Copyright (c) 2018-present, A2 Rešitve d.o.o. |

How It Works
оracdc, AMI Edition
Release 1.3.3.2
Integration with AWS Services 4
AWS Private Certificate Authority 11
What is oracdc
oracdc extends the functionality of Amazon Managed Streaming for Apache Kafka (MSK) by adding Oracle Database data integration, transactional change data capture, data streaming, and data replication functionality in near-real time.
oracdc is easy to install and deploy using AWS CloudFormation template, it is cost-optimized, manageable, and effective: less than $3000 per year (*running on spot, ARM Graviton CPU t4g.medium instance, **Amazon Managed Streaming for Apache Kafka (MSK) costs are not included, ***taxes are not included) you will be able to process at least one PiB of Oracle RDBMS changes per year. Just compare these numbers with the Oracle GoldenGate license price.
Starting from Oracle RDBMS 12c various Oracle tools for CDC and/or replication are deprecated and desupported and replaced by Oracle Golden Gate. This project is not intended to be a 100% replacement of expensive Oracle Golden Gate licenses, however may help in many cases.
oracdc uses Oracle LogMiner as a source for data changes. oracdc is designed to minimize the side effects of using Oracle LogMiner, even for Oracle RDBMS versions with DBMS_LOGMNR.CONTINUOUS_MINE feature support oracdc does not use it. Instead, oracdc reads V$LOGMNR_CONTENTS and saves information with V$LOGMNR_CONTENTS.OPERATION in ('INSERT', 'DELETE', 'UPDATE') in Java off-heap memory structures provided by Chronicle Queue. This approach minimizes the load on the Oracle database server, but requires additional disk space on the server with oracdc installed. oracdc is compatible with different topologies of Oracle RDBMS
- Standalone instance, or Primary Database of Oracle DataGuard Cluster/Oracle Active DataGuard Cluster, i.e. V$DATABASE.OPEN_MODE = READ WRITE
- Oracle RAC and Oracle Single-instance DataGuard for Oracle RAC
- Physical Standby Database of Oracle Active DataGuard cluster, i.e. V$DATABASE.OPEN_MODE = READ ONLY
- Physical Standby Database of Oracle DataGuard cluster, i.e. V$DATABASE.OPEN_MODE = MOUNTED. In this mode, a physical standby database is used to retrieve data using LogMiner and connection to primary database is used to perform strictly limited number of queries to data dictionary (ALL|CDB_OBJECTS, ALL|CDB_TABLES, and ALL|CDB_TAB_COLUMNS). This option allows you to promote a physical standby database to source of replication, eliminates LogMiner overhead from primary database, and decreases TCO of Oracle Database.
- OCI Database Services
- Running in distributed configuration when the source database generates redo log files and also contains dictionary and target database is a compatible mining database (see Figure 22-1 in Using LogMiner to Analyze Redo Log Files). N.B. Currently only non-CDB distributed database configuration has been tested, tests for CDB distributed database configuration are in progress now.
Since all the necessary settings are stored in Amazon Managed Streaming for Apache Kafka (MSK) topics, oracdc uses Amazon EC2 Auto Scaling to:
- cost optimization - you can use spot instances that are up to 90% cheaper than on-demand prices
- fault tolerance - Amazon EC2 Auto Scaling detects when an instance is unhealthy, terminates it, and launches a new instance to replace it
oracdc’s instance(s) are automatically tagged with tag a2:createdFor=oracdc
oracdc use cases
- Transactional change data capture
- Streaming Data
- Database replication
- Migration from Oracle RDBMS to different databases
Time to deploy
Typical deployment time does not exceed one to two hours including required Oracle Database setup.
