Headers
!pip3 install pycaret
{"pip_warning":{"packages":["numpy"]}}
from pycaret.utils import enable_colab
enable_colab()
Colab mode enabled.
import numpy as np
import pandas as pd
from google.colab import drive
import matplotlib.pyplot as plt
from sklearn import metrics
%matplotlib inline
from matplotlib.pylab import rcParams
import seaborn as sns
import warnings
import itertools
import os, gc, io
warnings.filterwarnings("ignore") # specify to ignore warning messages
<IPython.core.display.HTML object>
from google.colab import drive
drive.mount('/content/drive')
<IPython.core.display.HTML object>
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
Recording name
rec_name= "207"
<IPython.core.display.HTML object>
Loading data
from os.path import join
def txt2csv(file_path, save_dir):
"""
Converts MIT-BIH dataset .txt files to .csv which more readable with pandas
:param file_path: .txt file path
:param save_dir: Converted file save directory
:return: Saves .csv file near to .txt file's location
"""
headers = _txt_header_extract(file_path)
rows = _txt_row_extracter(file_path)
df = pd.DataFrame(rows, columns=headers)
file_name = file_path.split(".")[0].split("/")[-1]
save_ext = ".csv"
save_file = f"{file_name}{save_ext}"
save_path = join(save_dir, save_file)
df.to_csv(save_path)
def _txt_header_extract(file_path):
"""
Gets headers from .txt file
