Neural Machine Translation with Attention
Tác giả: Từ Nghĩa
Trong bài viết này mình sẽ trình bày quá trình xây dựng mạng neural sequence to sequence kết hợp với Bidirectional cho bài toán dịch thuật (machine translation) với cơ chế attention. Dữ liệu mẫu được sử dụng trong viết này là các cặp câu Anh-Việt. Kết quả ứng dụng là chương trình dịch thuật với đầu vào một câu tiếng Anh, đầu ra là câu tiếng Việt dịch được tương ứng (link demo: https://omomega.com/ombot/translate/ ). Quá trình xây dựng mô hình được thực hiện trên thư viện Tensorflow >= 2.0.
Giới thiệu
Quá trình thực hiện:
1) Chuẩn bị dữ liệu (cặp các câu Eng-Viet).
2) Xây dựng model Sequence to Sequence.
3) Xây dựng module training.
4) Áp dụng cơ chế Attention của Bahdanau.
4.1) Cơ chế Attention của Bahdanau.
4.2) Cơ chế Attention của Thang Luong.
Một số bài viết có thể đọc trước:
+ Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Network. NIPS, 2014. link
+ Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. EMNLP, 2014. link
+ Thang Luong, Hieu Pham, Chris Manning. Effective Approaches to Attention-based. Neural Machine Translation. EMNLP, 2015. Link
1. Chuẩn bị dữ liệu
