Safer Usage Of C++
This document is PUBLIC. Chromium committers can comment on the original doc. If you want to comment but can’t, ping palmer@. Thanks for reading!
Google-internal short link: go/safer-cpp
Authors/Editors: adetaylor, palmer
Contributors: ajgo, danakj, davidben, dcheng, dmitrig, enh, jannh, jdoerrie, joenotcharles, kcc, markbrand, mmoroz, mpdenton, pkasting, rsesek, tsepez, awhalley, you!
Last updated: 2021-09-22
Status: Draft-o-rama | Review Frenzy | Gettin’ There | Donetacular
Introduction
Chrome Security has been asked to consider [Google-internal only, sorry] what it would take to make C++ less dangerous. This document outlines various mechanisms we could use to make it significantly easier to use C++ safely. Some are radical, and adopting them (especially adopting many of them) may result in code that looks quite different from what C++ programmers expect.
Most of the proposed mechanisms are new usage patterns, libraries, and classes, but some call for the use of compiler-specific flags that change the language somewhat. (For example, Chromium already uses -fno-exceptions, and here we propose -ftrapv, -fwrapv, or fsanitize=signed-integer-overflow.)
Some of these mechanisms are already being built in Chromium, with varying degrees of success. (Examples: The UAF-resistant smart pointer MiraclePtr is in performance trials, we have expanded the use of Oilpan to PDFium, and the hardening of //base, WTF, and Abseil is substantial and has proven effective.)
Other mechanisms we propose represent significant new directions for C++ and Chromium, and may even require new research and development into open problem areas (e.g. new forms of static analysis).
The C++ language and culture tend to trade off safety in favor of efficiency, and therefore many of these proposed changes are complex, controversial, and not as robust as similar changes might be in another language. Additionally, they might sometimes have micro- or even macro-efficiency effects (time, space, or object code size).
Prior Work
Safer C++ is a dream that many people share.
There is the C++ Core Guidelines project, and the Safe C++ Tool (and its SaferCPlusPlus library, and an auto-translation tool).
We don’t propose a new language, but e.g. CCured and Cyclone have been interesting previous efforts to make new flavors of C mostly compatible with existing C.
Also see an analysis of how memory tagging might change the safety situation.
Background
There are 2 basic types of memory safety: spatial safety and temporal safety. Spatial safety is the guarantee that the program will behave in a defined and safe way if it accesses memory outside valid bounds. Examples include array bounds, struct and union field access, and iterator access.
Temporal safety is the guarantee that the program will behave in a defined and safe way if it accesses memory when that memory is not valid at the time of the access. Examples include use after free (UAF), double-free, use before initialization, and use after move (UAM). Temporal safety violations often look like type confusion. For example, the program mistakenly uses a recently-freed Dog object as if it were a Cat object. (Attackers often build entirely fake objects with vtables that give them control of program execution.)
Of these 2 types of safety, spatial safety is relatively easier to achieve (with changes in Chromium code and/or by boxing a build target in WASM), albeit at some micro-cost to efficiency. (For example, you have to perform the array bounds check, which might cost more than not doing it. This is an entirely empirical question that can only be resolved in the context of a real program, and the results can be surprising.)
Temporal safety is more difficult to achieve and more expensive. Solutions include ubiquitous reference counting (e.g. Objective-C with ARC, Swift), banning shared mutable state and building a borrow-checker into the compiler (e.g. Rust), or fully generic garbage collection (e.g. Go, JavaScript, etc.).
We believe that, given sufficient tolerance for micro-efficiency regressions, we could essentially eliminate spatial unsafety in C++ in first-party code. We could do this (and have started doing so) with a combination of library changes and additions, compiler options, and policies/style rules and presubmit checks (including banned and encouraged classes and constructs). Keep in mind that while possible and usually relatively easily technically, this work is controversial in C++ communities (including Chromium).
We cannot marginalize or eliminate temporal unsafety in C++ without adopting one of the known solutions (such as GC). Micro-efficient and ergonomic temporal safety remains an open problem in software engineering. However, at some (potentially significant) cost to efficiency, we can reduce the prevalence and exploitability of temporal unsafety. *Scan is a promising possibility that we are experimenting with.
Undefined Behavior
Much of the problems of C/C++ come from undefined behavior (UB) built into the language and library specifications. (Even very recent language additions continue the tradition.) Spatial and temporal unsafety are sub-types of UB; other examples include signed integer overflow. Merely enumerating all the UB in C++ is an open project.
UB can be an opportunity for micro-optimization, although attackers see UB as an opportunity for exploitation.
For software that runs in an unpredictable and even hostile environment like the Internet, there is increasingly broad recognition that writing reliable and safe software in C/C++ is an extreme uphill battle due to the many safety- and ergonomics-relevant forms of UB.
Purpose Of This Document
Given this background, our goal in this document is to enumerate some likely projects Chromium contributors could, should, and might undertake to reduce the overall exploitable and un-ergonomic UB in Chromium’s usage of C++.
It is not possible to entirely ‘fix’ C++ without fundamentally redefining it. That is not our goal here. Instead, we want to identify and reduce some of the most persistent and impactful types of unsafe UB in Chromium’s usage.