:param file_path: .txt file path
:return: Header list
"""
with open(file_path, "r") as txt_file:
txt = txt_file.readline()
row = txt.split("\n")
hdr = " ".join(row[0].split()).split(" ")
hdr.remove("#")
return hdr
def _txt_row_extracter(file_path):
"""
Retrieves and corrects the information on the rows
:param file_path: .txt file path
:return: Data rows
"""
with open(file_path, "r") as txt_file:
txt = txt_file.read()
row = txt.split("\n")
info = []
for index, r in enumerate(row[1:-1]):
i = " ".join(r.split()).split(" ")
if len(i) != 7:
i.append("")
info.append(np.array(i))
return np.array(info)
#txt2csv('/content/drive/MyDrive/Arrhythmia/'+rec_name+'annotations.txt', '/content/drive/MyDrive/Arrhythmia')
txt2csv('/content/drive/MyDrive/'+rec_name+'annotations.txt', '/content/drive/MyDrive')
<IPython.core.display.HTML object>
#df=pd.read_csv('/content/drive/MyDrive/Arrhythmia/'+rec_name+'annotations.csv')
df=pd.read_csv('/content/drive/MyDrive/'+rec_name+'annotations.csv')
df.tail(10)
<IPython.core.display.HTML object>
Unnamed: 0 Time Sample Type Sub Chan Num Aux
2375 2375 30:00.461 648166 A 0 0 0 NaN
2376 2376 30:00.989 648356 A 0 0 0 NaN
2377 2377 30:01.517 648546 A 0 0 0 NaN
2378 2378 30:02.025 648729 A 0 0 0 NaN
2379 2379 30:02.497 648899 A 0 0 0 NaN
2380 2380 30:03.003 649081 A 0 0 0 NaN
2381 2381 30:03.506 649262 A 0 0 0 NaN
2382 2382 30:03.975 649431 A 0 0 0 NaN