Integration with AWS Services
oracdc runs on top of Amazon Managed Streaming for Apache Kafka (MSK) and can be managed using AWS Systems Manager. Before running oracdc Amazon Managed Streaming for Apache Kafka (MSK) must be configured and fully operational. All configurations of Amazon Managed Streaming for Apache Kafka (MSK) are supported:
- Provisioned and serverless clusters
- Public and private and points
- All types (IAM, SCRAM, Mutual TLS, SSL, None) of AuthN and AuthZ
IAM
When Amazon Managed Streaming for Apache Kafka (MSK) is configured to use IAM access control and you will use this authentication type for oracdc, (i.e. oracdc’s CloudFormation template configuration parameter MskClusterAuth is set to IAM - default value) to authorize in Amazon Managed Streaming for Apache Kafka (MSK) additional permissions are required, which are automatically added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"kafka-cluster:WriteDataIdempotently",
"kafka-cluster:Connect"
],
"Resource": "${Value_of_param_MskClusterARN}",
"Effect": "Allow"
},
{
"Action": [
"kafka-cluster:WriteData",
"kafka-cluster:CreateTopic",
"kafka-cluster:DescribeTopic",
"kafka-cluster:DescribeTopicDynamicConfiguration"
],
"Resource": "arn:aws:kafka:${Value_of_AWSRegion_from_param_MskClusterARN}:${Value_of_AWSAccountId_from_param_MskClusterARN}:topic/${Value_of_ClusterName_from_param_MskClusterARN}/${Value_of_ClusterId_from_param_MskClusterARN}/*",
"Effect": "Allow"
},
{
"Action": [
"kafka-cluster:DescribeGroup",
"kafka-cluster:AlterGroup"
],
"Resource": "arn:aws:kafka:${Value_of_AWSRegion_from_param_MskClusterARN}:${Value_of_AWSAccountId_from_param_MskClusterARN}:group/${Value_of_ClusterName_from_param_MskClusterARN}/${Value_of_ClusterId_from_param_MskClusterARN}/${Value_of_param_KafkaConnectGroupId}",
"Effect": "Allow"
},
{
"Action": [
"kafka-cluster:ReadData"
],
"Resource": [
"arn:aws:kafka:${Value_of_AWSRegion_from_param_MskClusterARN}:${Value_of_AWSAccountId_from_param_MskClusterARN}:topic/${Value_of_ClusterName_from_param_MskClusterARN}/${Value_of_ClusterId_from_param_MskClusterARN}/${Value_of_param_KafkaConnectOffsetTopic}",
"arn:aws:kafka:${Value_of_AWSRegion_from_param_MskClusterARN}:${Value_of_AWSAccountId_from_param_MskClusterARN}:topic/${Value_of_ClusterName_from_param_MskClusterARN}/${Value_of_ClusterId_from_param_MskClusterARN}/${Value_of_param_KafkaConnectConfigTopic}",
"arn:aws:kafka:${Value_of_AWSRegion_from_param_MskClusterARN}:${Value_of_AWSAccountId_from_param_MskClusterARN}:${Value_of_ClusterName_from_param_MskClusterARN}/${Value_of_ClusterId_from_param_MskClusterARN}/${Value_of_param_KafkaConnectStatusTopic}"
],
"Effect": "Allow"
}
]
}
AWS Secrets Manager
AWS Secrets Manager is used to externalize Oracle Database secrets. oracdc comes with a pre-installed Apache Kafka Configuration Provider for AWS Secrets Manager, and when creating connection to a Oracle RDBMS, you only need to
- When configuring CloudFormation template, specify the correct value for AdditionalPolicyArns configuration parameter to point to IAM policies that allows required secrets to be read
- When configuring connection to Oracle Database specify link to secret as specified below
…
"a2.jdbc.username" : "${secretsManager:<SECRET_NAME>:<SECRET_KEY>}",
"a2.jdbc.password" : "${secretsManager:<SECRET_NAME>:<SECRET_KEY>}",
…
For instance for secret below