Prioritization And Motivation
Here’s a guide to the relative importance of each of the solutions discussed in this document. This is pure numbers of bugs, but note that attackers favor different classes of bugs differently:
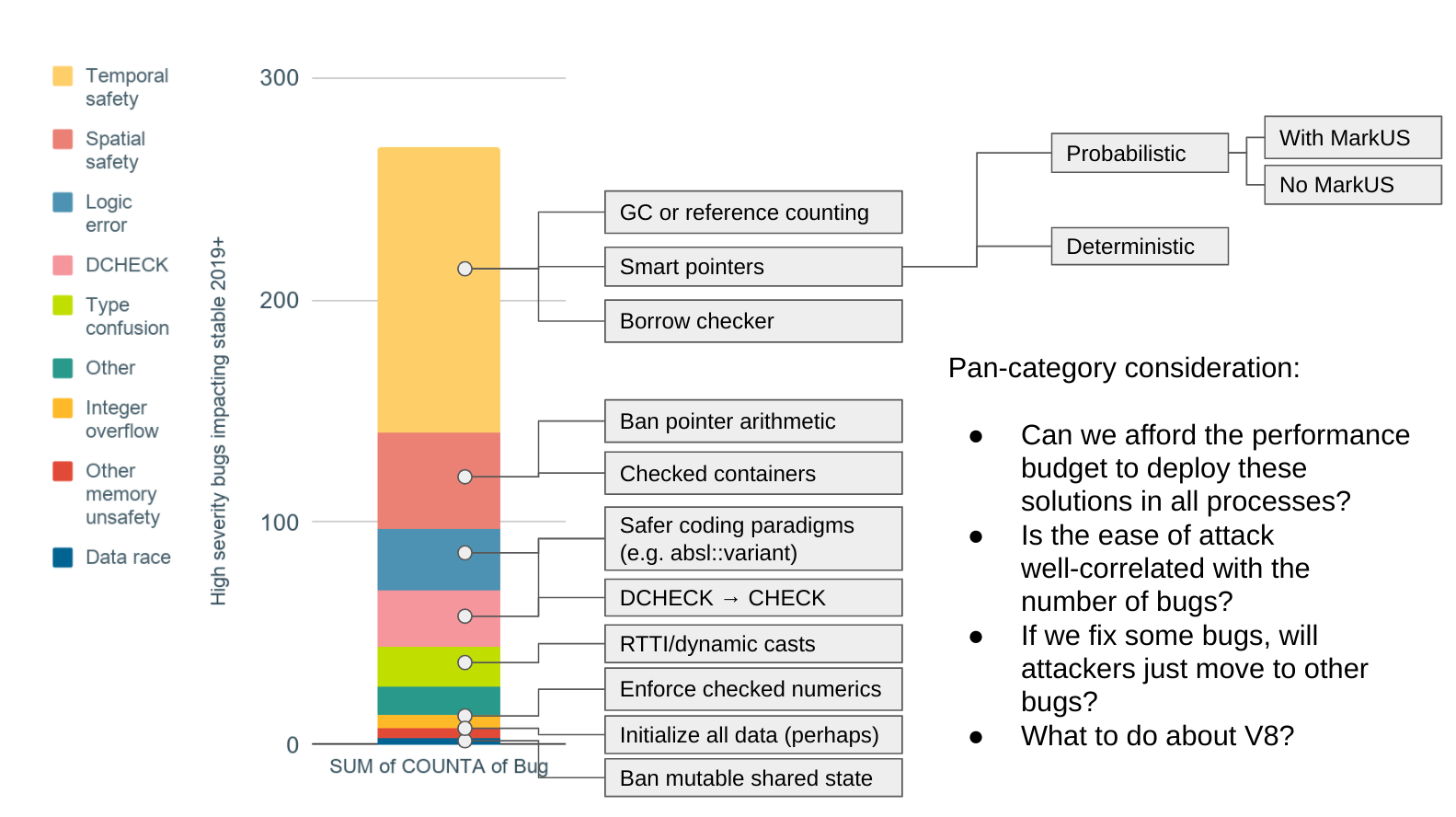
(source; Google-internal but the results are reproducible from the public bug tracker)
The proposals and in-progress work described in the rest of this document are roughly ordered by how much impact they might have on our most significant bug classes.
Managing Expectations
Note that many of these proposed and in-progress projects are quite large and complex, even changing the semantics of C++. While we think most of them are necessary, we also know that they are not sufficient. That is the nature of the C++ problem.
With that, here they are.
Remove/Reduce Raw Pointers
Problem: Manual lifetime and ownership management has proven too difficult for even very experienced engineers to reliably do correctly. This results in UAF bugs and also memory leaks.
Solution: Ban the direct use of raw pointers, new, and delete. Instead, require developers to use one of the MiraclePtr implementations, for example. Note: Wrapping pointers in some syntax is beneficial for most approaches (Oilpan, MiraclePtr, *Scan, et c.), and is valuable on its own.
Current status: Work in progress (as of August 2021) for T* fields in the browser process. The MiraclePtr project aims to make a smart pointer type that makes UAF unexploitable while not regressing run-time performance too badly.
Costs: Performance (TBD; as of August 2021 we are actively quantifying the impact of several implementations). Deviation from C++ language community norms. Non-Chrome C++ is is much less likely to adopt this approach and hence will not get the temporal safety that MiraclePtr provides (e.g. Google code pulled into Chrome, open source dependencies). Difficulty of diagnosing crashes (only one call stack from MiraclePtr as opposed to three from ASAN: allocate, free, use). If we wish to apply these protections to 3rd-party code, we may need to fork repositories such that their other consumers also use non-standard C++. (Most UAFs happen in 1st-party code.) Instantaneous cost of rewriting lots of code (merge conflicts, etc.).
Benefits: UAF accounts for around 48% of high-severity security bugs (and climbing). MiraclePtr plans to address ~50% of those now, and might theoretically cover 20% more in the future by banning raw pointers in containers and in local variables and function parameters. (In practice using MiraclePtr in local variables and tight loops might have a prohibitive performance cost.) The proposed implementation, BackupRefPtr, involves the potential runtime cost of atomic reference counting. (It can still be defeated by pointer arithmetic and aliasing.)