2383 2383 30:04.450 649602 A 0 0 0 NaN
2384 2384 30:04.997 649799 A 0 0 0 NaN
#record=pd.read_csv('/content/drive/MyDrive/Arrhythmia/'+rec_name+'.csv' ,header=0, names= ['Sample', 'MLII' ,'V5'])
record=pd.read_csv('/content/drive/MyDrive/'+rec_name+'.csv' ,header=0, names= ['Sample', 'MLII' ,'V5'])
record.head(3)
<IPython.core.display.HTML object>
Sample MLII V5
0 0 981 1043
1 1 981 1043
2 2 981 1043
data= df.iloc[:, 1:5]
<IPython.core.display.HTML object>
print(len(data))
<IPython.core.display.HTML object>
2385
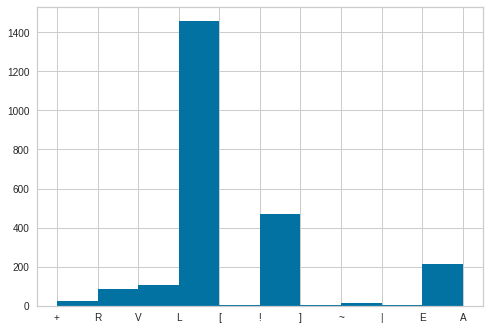
values , counts = np.unique(data['Type'], return_counts=True)
for v,c in zip(values,counts):
print(v,c)
<IPython.core.display.HTML object>
! 472
+ 24
A 107
E 105
L 1457
R 86
V 105
[ 6
] 6
| 2
~ 15
data['Type'].hist()
plt.show()
<IPython.core.display.HTML object>
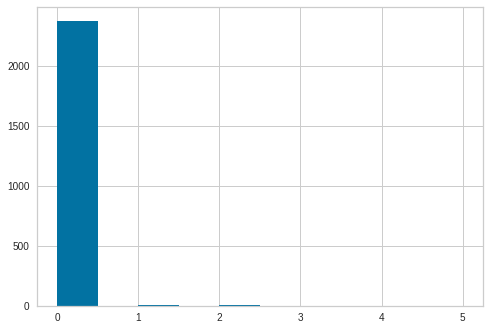
values , counts = np.unique(data['Sub'], return_counts=True)
for v,c in zip(values,counts):
print(v,c)
<IPython.core.display.HTML object>
0 2372
1 6
2 4
3 2
5 1
data['Sub'].hist()
plt.show()
<IPython.core.display.HTML object>
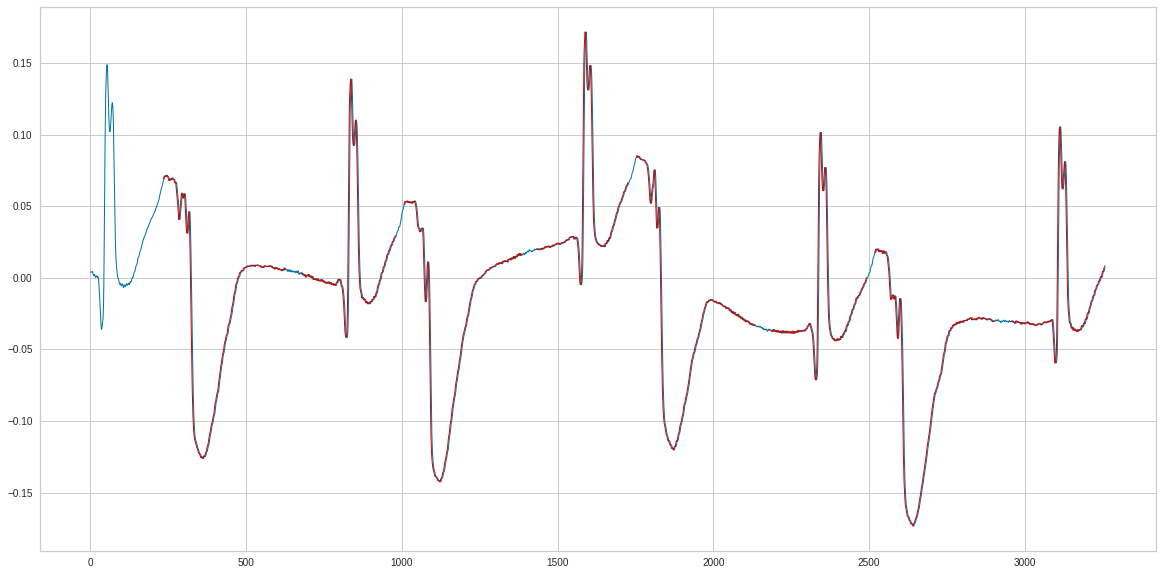
plt.rcParams["figure.figsize"] = (20,10)
plt.rcParams['lines.linewidth'] = 1
plt.rcParams['lines.color'] = 'b'
plt.rcParams['axes.grid'] = True
<IPython.core.display.HTML object>
PLOT
x=record['V5']
nhb=10 #number of heartbeats
