.
Ongoing Activities
Amazon Web Service Activities and NOAA Big Data Project
NOAA Big Data Project
- In collaboration with Unidata, NOAA is delivering 20+ years of NEXRAD Level II data via Amazon Web Services. LDM and THREDDS Data Server (TDS) software are being employed to deliver these data.
- Started transferring GOES-16 data to the Amazon cloud S3 bucket.
- TDS on AWS for level II NEXRAD (For .edu access only): http://thredds-aws.unidata.ucar.edu/thredds/catalog.html
- AWS Explorer (Public access): https://s3.amazonaws.com/noaa-nexrad-level2/index.html
- Public Bucket for level II NEXRAD: https://noaa-nexrad-level2.s3.amazonaws.com
- Continue to populate the NEXRAD level II archive with real time data.
- Continue to populate new GFS .25 degree output and NCEP HRRR output to an S3 bucket for access. We did not place a TDS on this collection as this output is available from our standard sources.
- Unidata continues to get requests from other UCAR/NCAR groups, to partner and lend assistance in cloud computing, especially in the AWS cloud.
Product Generation for IDD
For the past three years, Unidata generated products for the IDD, FNEXRAD and UNIWISC data streams have been created by a VM hosted in the Amazon cloud. This production generation has been proceeding very smoothly with almost no intervention from Unidata staff.
CloudIDV, CloudStream, Cloud Control
- We have released the technology enabling CloudIDV in a form that can be easily leveraged by other projects looking to bring legacy software to the Cloud. We are currently trying to build the CloudStream community via conference presentations and outreach.
- In addition, we continue to experiment with CloudIDV on the Jetstream Cloud. We are investigating CloudIDV for data-proximate visualization of the WRF-hydro modeling system.
- We presented at both AGU 2017 and AMS 2018 on CloudIDV and CloudStream.
Open Commons Consortium Award
The Open Science Data Cloud, a resource of the Open Commons Consortium (OCC), provides the scientific community with resources for storing, sharing, and analyzing terabyte and petabyte-scale scientific datasets. The OSDC is a data science ecosystem in which researchers can house and share their own scientific data, access complimentary public datasets, build and share customized virtual machines with whatever tools necessary to analyze their data, and perform the analysis to answer their research questions. Unidata is a beta user of resources in the Open Science Data Cloud ecosystem and we have been provided cloud-computing resources on the Griffin cloud platform. Our allocations are renewed on a quarterly basis and Unidata is partnering with OCC on the NOAA Big Data Project. Given the limited staff resources and many ongoing cloud activities on AWS, Azure, and XSEDE environments, Unidata’s activities on the OSDC have been in a temporary hiatus. We are hoping to ramp up our OSDC efforts in the upcoming months.
New Activities
Over the next three months, we plan to organize or take part in the following:
Unidata Science Gateway
Forthcoming Presentations
- EGU General Assembly 2018 | April 8–13, 2018 - Vienna, Austria
- PEARC 18 | July 22-27, 2018 - Pittsburgh, PA USA
Over the next twelve months, we plan to organize or take part in the following:
Unidata Science Gateway
We would like to promote and advertise the science gateway (http://science-gateway.unidata.ucar.edu/) to our community.
Beyond a one-year timeframe, we plan to organize or take part in the following:
Unidata Transitioning to the Cloud
In the long-term, we would like to explore the possibility of migrating some core Unidata services onto the cloud.
Relevant Metrics
Docker image downloads are available from Unidata’s Dockerhub repository.
Strategic Focus Areas
We support the following goals described in Unidata Strategic Plan:
- Enable widespread, efficient access to geoscience data
Making Unidata data streams available via various commercial (e.g., Amazon) and not-for-profit (e.g., NSF XSEDE Jetstream) cloud services will allow our community to access data quickly and at low or even no cost. Moreover, our users can benefit from high data bandwidth capability provided by various cloud computing platforms, and in some cases, Internet2 capability. Lastly, cloud computing offers the possibility of accessing geoscience data in a "data-proximate" manner where users can perform analysis and visualization on, at times, unwieldy data sets next to where the data reside. - Develop and provide open-source tools for effective use of geoscience data
Containerization technology complements and enhances Unidata technology offerings in an open source manner. Unidata experts install, configure and in some cases, security harden Unidata software in containers defined by Dockerfiles. In turn, these containers can be easily deployed on cloud computing VMs by Unidata staff or community members that may have access to cloud-computing resources. Unidata staff develop Docker containers in an open-source manner by employing software carpentry best-practices and distributed version control technology such as git. - Provide cyberinfrastructure leadership in data discovery, access, and use
Unidata is uniquely positioned in our community to experiment with cloud computing technology in the areas of data discovery, access, and use. Our efforts to determine the most efficient ways to make use of cloud resources will allow community members to forego at least some of the early, exploratory steps toward full use of cloud environments. - Build, support, and advocate for the diverse geoscience community
Transitioning Unidata technology to a cloud computing environment will increase data availability to new audiences thereby creating new and diverse geoscience communities.
Prepared March 2018