See Pointer Safety Ideas for more information.
However, Project Zero believes that inside renderer processes, the majority of UAFs are not of the kind MiraclePtr fixes. Instead, they are iterator invalidation and other lifetime mishaps.
Annotate Lifetimes
Problem: C++ lifetimes are unknown to the compiler, and impossible to follow with static analysis.
Solutions: In some cases, we can annotate lifetimes with [[clang::lifetimebound]] in order to tell the compiler the lifetime is bound to an object.
The attribute has many limitations, meaning it is not a solution for memory safety, but it can help with some important scenarios. The limitations are:
- There is no way to distinguish between different lifetimes.
- There is no way to annotate a static lifetime.
- The attribute attaches to function parameters and always implicitly refers to the outermost reference-like type; it is not possible to attach it to part of a type (e.g. to the T* in a const std::vector<T*>&).
- The single lifetime is implicitly applied to the outermost reference-like type in the function’s return type (or the value of the constructed object, in the case of a constructor). Again, it is not possible to associate the lifetime with inner reference types in the return value (e.g. the T* in const std::vector<T*>&).
- There is no way to add a lifetime parameter to a struct. This means that parameters can only be attached to the object’s lifetime if they are given to a constructor, not in other setters.
In theory, we should apply this to:
- Any constructor reference parameter that is stored in a field.
- However it misses even trivial examples:
- Any constructor pointer parameter that can be held in a const member. (In other words, the pointer is never reassigned.)
- However it misses even trivial examples:
- Any class method that returns a reference or pointer to a class member (but not to pointers inside class members, unfortunately).
- However it misses even trivial examples:
- Any function that receives references or pointers and returns a reference or pointer back to its input. This includes templated functions that return one of their inputs (such as min/max/clamp).
The only cases this attribute only actually catches at the moment are invalid use of temporaries. While this is a valid/important memory safety bug when it happens, it is not representative of the type of bug we see in our UAF security bugs.
- And it does not even catch all temporaries:
- In fact it’s hard to construct an example that it does catch.
Some key potential places to do this are:
- base::span constructor
- base::StringPiece constructor
- base::clamp
- ????
- Reference/pointer-returning methods everywhere — but only if we can show that the attribute actually helps (see above godbolts for counter-examples).
Note that base::span is designed to be able to hold an invalid pointer past the end of the container it’s “pointing” to, and the lifetime analysis can not help with this problem. This is a spatial memory safety problem built into C++. But it could potentially help with using the base::span beyond the lifetime of the object it points to, if the attribute caught more misuses.
Current status: Not started.
Costs: Visually noisy annotations (the Abseil macro is a mouthful) present in the code. We will learn to become familiar with them. But there are many places where the annotation can not be used. The annotation can be written incorrectly, where it is more strict than the object requires, or it may become incorrect over time if an object is changed. For instance, if base::span grew a method to re-assign the pointers.
Since the attribute is defined to generate a warning if a violation can be spotted, it does not actually guarantee violations are caught. And it seems that most are not (see godbolt examples above). This can give a false impression of safety, which may lead to developers trying to rely on the attribute catching their mistakes and actually writing more UAFs.
Furthermore, there is no way to enforce that the annotations are present where they are possible, which would allow new code to be written without them. Code authors that rely on annotations to check their correctness would be left without any checks.
Benefits: Compiler errors when some set of simple lifetime errors are written.
Implement Automatic Memory Management
Problem: Temporal safety and correctness (UAF, leaks).
Solutions: Reference counting (e.g. ARC-like semantics), and/or full GC.
Current status: Oilpan is now a generic reusable library (no longer special to Blink), and we have adopted it in PDFium to resolve many or most of our temporal safety problems in that project. This enabled us to ship XFA Forms support in production, for example! (Currently off by default, due to functionality gaps.)
Costs: Reference counting needs to be atomic, which costs micro-time. Fully generic GC can be expensive.
Benefits: UAFs account for around 48% of high-severity security bugs (and climbing). This approach is an alternative to the universal application of checked pointer types (see above). Additionally, GC has excellent developer ergonomics.
Implement Ownership Analysis
Problem: Temporal safety and correctness (UAF, leaks).
Solutions: Enforce at run-time that there is a single ‘owner’ of any object, which can only be changed via std::move. Allow ‘borrows’ with Rust-like rules which prevent multiple mutable references existing at the same time, and ensures objects aren’t accessed beyond their lifetime bounds.
This solution seems a poor fit to C++, but it keeps being proposed so it seems important to discuss it here.
Rust achieves this model through fairly complex compiler support. The majority of objects therefore incur no runtime cost for this sort of ownership checking; it’s all static. Developers can optionally instead use a runtime version (RefCell<>) which does the same checks at runtime. We presume this model would be far too expensive if every object were tracked at runtime, and we don’t see a way to do static build-time enforcement in C++ without radical compiler and language changes. (Clang has added lifetime bounds for simple cases, but see above).
Current status: We have some early experiments at runtime ownership enforcement. Compile-time safety is infeasible without fundamental changes to C++ such as new reference types. There is work for limited safety in clang warnings that will catch dangling references through control flow analysis, but these will not catch invalid heap pointers by design.
Costs: Runtime costs equivalent to reference counting. Need to distinguish ‘owner_ptr’ from ‘borrowed_ptr’.
Benefits: UAFs account for around 48% of high-severity security bugs (and climbing). This approach is an alternative to the universal application of checked pointer types.
Use -Wdangling-gsl
Google has had good results with this internally, finding and fixing UAF bugs. There are some false positives, but plenty of true positives.
Current status: Clang defaults to on, and this warning is not disabled in BUILD.gn files, so we seem to be making use of it.
Define All Standard Library Behaviors
(Where possible.)