lhb=300 #average length of a heartbeat
start=0
end=nhb*lhb
X=x[start:end].values
ecg=(X)
ecg=np.transpose(ecg)
fs=360 #1 sec of signal
ts=1/fs
t=np.linspace(0, np.size(ecg), np.size(ecg))
times=t*ts
where = df['Sample'].values <end
samp = df['Sample'].values[where]
types = np.array(df['Type'].values)
types = types[where]
plt.plot(t, ecg)
for it, sam in enumerate(samp):
# Get the annotation position
xa = t[sam]
ya = ecg.max()
# Use just the first letter
a_txt = types[it]
plt.annotate(a_txt, xy = (xa, ya), fontsize=16)
plt.xlabel('Sample [n]', fontsize=16)
plt.show()
<IPython.core.display.HTML object>
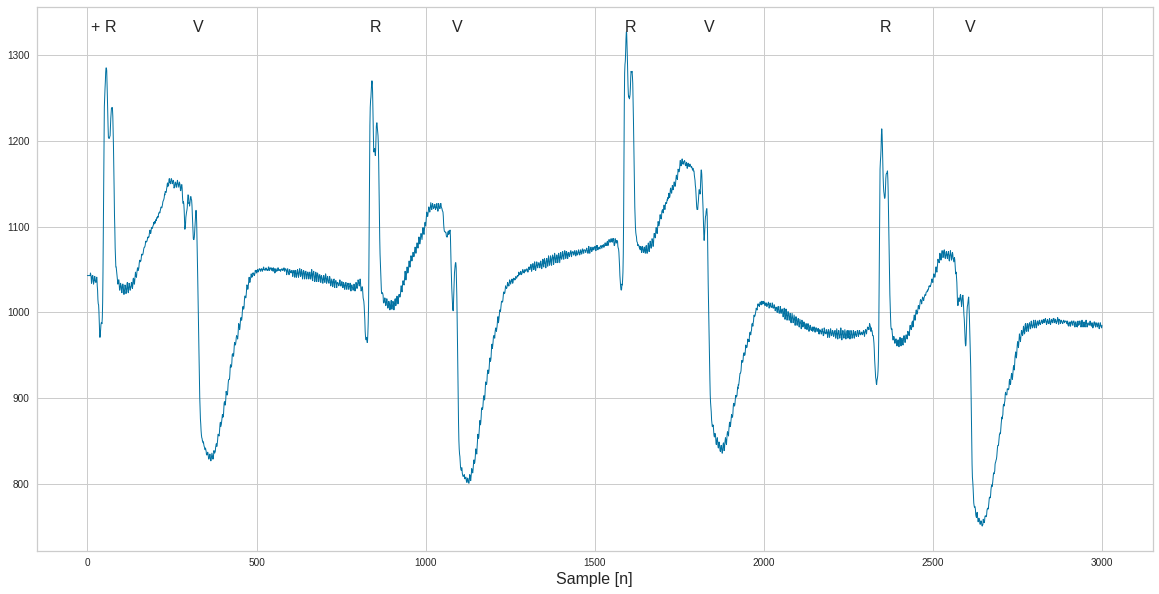
where = df['Sample'].values <end
samp = df['Sample'].values[where]
types = np.array(df['Sub'].values)
types = types[where]
plt.plot(times, ecg)
for it, sam in enumerate(samp):
# Get the annotation position
xa = times[sam]
ya = ecg.max()
# Use just the first letter
a_txt = types[it]
plt.annotate(a_txt, xy = (xa, ya), fontsize=16)
plt.xlabel('Time [s]', fontsize=16)
plt.show()
<IPython.core.display.HTML object>
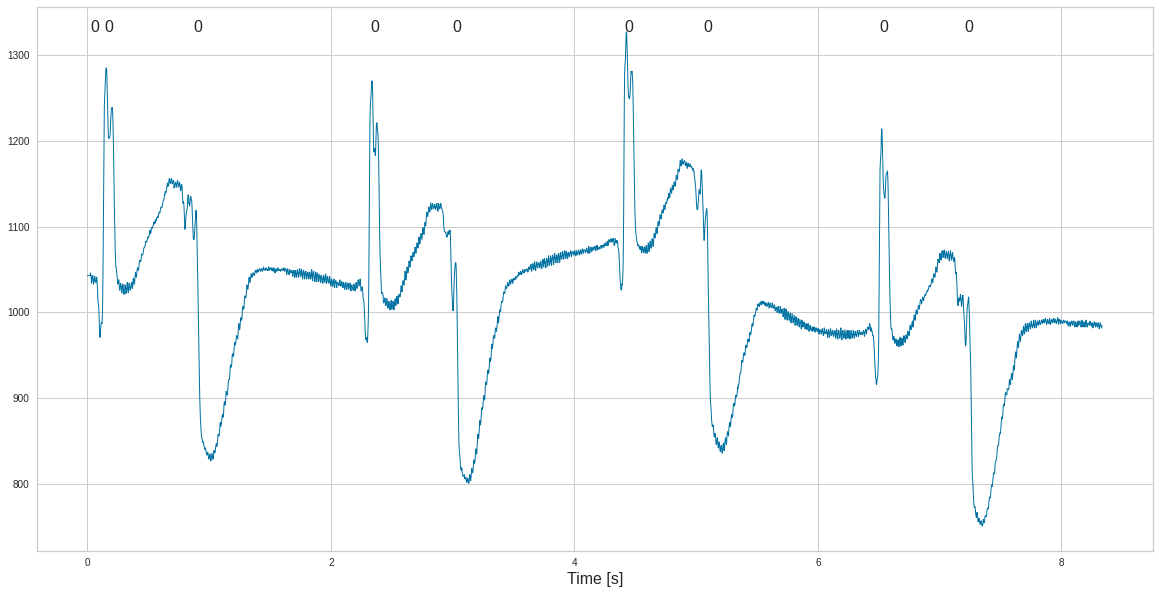
Pre-processing
d_ecg= pd.merge(record, df, on='Sample', how='left' )
d_ecg = d_ecg.drop(columns=[ 'Unnamed: 0' ,'Sub', 'Chan', 'Num' , 'Aux','Time'])
d_ecg.head(5)
<IPython.core.display.HTML object>
Sample MLII V5 Type
0 0 981 1043 NaN
1 1 981 1043 NaN
2 2 981 1043 NaN