Dữ liệu cặp câu cho bài toán dịch thuật của các ngôn ngữ phổ biến trong đó có Anh-Việt có thể download tại: http://www.manythings.org/anki/
Thực hiện chuẩn hóa, loại bỏ ký tự đặt biệt, stopword và tách từ cho tiếng Việt (quá trình thực hiện có thể tham khảo tại bài ‘Xử lý ngôn ngữ Tiếng Việt’ phần tiền xử lý.
Kết quả thực hiện sau chuẩn hóa:
Có thể download file đã chuẩn hóa tại đây: (en.txt, vi.txt)
Sau khi đã chuẩn hóa, thực hiện viết module load dữ liệu cho việc training.
+ Xây dựng class và khởi tạo thông số:
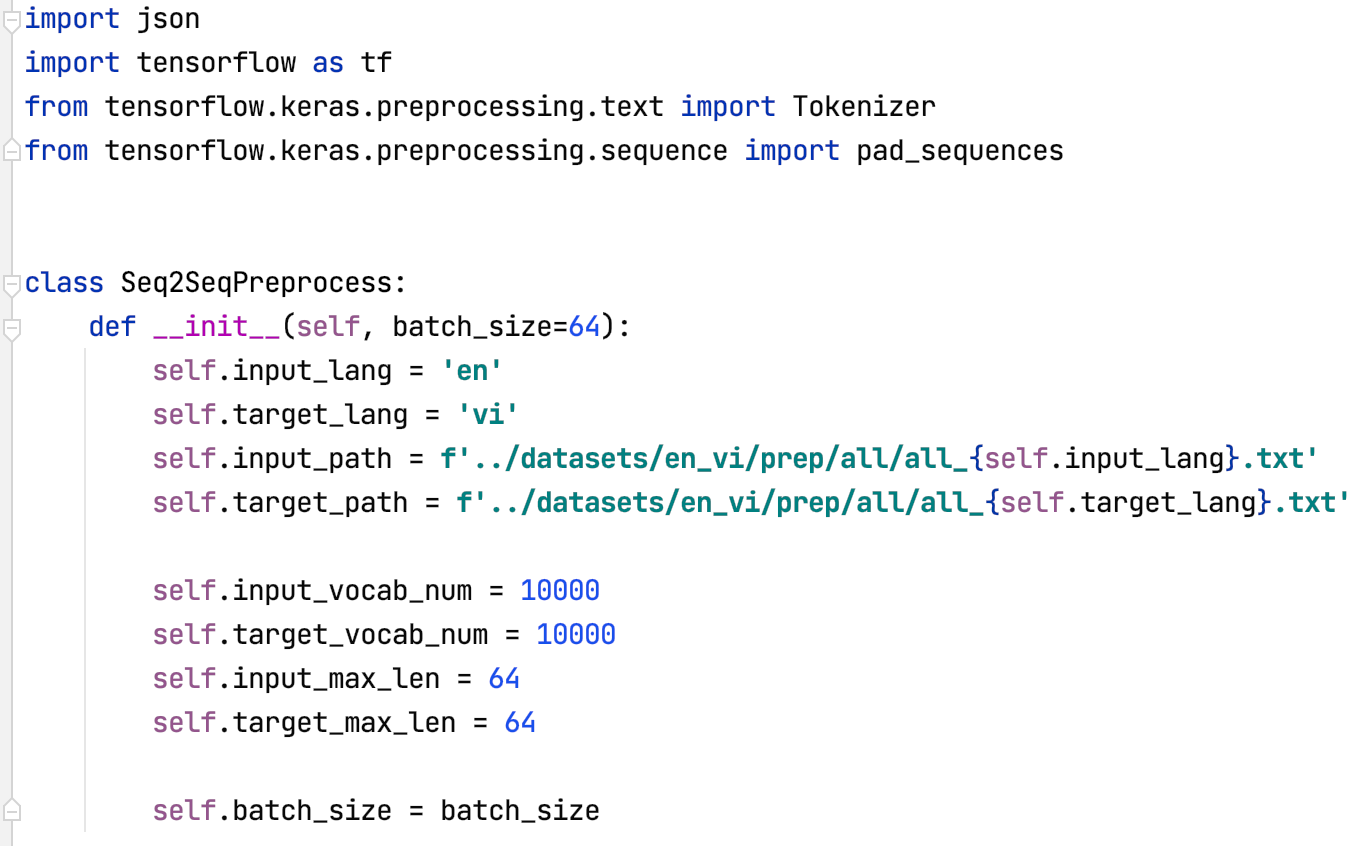
+ Phương thức đọc dữ liệu từ file txt. Thêm tokens ‘<start> ’ và ‘ <end>’ vào mỗi câu.