Problem: The standard library is riddled with potentially exploitable undefined behavior. This includes lack of bounds checking (e.g. std::span::operator[]) and lack of validity checking (e.g. std::optional::operator*). std::string_view’s unfortunate affordance for UAF is a separate problem, though. This is especially unfortunate in the recent library additions, because unsafe-but-fast options were already available.
Since std is specified to have lots of UB, we cannot easily be and remain certain that implementations we use will be fully hardened or easily hardenable against UB, especially as new features are added. Instead, we should use a std(-like) replacement whose design and implementation we can more effectively influence, such as Abseil. Alternatively, we could dedicate headcount to working with upstream libcxx to ensure a hardened mode is robust and supported.
Solutions: Add a ‘hardened’ mode (selectable at compile time) to standard library implementations that allows us to make the undefined behavior well-defined and safe. This is fairly ‘easy’ for spatial safety; for temporal safety, see above.
Current status: Abseil team have already added a spatial safety hardening mode to Abseil. It perhaps could use a completeness audit, but as of August 2021 it looks pretty good. We use this mode in Chromium. A similar hardening mode for LLVM libcxx is in progress (upstream). We have also added spatial hardening to //base (but could use a completeness audit). WTF also has the same status as //base.
We are also considering a project to build a standard-like library with no UB [Google-internal for now, sorry], since there is not much appetite for making //base stand-alone. However, Abseil with hardening may obviate that. But if there is general interest for an open source, std(-like) library that is specified to have no UB, we could dedicate headcount to that.
Costs: Possible micro-cost in run-time due to increased checking.
Benefits: Spatial unsafety is 16% of high severity security bugs; possibly 17.5%.
Define Undefined Iterator Behaviors
Problem: In particular, it seems important to mention 2 bug classes involving UB in iterators. Thanks to Sergei and Mark from P0 for raising these points:
for (auto& iter : my_container) {
MaybeChangeMyContainer();
}
and
auto iter = my_container.find(the_thing);
DCHECK(iter != my_container.end());
iter->second->Foo();
Mark says:
It seems like the iterator invalidation problem could be solved efficiently.
EITHER by having the container track live iterators and "neuter" any live iterators when an iterator-invalidating operation occurs - it should be rare that such an operation occurs with many live iterators, so this should be fairly inexpensive, and would incur zero overhead on iterator access.
OR using something like a generation tag, which would be checked on iterator access; this would add iterator access overhead so it might be too expensive?
OR more API-breakingly, we could simply CHECK on iterator-invalidating operations when there are live iterators - this would be cheaper but would likely require significant testing and code changes to ensure that on-stack iterators are discarded once they're not being used.
Solution: We have a CheckedIterator type in //base.
Current status: It had been expensive in practice (due to a lack of a supported way in libcxx to express that it can be optimized), but that is fixed now. We should expand its use now that we can do so efficiently. For example, it should be possible to create a well-defined end singleton template that crashes cleanly.
Costs: Hopefully, the run-time overhead is acceptable now.
Benefits: Reduced iterator invalidation UB (including spatial and temporal unsafety).
Define Integer Semantics
Problem: C/C++’s integer semantics are bonkers: the wrapping, overflow, underflow, undefined behavior, implicit casting, and silent truncation behaviors all add up to unsafety and poor ergonomics. As a result, developers have a hard time correctly calculating sizes, indices, and offsets, especially when an attacker can control some of the terms. Arithmetic overflow and underflow often lead to mistakes in memory allocation and access, and from there to exploitable bugs. Other bug classes arise from integer overflow too, such as reference counts wrapping, or wrapping causing unique IDs to no longer be unique.
Implicit conversion from integer to floating point hides the fact the stored value potentially changes. It’s insidious as within common ranges the value does not change, but if an attacker can control the value of the integer, they can make it large enough to violate the assumption. Then on conversion back to an integer, the result becomes invalid.
Solution 1: Require developers to use the //base/numerics library or something similar. Specify specific types for intentional wrapping, saturating, and trapping (as Rust does). The norm should be that people use reliable arithmetic by default, and leave primitive C arithmetic behind to the greatest extent possible. In particular, we should dedicate some headcount to improving the generality and ergonomics of //base/numerics, and should make it into a stand-alone dependency. (It already is easily separable from //base, but you have to copy and paste.)
Solution 2: We could require compiler options to make signed overflow behave the same as unsigned (i.e. wrapping). That is, we could standardize on the Java and Go behavior: we could use -fwrapv in debug and production builds. Alternatively, we could use -fwrapv in release builds and -ftrapv in debug builds (like Rust).
Solution 3: Clang also has sanitizer options — which can be configured to immediately trap, thus requiring no run-time support — to handle division by 0, truncation, implicit casting, and shifting left too far, casting an integer to an invalid enum value.
Android already uses -fsanitize=signed-integer-overflow,unsigned-integer-overflow in large (and growing) parts of the codebase.
enh@ notes: “In combination with fuzzing it works quite well to show you where you need __builtin_add_overflow or whatever. Without fuzzing it's a ‘good’ source of work backporting security fixes as/when stuff is found in the field.”
Solution 4: Clang provides a warning on implicit int conversion to float, behind -Wimplicit-int-float-conversion. We should enable this warning.
Current status: //base/numerics is used in many places successfully. We just need to use it more. The API needs some ergonomic improvements.
We do not use either -ftrapv or -fwrapv in any .gn or .gni file. We have disabled the -Wimplicit-int-float-conversion warning.
Build profiles that use is_ubsan sanitize signed int overflow, and with a significant block list. It does not seem to be on in production builds of Chrome.