3 3 981 1043 NaN
4 4 981 1043 NaN
_columns = d_ecg.columns[d_ecg.isnull().sum()/len(d_ecg)*100 > 1]
_columns
<IPython.core.display.HTML object>
Index(['Type'], dtype='object')
for c in _columns:
d_ecg[c] = d_ecg[c].bfill()
d_ecg.head()
<IPython.core.display.HTML object>
Sample MLII V5 Type
0 0 981 1043 +
1 1 981 1043 +
2 2 981 1043 +
3 3 981 1043 +
4 4 981 1043 +
d_ecg= d_ecg.dropna()
<IPython.core.display.HTML object>
Normalization
d_ecg['V5n'] = (d_ecg['V5'] -d_ecg['V5'].mean() )/ abs(d_ecg['V5'] ).max()
<IPython.core.display.HTML object>
fs=360
ts=1/fs
nhb=10 #number of heartbeats
lhb=300 #average length of a heartbeat
start=0
end=nhb*lhb
n=d_ecg['V5n'][start:end].values
ecg=(n)
ecg=np.transpose(ecg)
t=np.linspace(0, np.size(n), np.size(n))
times=t*ts
plt.plot(times, ecg)
plt.show()
print(ecg)
<IPython.core.display.HTML object>
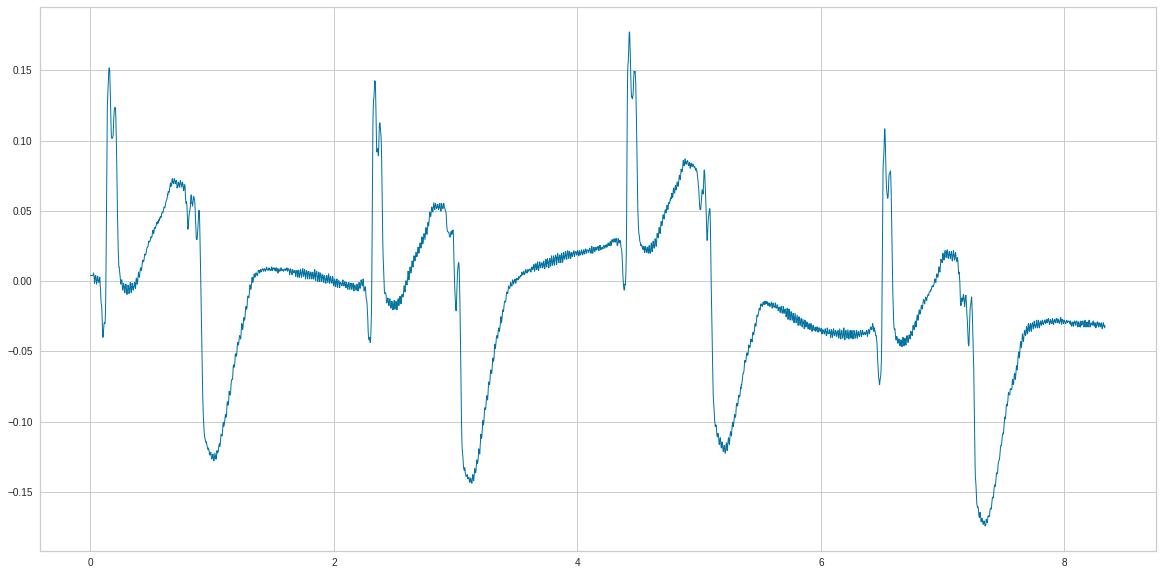
[ 0.00398848 0.00398848 0.00398848 ... -0.03266394 -0.03327481
-0.03144219]
Filtering
nhb=10 #number of heartbeats
lhb=300 #average length of a heartbeat
start=0
end=nhb*lhb
d_ecg['V5f'] = d_ecg['V5n'] .rolling(window=5).mean()
n=d_ecg['V5f'][start:end].values
ecg=(n)
ecg=np.transpose(ecg)
t=np.linspace(0, np.size(n), np.size(n))
times=t*ts
plt.plot(times, ecg)
<IPython.core.display.HTML object>
[<matplotlib.lines.Line2D at 0x7fbb72109610>]
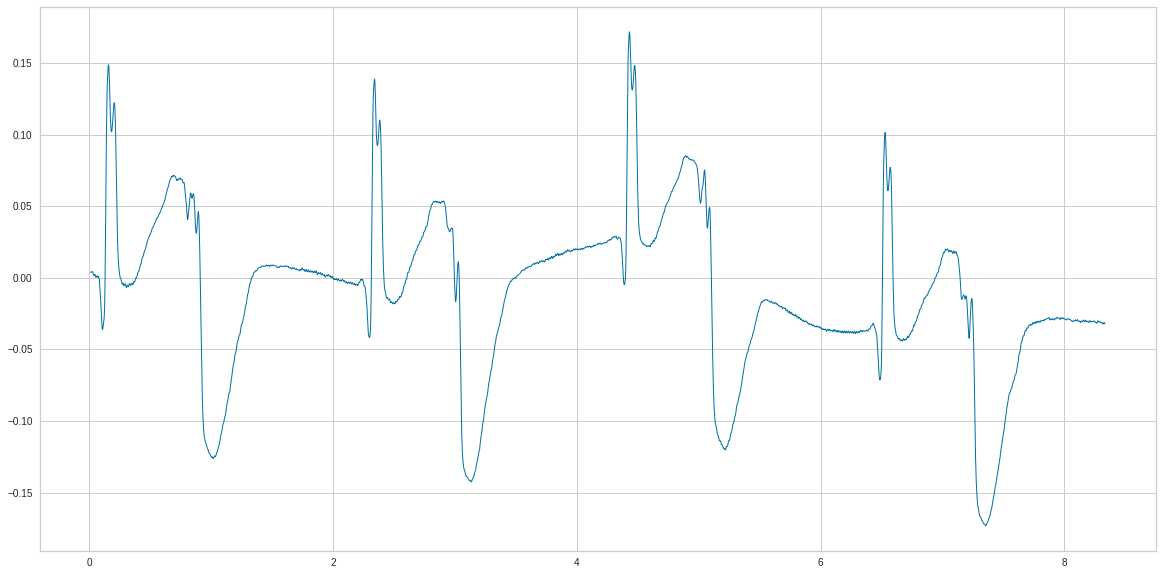