+ Phương thức chuyển đổi dữ liệu dạng text sang word index có fit size sử dụng module Tokenizer và pad_sequence của tensorflow.keras.preprocessing. Có thể lưu tokenizer theo dữ liệu dưới dạng json để sử dụng cho predict sau này.

+ Phương thức thực hiện đọc dữ liệu, tokenize và chuyển đổi sang dạng tf.data với X là tập các câu (word index) tiếng Anh, y là tập các câu (word index) tiếng Việt theo thứ tự tương ứng. Sau đó shuffle và phân batch để sẵn sàng cho việc training.

2. Xây dựng model Sequence to Sequence
Model sequence to sequence là model có dạng encoder-decoder:
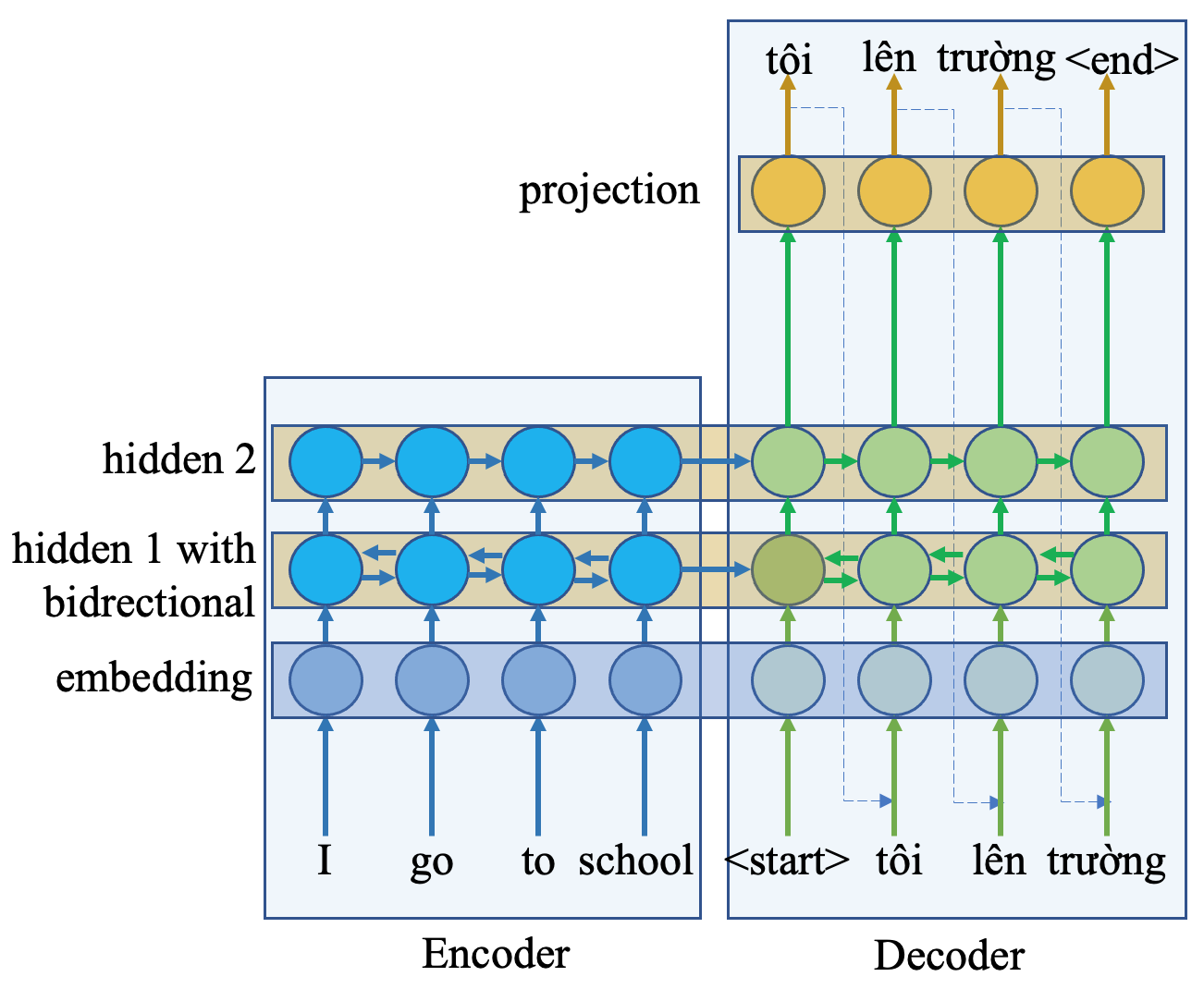
Thành phần chính cấu thành model là GRU (biến thể của RNN) có kết hợp thêm Bidirectional. Xem thêm bài viết RNN và các biến thể để có chi tiết về RNN, Bidirectional và cài đặt với tensorflow.
Xây dựng Encoder:
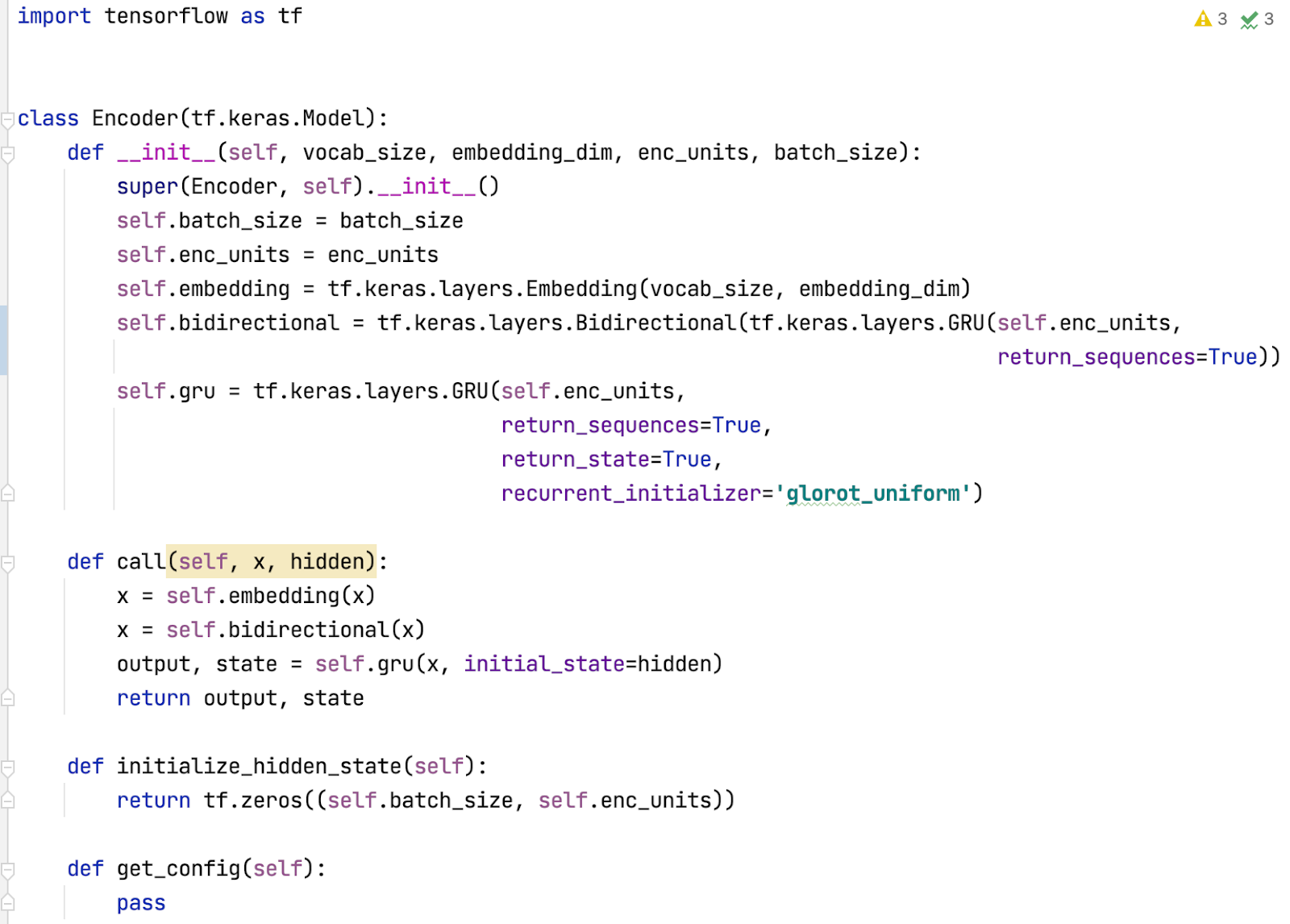
Decoder
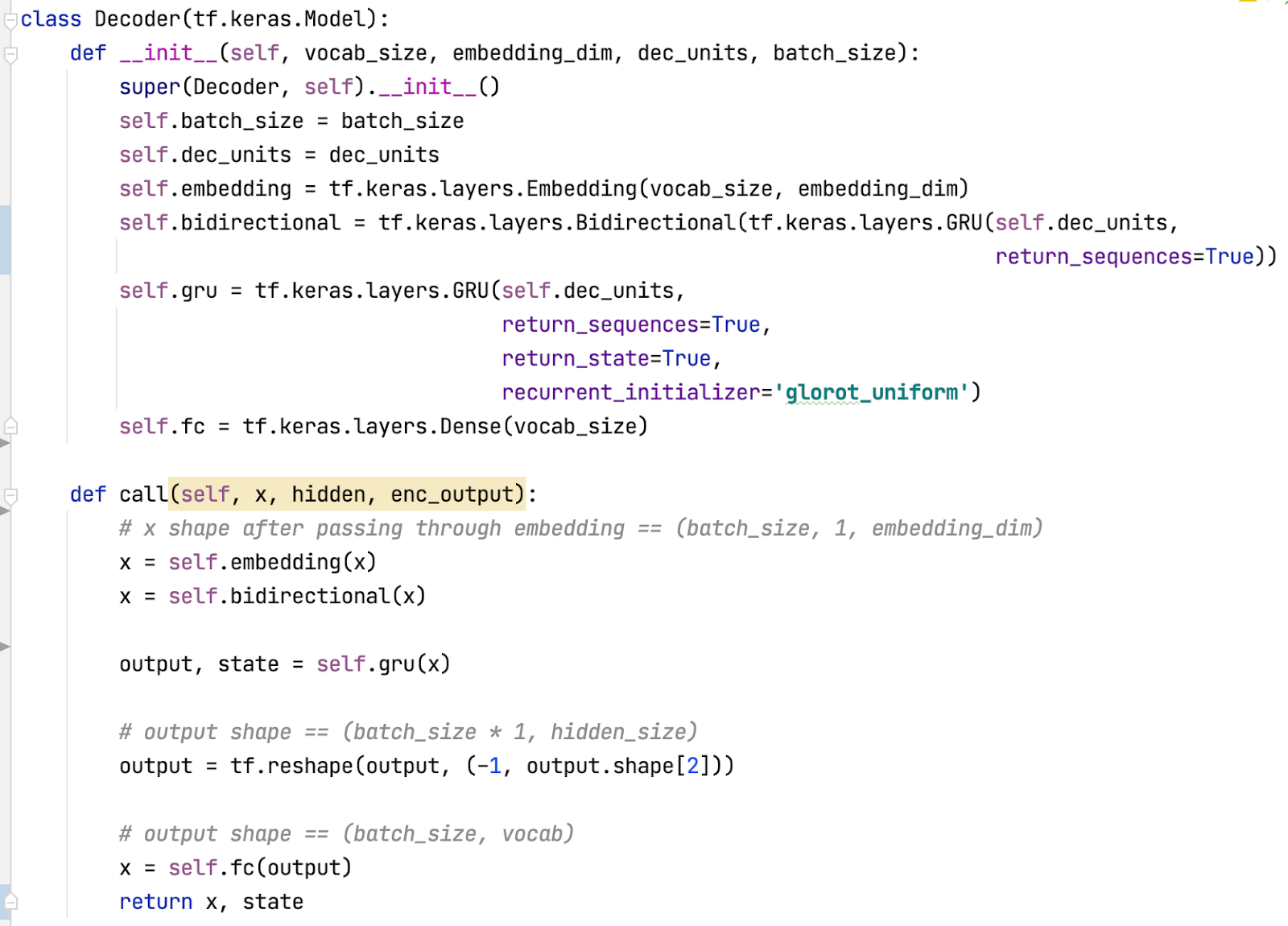
3. Xây dựng module training
Load dataset, khởi tạo model, hàm loss, hàm optimization:

Hàm tính loss

Hàm forward và backward

Hàm training
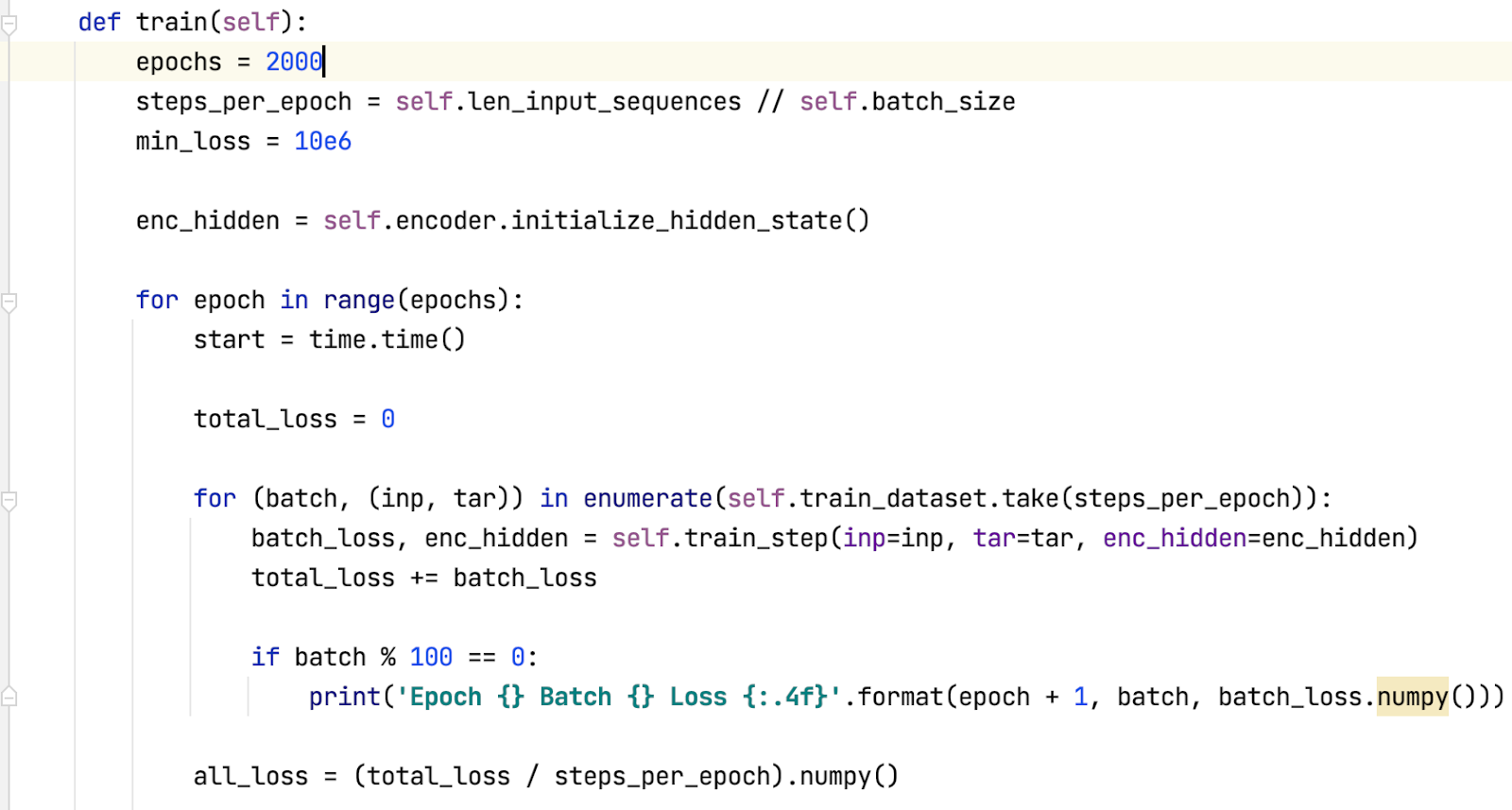
Lưu model có total loss thấp nhất:

4) Áp dụng cơ chế Attention.
Với mạng sequence to sequene với encoder-decoder có hạng chế là chỉ thông tin từ time step cuối của RNN encoder truyền sang decoder. Tuy RNN có sự phụ của time step cuối với các time step trước tuy nhiên dễ bị mất thông tin khi phụ thuộc xa.
Ý tưởng của cơ chế attention là mong muốn các time step của decoder có tất cả thông tin của encoder output thay vì chỉ là thông tin của time step cuối từ đó decoder chú ý thêm vào ngữ cảnh và hạng chế mất mát do phụ xa.
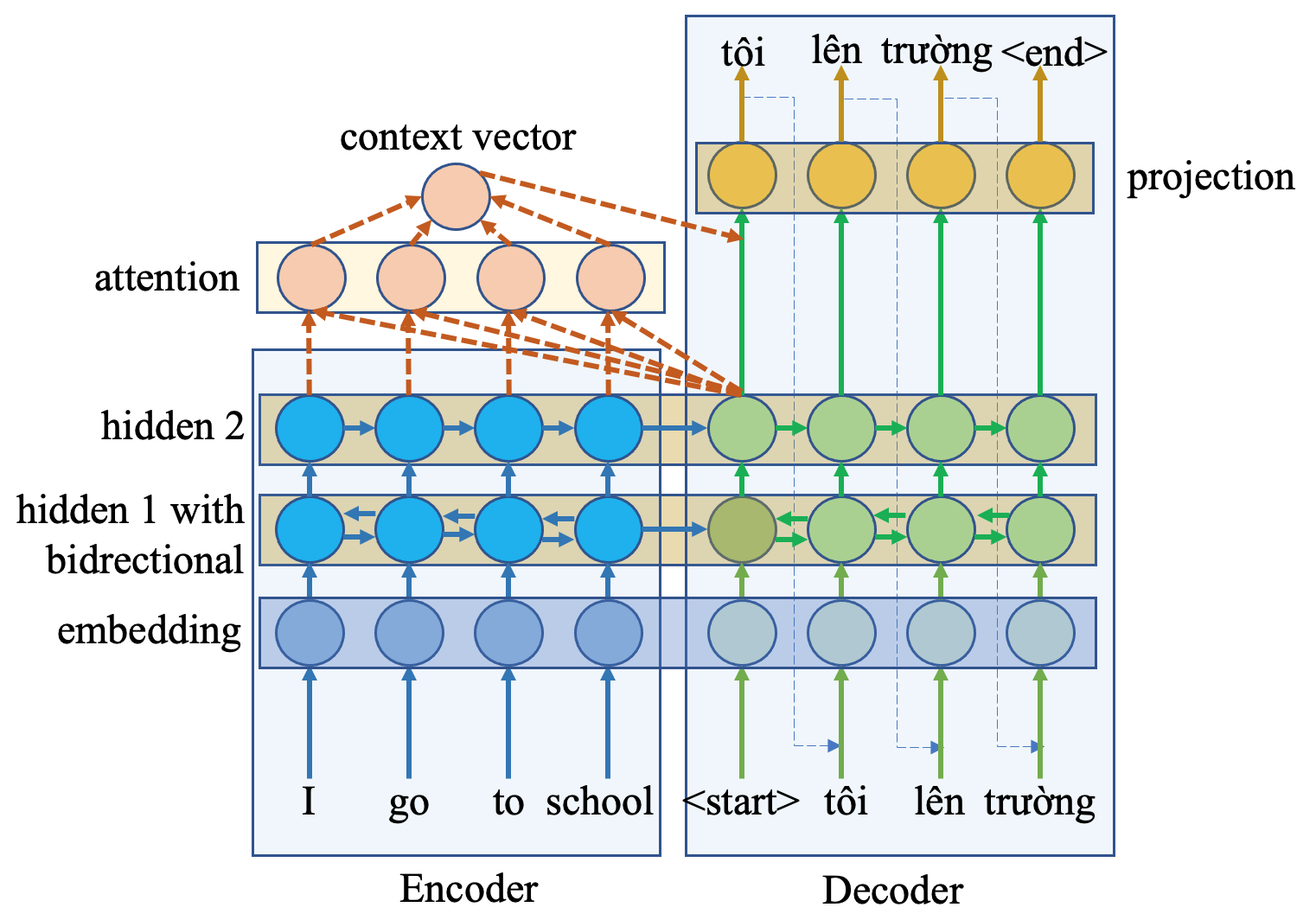
Cơ chế Attention được thực hiện:
Attention weights được tính từ hidden state của decoder ở step hiện tại với tất cả output state từ encoder để tăng cường tính phụ thuộc của step decoder hiện tại.
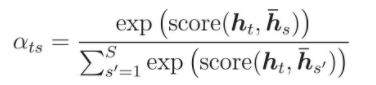
Hàm score được tính theo Luong hoặc Bahdanau như sau:
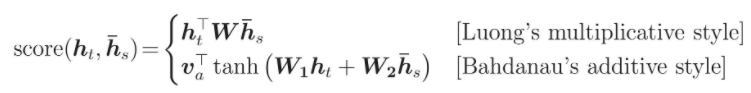
Context vector là trung bình của encoder output state weights với attention weights.
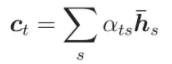
Vector attention được tính là output hàm activation của context vector với hidden state của decoder ở step hiện tại.
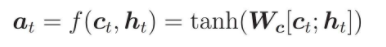
4.1) Cơ chế attention của Bahdanau.