Costs: Training. Migrating code. Some 3rd-party projects (e.g. Skia) resist systemic solutions. Potential for micro-efficiency regression if people use checked arithmetic in tight loops. Potential for binary size increase if we ship UBSan with trapping (which does not require the UBSan runtime support library and produces small, coalescable branch targets on failure).
Assuming overflow behavior is a significant change in C/C++ semantics. (LLVM developers for example try to avoid introducing new semantics with command-line options; but some already exist out of necessity.) If developers come to rely on well-defined integer behavior, code can become buggy if anyone were to turn the option off. (We can, and should in any case, protect against this with tests.) Using explicit types for trapping, wrapping, and saturating avoids that, but doesn’t easily work for 3P dependencies and requires explicit changes to call sites.
Benefits: Integer overflow represents around 2% of our high severity security bugs, though arguably that’s reduced in importance if we truly manage to prevent buffer overflows (see later). Using -fwrapv may and should be maximally compatible with existing code, and matches most developers’ expectations. Using UBSan with trap-on-failure covers the most problems but may require some carve-outs and may introduce some speed and binary size regressions (an empirical question). Call sites that need explicit checking should continue to use //base/numerics in any case.
There are also logical bugs, such as an expectation that incrementing numbers will remain unique as identifiers, reference counters wrapping, and so on. Again, trapping or sanitizing would catch these. With a Trapping<T> in //base/numerics, we could statically ensure that.
Having defined behavior and skipping odd optimizations based on undefined integer behavior might also improve ergonomics.
Set Pointers To Null After Free
Problem: The contents of a region of memory after free are undefined. That is confusing and potentially exploitable.
Solution: kcc@ notes: “Another potential investigation is nullifying pointers after free (by compiler). After delete foo->bar, add foo->bar = nullptr. Obviously, it’ll fix a small portion of cases (guesstimate: 1% – 10%); e.g. it can't handle delete GetBar();. But it’s ~ zero overhead and relatively easy to implement. LLVM patches have been floating around (but IDK the current state).”
This will also help make any GC-based approaches more efficient.
Current status: None.
Costs: kcc@ says ~ zero.
Benefits: Detect 1 – 10% of UAFs. Improved developer ergonomics (modulo aliasing, the contents of a region after free and before it is reused are now defined).
Define Null Pointer Dereferences
Problem: Null pointer dereferences are UB. This is an issue because developers (reasonably) expect a null pointer dereference to crash the process instead of continuing. However, the compiler can and sometimes will optimize away the null pointer dereference and in some cases to elide a check for it, even though continuing execution might result in a much more corrupted state and possibly exploitable behavior.
For example, our smart pointer type WeakPtr was vulnerable to UAFs: if the pointed-to object was destroyed, WeakPtr::get would return a null pointer and the subsequent dereference was supposed to crash the program. However, clang correctly determined that storing a null pointer and immediately dereferencing that pointer was undefined behavior, and therefore removed the store of null pointer entirely. So WeakPtr::get would actually return the stale pointer and the dereference would instead result in a UAF. There has been at least 1 externally-reported high-severity security bug due to this issue (fixed with an explicit CHECK).
Solution: Clang provides a compiler flag called -fno-delete-null-pointer-checks (named as such for historical reasons) that defines null pointer dereferences. With this flag, dereferences of null are never optimized away.
Current status: Landed.
Cost: 42 kB Android binary size (at minimum) and some microbenchmark regressions in Blink parsing performance.
Benefits: With this flag, the compiler behaves the way most developers expect, making it easier to understand the meaning of code.
Require Coding Patterns To Reduce Lifetime Errors
Benefits: UAFs account for around 48% of high-severity security bugs (and climbing). Improved coding patterns are not a robust solution, since they’re still subject to human error. But they may eliminate some fraction of the bugs. When combined with a robust solution such as a deterministic MiraclePtr, they may remove some (non-exploitable) crashes.
Use absl::variant Instead Of enums For State Machines
Problem: enums are often used for state machines. Unfortunately, the enum variant is not the only bit of the state — there are almost always extra fields which pertain to a subset of the states. These things get out of sync, causing object lifetime problems and logic errors.
struct StateMachine {
enum {
CONNECTING,
CONNECTED,
DISCONNECTING,
} state;
// These fields could get out of sync with ‘state’:
int thing_relevant_only_when_connected;
std::string thing_relevant_only_after_connection;
};
Solution: Use absl::variant, which is a type-safe tagged union. All data which relates only to one of the states should be associated with that specific variant.
Current status: absl::variant is newly allowed. No attempt has been made to retrofit to existing code.
struct Connecting { int thing; }
struct Connected { std::string thing; }
struct Disconnecting { std::string thing; }
auto state_machine = absl::variant<Connecting, Connected, Disconnecting>;
Costs: Awkward syntax (arguable). Difficulty of identifying which enums are used for state machines. (Can we simply ban all enums?)
Benefits: Reduced logic errors and object lifetime errors, currently unquantified.
Ban std::unique_ptr::get; Use Shared Pointers
Problem: unique_ptr encourages the notion that there’s a single owner, yet we see such pointers featuring in use-after-free bugs so this notion is obviously wrong. (unique_ptr really guarantees a unique deleter, not necessarily a unique owner.)
Solution: Prevent any means of getting a raw pointer out of a unique_ptr (to the extent possible). Not even a checked pointer: if developers are getting any extra pointers to something within a unique pointer, then it’s not truly uniquely owned, and they should use a shared pointer. (Yes, we really do have to incur the costs of reference counting.) And in most cases where unique_ptr is used, it might be better to use base::Optional to obtain composition into a single heap cell.
Current status: Opposite of current best practice, where shared pointers are discouraged and unique_ptr encouraged.