print(ecg[0:10])
<IPython.core.display.HTML object>
[ nan nan nan nan 0.00398848 0.00398848
0.00398848 0.00398848 0.00398848 0.004355 ]
print(ecg[2250:2274])
<IPython.core.display.HTML object>
[-0.03840615 -0.03840615 -0.03803962 -0.03755092 -0.03779527 -0.0381618
-0.03877267 -0.03840615 -0.03791745 -0.0371844 -0.03742875 -0.03791745
-0.0386505 -0.03889485 -0.03840615 -0.03755092 -0.03742875 -0.03779527
-0.0381618 -0.03840615 -0.03828397 -0.03779527 -0.03742875 -0.03755092]
Segmentation
Segmentation of heartbeats
peaks = df['Sample'].values
print(peaks)
<IPython.core.display.HTML object>
[ 9 50 312 ... 649431 649602 649799]
len(peaks)
<IPython.core.display.HTML object>
2385
n=10
start=0
end=peaks[n]
n1= d_ecg['V5n'][start:end].values
ecg=(n1)
ecg=np.transpose(ecg)
x= peaks[0:n]
y= np.ones(n)*(ecg.max())
plt.stem(x, y , 'r')
plt.plot(ecg)
plt.show()
<IPython.core.display.HTML object>
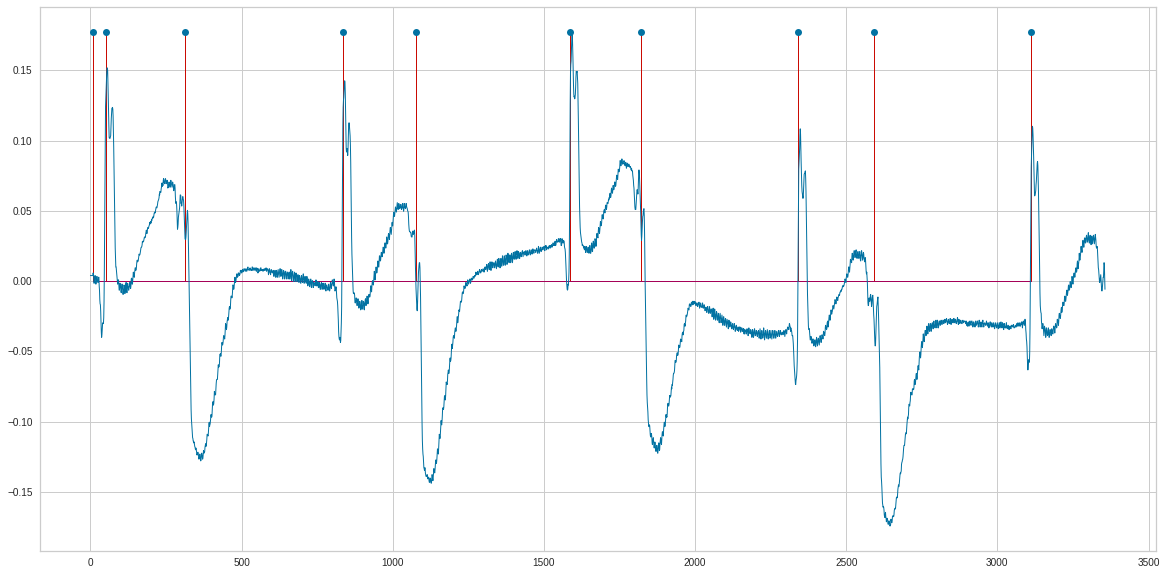
d_ecg.shape
<IPython.core.display.HTML object>
(649800, 6)
f= d_ecg['V5f'].dropna()
<IPython.core.display.HTML object>
from scipy import signal
d_ecg['V5fr'] = signal.resample(f, len(d_ecg['V5n']))
<IPython.core.display.HTML object>
n=10
start=3
end=peaks[n]
n1= d_ecg['V5fr'][start:end].values
ecg=(n1)
ecg=np.transpose(ecg)
x= peaks[0:n]
y= np.ones(n)*(ecg.max())
plt.stem(x, y , 'r')
plt.plot(ecg)
plt.show()