Chi tiết cơ chế Attention của Bahdanau tại đây
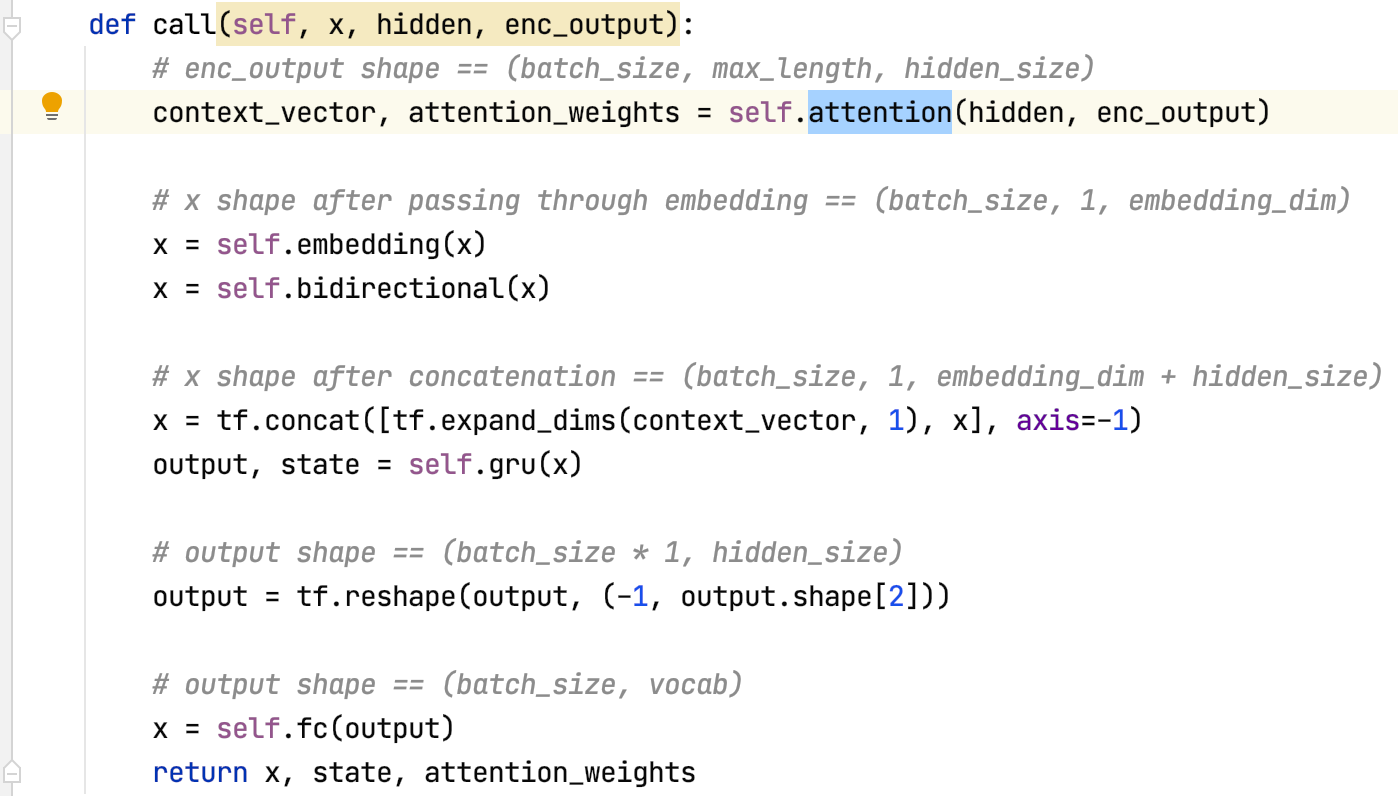
Module Bahdanau Attention

Thêm layer attention vào model

4.2) Cơ chế Attention của Thang Luong.
Chi tiết cơ chế attention của Thang Luong tại đây.

Tài liệu tham khảo
[1] Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Sequence to Sequence Learning with Neural Network. NIPS, 2014.
[2] Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. EMNLP, 2014.
[3] Dzmitry Bahdanau, KyungHyun Cho, Yoshua Bengio. Neural machine translation by jointly learning to align and translate. ICLR, 2015.
[4] Thang Luong, Hieu Pham, Chris Manning. Effective Approaches to Attention-based. Neural Machine Translation. EMNLP, 2015.
[5]https://www.tensorflow.org/tutorials/text/nmt_with_attention
[6]https://omomega.com/omdoc/article/python-voi-ml/d26--xu-ly-tieng-viet/26/
[7]https://omomega.com/omdoc/article/python-voi-ml/d27--rnn--text-classification/18/