Note that dcheng has a countervailing view: that we instead want clarity of lifetime and the ability to assert ownership more clearly than shared_ptr/reference counting/GC allows:
What I think we really need is a safe version of raw pointer to make lifetime assertions when we believe an object should have single ownership. There was a previous attempt at this called CheckedPtr (though that kind of conflicts with MiraclePtr's implementation details now)... maybe we should seriously consider it though, as this seems to be a repeated theme.
Costs: We may find lots of objects need reference counting. But we need to do that for safety. Reduced clarity about lifetimes and when an object’s destructor would run. It would also be easier to create reference cycles.
Benefits: Reduced object lifetime errors, currently unquantified. Fewer heap allocations and dereferences if we use composition more often than a pointer.
Initialize All Memory
Problem: When a program uses variables before they have been initialized, bugs ensue. These can include (possibly exploitable) wild pointer dereferences and information disclosure bugs. Using uninitialized memory may also introduce application-semantic bugs that may or may not be security vulnerabilities.
(Information disclosure bugs can occur when the struct has padding, and the code memcpys a struct and sends the result to another process. The padding may be uninitialized, which is to say, whatever data was there previously — and perhaps that data is sensitive. We have had bugs like this in the past. Of course, the proper fix for such information disclosure bugs is to properly serialize structs, initializing the whole struct first is a good defense in depth.)
Solutions: In addition to being nice, well-defined behavior (and hence good for developer ergonomics, as Go has shown), initializing all memory (either to 0 or some canary value) eliminates wild pointer and application-semantic bugs arising from the use of uninitialized memory.
Alternatively, we could configure the compiler to reject variable declarations that have no initializer.
Current status: vitalybuka@ has painstakingly enabled stack auto-initialization, on non-Android, with some carve-outs, and has worked for months to solve performance regressions by excluding hot paths.
enh@ says:
Android R has stack zero initialization for kernel and userspace. We found relatively few places in userspace that we needed to annotate for performance. Folks are looking at heap zero initialization for S. That will probably be harder.
Future work:
- Heap auto-init (currently it is stack-only)
- Try to push for zero-init again
- See if we can switch to __attribute((uninitialized)) instead of build config carve-outs
- Try V8 again?
Costs: Auto-initialization has proven to incur noticeable run-time costs in hot paths. (Vitaly has manually opted those hot paths out of auto-init.)
Assuming auto-init is a significant change in C/C++ semantics. If developers come to rely on auto-init, code can become buggy if anyone were to turn auto-init off. (We can, and should in any case, protect against this with tests.)
Benefits: Uninitialized memory is a small fraction of our high severity security bugs, probably no more than 1.5%. Auto-init reduces the cognitive load (less need to remember all UB), and may enable cleaner code paths iff developers can assume autoinit is always on if the program continues.
Since we do need to turn auto-init off in places, such call sites should be ‘obvious’ and well-documented. (An example of obvious and well-documented: using __attribute((uninitialized)) or similar in hot spots rather than special-casing directories in the build.)
Remove Primitive Arrays
(May be covered under Remove Raw Pointers.)
Problem: Primitive C arrays are not bounds-checked, and thus tend to exhibit spatial safety bugs. -fsanitize=bounds only works when the compiler can statically determine the array’s size, which is not always.
Solutions: Require the use of a type like std::array where C-style arrays are currently in use. It may be possible to automatically migrate old code to std::array (similar to how we are automatically migrating code to MiraclePtr). Note that this is only a security win if we also use a std implementation where all undefined behavior is defined; for example, std::array::operator[] does no bounds checking. (See Define All Standard Library Behaviors.)
Current status: None.
Costs: Micro-efficiency. Training and socialization. May want to write a PRESUBMIT check or (preferably) a clang warning, if that’s possible.
Benefits: Spatial safety is 16% of high severity security bugs; possibly 17.5%.
Remove Mutable Shared State
Problem: C++ cannot prevent data races.
Solutions: Implement support in the compiler to enforce this, and a borrow checker.
Current status: None. See Implement Ownership Analysis.
Costs: Unknown. Potentially significant change to developer expectations. If Chromium makes heavy use of shared mutable state in places, that code would need to be significantly refactored.
Benefits: Data races are known to be ~1% of our high severity security bugs; however they are implicated in lots of bugs that then appear in other categories (e.g. temporal unsafety) so this likely under-represents the scale of the problem.
Check Type Casts
Problem: Type confusion bugs such as this:
void SomeFunction(Animal* animal) {
// NOTE: Dog and Cat are subclasses of Animal.
DCHECK(IsCat(animal));
Cat* cat = static_cast<Cat*>(animal);
cat->Meow(); // If animal is really a Dog*, memory unsafety may ensue!
}
can be exploitable, such as by causing memory corruption when code incorrectly treats an object of 1 class as if it were an instance of another.
The static_cast should be a dynamic_cast, or otherwise automatically checked — not just in debug builds with DCHECK, but in production builds too. Historically Chrome has avoided dynamic_cast because the cost of RTTI is too high (e.g. huge object code size). That allows bugs that escape detection during debugging and fuzzing to become vulnerabilities in the wild.
Regarding object code size, davidben@ notes:
Playing around with godbolt, looks like the cost of RTTI is each vtable now also gets a typeinfo with a few quads and a class name. That doesn’t seem like it should be too expensive?
I got an (possibly with the wrong build flags) increase from 171M to 178M in a stripped Linux release build, which is substantial but doesn’t seem huge? Android hit some link error with use_rtti though I assume that’s fixable.
Assuming it is indeed the type names, maybe we just need a Clang flag to omit them? std:type_info::name supposedly doesn’t promise anything, so the empty string should be perfectly compliant...