<IPython.core.display.HTML object>
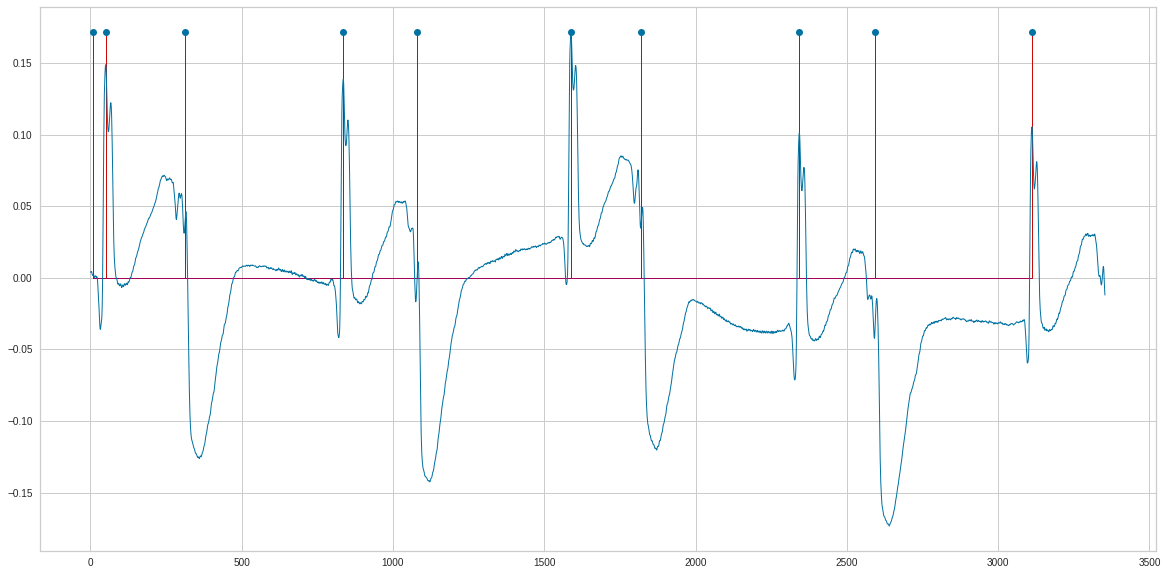
print(peaks[0:100])
<IPython.core.display.HTML object>
[ 9 50 312 835 1078 1588 1821 2342 2593 3111 3357 3857
4092 4637 4889 5409 5648 6160 6408 6939 7191 7700 7937 8437
8694 9215 9463 9949 10196 10689 10939 11450 11699 12197 12436 12936
13200 13348 13717 13868 13967 14125 14263 14414 14522 14665 14689 14894
15018 15138 15258 15387 15519 15642 15759 15906 16015 16138 16262 16383
16496 16611 16710 16822 16936 17055 17218 17346 17509 17618 17730 17857
17976 18132 18256 18350 18396 18825 19070 19579 19715 19760 19836 19964
20077 20183 20297 20402 20521 20640 20748 20851 20962 21092 21183 21315
21432 21608 21731 21827]
L1=[]
for i in range(2,len(peaks)-2):
b= peaks[i]
a= peaks[i-1]
c=b-int(abs(0.3*(b-a)))
L1.append(c)
<IPython.core.display.HTML object>
len(L1)
<IPython.core.display.HTML object>
2381
L2=[]
for i in range(2,len(peaks)-2):
b= peaks[i]
a= peaks[i+1]
c=int(abs(0.6*(a-b)))+b
L2.append(c)
<IPython.core.display.HTML object>
len(L2)
<IPython.core.display.HTML object>
2381
hb = []
for i in range(0, len(L1)):
hb.append(ecg[(L1[i]):(L2[i])])
<IPython.core.display.HTML object>
n=8
start=0
end=L2[n-1]
n1= d_ecg['V5fr'][start:end].values
ecg=(n1)
ecg=np.transpose(ecg)
plt.plot(ecg)
for i in range(0, n):
plt.plot(range(L1[i],L2[i]),hb[i], 'r')
plt.show()
<IPython.core.display.HTML object>