Solutions: TODO. dcheng@ says:
I’m guessing you’re thinking of the casting helpers that @inferno@google.com originally added to WebKit. These use a handrolled implementation of RTTI.
I’ve updated these into a more ‘modern’ template-based C++ solution, but since we don’t actually support RTTI at all today, it doesn’t use dynamic_cast, even in debug mode.
The way it works today:
- Blink classes implement IsX
- There are traits that tell the cast helpers how to use the various IsX methods.
- DynamicTo<> behaves like dynamic_cast<> and returns nullptr if the type check fails. Used in places where you’d want to do IsA<X> followed by To<X>.
- To<> behaves like static_cast<> but has a DCHECK(IsA<X>);.
My ideal world would be:
- To<> always does the type check
- DynamicTo<> stays the same.
- UnsafeTo<> skips the type check in official builds when the performance is ‘necessary’.
- <Something> enforces that we use these helpers for casting rather than static_cast.
tsepez@ says:
Some years ago, I'd pondered creating subclass_cast<> (or down_cast<>) which would be defined as dynamic_cast if RTTI was enabled, and static_cast otherwise (to avoid warnings about dynamic cast in non-RTTI builds). I eventually concluded this was a bad idea, on the grounds that you make languages better by removing things from them you shouldn't use rather than adding new things that you should use.
markbrand@ says: “AFAIU clang-cfi supports this, not sure whether RTTI is required.”
kcc@ asks: “Why not cast-cfi? Microsoft is doing it.”
Current status: There is now a convention in Blink to handle the “cast to wrong subclass” problem, which used to be more common in Blink. Perhaps it could be adopted more widely.
Costs: We can make it cheaper than RTTI and dynamic_cast, but there will always be some micro-cost in run-time and possibly some cost to object code size.
Benefits: Type confusion is 7% of our high severity security bugs, though a fair amount of that is within V8 and wouldn’t be covered by C++ improvements (nor by a new general-purpose programming language). Attackers seem particularly fond of exploiting these bugs disproportionately to their number.
Make All DCHECKs Into CHECKs
Problem: DCHECKs exist to check some static invariant, but they are sometimes misused to check a dynamic invariant (sometimes on the assumption that we’ll notice the bug dynamically in debug builds). In release builds, execution might sail past the DCHECK and lead to some memory safety problem, or sometimes some logic error. In either case it can be a security bug.
Solutions: Audit for unnecessary DCHECKs (there are some), and then turn many remaining DCHECKs into CHECKs. Some DCHECKs really are checking static invariants, and those should not be converted.
Current status: Albatross build. Proposal probabilistically to enable DCHECKs for some fraction of checks on some build.
Costs: An extra branch instruction at runtime. The checking clause on some DCHECKs involves substantial binary bloat and runtime calculation (e.g. comparing trees of opcodes in V8). We would need some way of working around this, where possible.
Benefits: Can address memory safety problems and logic/correctness problems. About 30% of our high severity security bugs are not memory safety problems. 10% of our high severity security bugs are DCHECKs where we’ve determined that there may be security implications when the release build goes past the DCHECK site.
Back NOTREACHED With CHECK
Problem: NOTREACHED implies that the program has entered an undefined state, and the result will be undefined behaviour. While this crashes in debug builds, it continues on (un)happily for our users.
Solutions: Make NOTREACHED do a CHECK(false) instead of DCHECK(false), or equivalent.
Current status: There is a plan to make NOTREACHED be [[noreturn]] which includes making it IMMEDIATE_CRASH.
Costs: More binary size for our users, as these checks are compiled out in release builds today. This should be significantly smaller and safer than converting DCHECK to CHECK globally, as NOTREACHED is used to document undefined behaviour and is less common. It’s likely this would take multiple rounds of attempts to land and stick. Any NOTREACHED that was found happening in production should be removed and converted to handle that case correctly.
Prevent Use After Move
Problem: C++ allows programmers to move objects, and then use the moved-from storage. (We call this use after move, or UAM.) The state of that storage is undefined and using it is UB.
Solution: Implement a Clang plugin to prevent touching any moved value.
Existing work:
- Clang MisusedMovedObject check
- Clang-Tidy bugprone-use-after-move is deployed in google3 and in Chromium.
Clang-tidy's check is helpful but not sufficient. It does not see this as a UAM:
auto consumes = [](OnceClosure c) {};
auto moves = [&](OnceClosure& c) { consumes(std::move(c)); };
auto c = BindOnce([]() {});
moves(c);
moves(c); // Use after move.
Chromium currently relies on things like OnceCallback and unique_ptr being readable (and in a null state) after being moved-from.
Current status: None. Bug for using an attribute to annotate acceptable uses.
Costs: Hopefully none?
Benefits: Reduced object lifetime errors.
Appendix: Explore Solutions For Logic Errors
Chrome Security’s primary concern about C++ is memory safety errors. However, once they’re all fixed, attackers will move to exploit logic errors instead. There are some facilities and idioms provided by other languages which perhaps make such errors less likely. There are perhaps some things we could do to C++ to discourage logic bugs in security-critical areas. These could also potentially serve to reduce temporal unsafety.
Logic errors are around 10% of our high severity security bugs.
Encourage Type Wrappers For Security Invariants
Problem: C++ makes it awkward to write type wrappers. In another language, you might have (for instance) IpAddress and IpAddressWhichIsNotLoopback (wrapping IpAddress with zero runtime impact except for an initial check). Some APIs would only accept the latter type, providing zero runtime impact. None of this is impossible in C++, it’s just not a common pattern because C++ makes it a bit awkward.
Similarly, it might be useful to have ranged integers.
For example, there are many web platform features that require the caller to be in a secure context. Part of that check is checking that the caller’s origin is one of the secure URL schemes. Right now, we pass in normal GURLs and url::Origins (preferably the latter!), and expect the callee (the feature) to explicitly check.
Instead, we could bake that check into the constructor of a constrained class, e.g.:
class SecureGURL : public GURL {
// This constructor is intentionally not `explicit`:
SecureGURL(const GURL& gurl) { CHECK(gurl.IsSecureScheme()); ... }
}
std::vector<byte> LoadTrustedResource(const SecureGURL& gurl);
Thus the callee, in this case the hypothetical LoadTrustedResource, can only be called with a GURL that has already passed the check, and does not need to explicitly perform the check.
ellyjones@ notes that we could go further, and could make SecureGURL not a subclass of GURL, so that nobody can accidentally downcast. It would require us to restate the entire interface of GURL, though.
Solution: Guidance that compile-time type safety can address higher-level logic errors. Look for cases in the codebase where this can help. (Origins, URIs, et c. seem like a likely area, for example.)
Current status: None.
Costs: Should be no runtime cost, in fact the opposite if it means a check can only be performed once or statically, not dynamically or multiple times. It might or might not be hard to identify cases where this sort of pattern makes sense in an existing codebase.
Benefits: If any cases can be identified, may eliminate some logic bugs with no performance penalty (or a micro-improvement, e.g getting rid of a CHECK).
Appendix: Hardware Support For Detecting Memory Issues
Memory Tagging
Everything that was old is new again: tagged memory is making a resurgence. (Between that and the prevalence of JavaScript, Lisp really did win after all!) Depending on the specific mechanism, pointers to and/or regions of memory are ‘tagged’, and if code tries to load or store memory without using the right tag, the program faults. This helps us detect bugs and stop exploits with a certain (typically high) probability per instance.
MTE might appear in high-end devices soon, but will take much longer to reach most of the world.
Tagging is not a perfect defense. If an attacker can learn or guess the correct tag — and they often can — they can make use of the correct tag during their exploit and hence not trigger the hardware’s alarm. To get the benefit of tagging, we will need to make it hard for attackers to learn tag values, and hard for them to guess. (Such as by, potentially, having the browser throttle navigations to sites that crash their renderers too often. Whether that would actually work, I don’t know.)
Control Flow Integrity
We are now shipping support for Intel Control-flow Enforcement Technology (CET) on Windows.
Deploying this makes it meaningful to ship forward jump Clang CFI/Windows CFG, and we are investigating doing so in 2021. TODO: ENDBRANCH.
We are also going to investigate enabling CET on all OSs, hopefully also in 2021.
TODO: ARM PAC is shipping today for Apple devices. It would also be good to explore PAC and BTI on other hardware and operating systems.
Appendix: Bug Types
This document talks about the percentage impact of fixing different types of security bug. Those percentages are based on a manual analysis of each high severity security bug that has impacted the stable channel since the start of 2019. Exact root causes are a little approximate. It’s worth noting that the “temporal safety” sector seems to be growing year-by-year.

Appendix: Remove Null Pointers
Problem: While we don’t consider null pointer dereferences to be a security vulnerability (unless the attacker can control an offset to the pointer, which is rare), they do account for a big fraction of our stability bugs. It can also take the Security Sheriff substantial time to ensure that a given bug really is ‘just’ a stability bug (example).
Removing null pointers may also improve developer ergonomics — people can shed the cognitive and code overhead of checking for null.
Note: ASan explicitly reports a crash as null-deref if the faulty address is within [0, 4096). Without ASan one needs to look at the value of registers, but people make mistakes sometimes. Reproducing as many crashes as possible on ClusterFuzz would likely reduce the chance of an error.
Solutions: Modify the smart pointer type to require an explicit annotation or constructor flag for pointers which may be null. Check and crash on deference for such pointers. Check on construction for those pointers which shouldn’t be null.
As with integer semantics, it may be possible to get what we want with compiler options. Several options are available, including -fsanitize=null and -fsanitize=nullability-arg. The nullability-* options work with Clang’s _Nonnull annotation.
Current status: None.
Costs: The micro-cost of the check.
Benefits: We should detect stability bugs sooner, and may save time in security bug triage.
Appendix: Mitigations
This document focuses on language-level approaches to the problem: codifying safer usage patterns for C++ to reduce memory unsafety and UB generally.
Exploit mitigations and enhanced bug-finding techniques can complement such work. Examples include:
- HWASAN
- GWP-ASan
- Memory tagging (e.g. MTE)
- CFI and stack protection
- The classics: W^X/DEP, stack canaries, heap canaries, ASLR
Appendix: Other Ideas
Others possibly to include:
- Remove base::Unretained — require developers to decide the right ownership model for each object. (WeakPtr is not always a silver bullet because it cannot be used across task sequences/threads.)
- Or, back Unretained with MiraclePtr.
- Mojom improvements to ensure all objects are stored in suitable containers?
- Ban design patterns which tend to cause problems (e.g. singletons intrinsically mean shared and likely mutable state). (There was an effort to systematically investigate.)
- Re-emphasize composition rather than any kind of pointer in the first place. (Can we write a checker to look for objects owned by pointer which could instead simply be owned by value?)
- Replace base::Bind and all code which uses it with a straight-line version instead (promises? Some C++ code generator?), to simplify the ease of writing asynchronous code and make error cases easier to spot.
- Design for fuzzing: encourage patterns in mojo & implementation that make it easier to fuzz formats and object lifetimes from a compromised renderer.
- Design for static analysis: discourage patterns that give static analyzers a hard time.
- SAL annotations. Valuable at the OS boundary where annotations are already available. Basically a new language for base:: developers to interface with to take full advantage.
- Compile parts of the code with WebAssembly. (We are investigating this as of August 2021.)