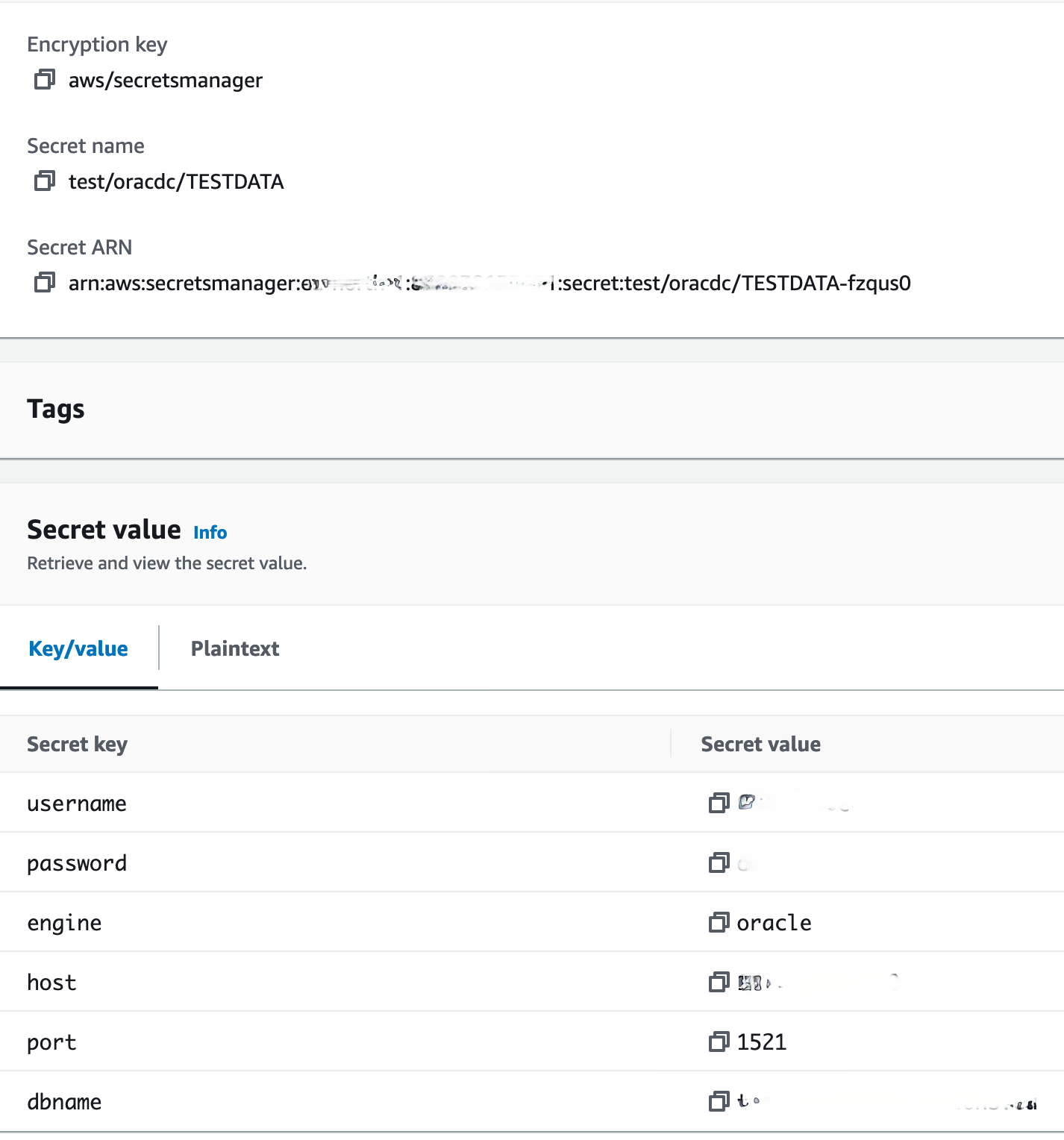
This will be
…
"a2.jdbc.username" : "${secretsManager:test/oracdc/TESTDATA:username}",
"a2.jdbc.password" : "${secretsManager:test/oracdc/TESTDATA:password}",
…
SCRAM Authentication
When Amazon Managed Streaming for Apache Kafka (MSK) is configured to authenticate using SASL/SCRAM authentication and you will use this authentication type for oracdc, (i.e. oracdc’s CloudFormation template configuration parameter MskClusterAuth is set to SCRAM) you need to set value of parameter ScramSecretARN or the first secret associated with specified Amazon MSK cluster with a name beginning with AmazonMSK will be used. To achieve this additional permissions are automatically added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "secretsmanager:GetSecretValue",
"Resource": "arn:aws:secretsmanager:${AWSRegion}:${AWSAccountId}:secret:AmazonMSK*",
"Effect": "Allow"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"kms:Decrypt",
"kms:DescribeKey"
],
"Resource" : "arn:aws:kms:${AWSRegion}:${AWSAccountId}:key:/*",
"Effect": "Allow"
}
]
}
AWS Glue Schema Registry
By default oracdc uses AWS Glue Schema Registry, which provides centralized schema management, separate metadata from data, and greatly reduces storage usage on the Amazon Managed Streaming for Apache Kafka (MSK) side. All formats currently available in AWS Glue Schema Registry are supported. You can use Kafka Connect properties shown below to consume data from topics created by oracdc. To support AWS Glue Schema Registry integration additional permissions are automatically added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"glue:CreateRegistry",
"glue:UpdateRegistry",
"glue:ListRegistries",
"glue:GetRegistry"
],
"Resource": "${Value_of_param_AcmPcaArn}",
"Effect": "Allow"
},
{
"Action": [
"glue:ListSchemaVersions",
"glue:RegisterSchemaVersion",
"glue:GetSchemaVersionsDiff",
"glue:RemoveSchemaVersionMetadata",
"glue:UpdateSchema",
"glue:GetSchema",
"glue:DeleteSchema",
"glue:GetSchemaVersion",
"glue:ListSchemas",
"glue:CreateSchema",
"glue:DeleteSchemaVersions",
"glue:GetSchemaByDefinition"
],
"Resource": [
"${Value_of_param_AcmPcaArn}",
"arn:aws:glue:${Value_of_AWSRegion_from_param_AcmPcaArn}:${Value_of_AWSAccountId_from_param_AcmPcaArn}:schema/default/*"
],
"Effect": "Allow"
}
]
}
For additional information about Apache Kafka and schemas please take look at Data Serialization: Apache Avro vs. Google Protobuf and Kafka with AVRO vs., Kafka with Protobuf vs., Kafka with JSON Schema.
Avro
The configuration for Avro uses the GENERIC_RECORD format, which provides the widest support for the Avro data types. The schema related properties for Kafka Connect are set as shown below:
key.converter=com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter
key.converter.schemas.enable=true
key.converter.schemaAutoRegistrationEnabled=true
key.converter.avroRecordType=GENERIC_RECORD
key.converter.dataFormat=AVRO
key.converter.region=<AWS_REGION>
key.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.AvroSchemaNamingStrategy
key.converter.registry.name=<GLUE_REGISTRY_NAME>
value.converter=com.amazonaws.services.schemaregistry.kafkaconnect.AWSKafkaAvroConverter
value.converter.schemas.enable=true
value.converter.schemaAutoRegistrationEnabled=true
value.converter.avroRecordType=GENERIC_RECORD
value.converter.dataFormat=AVRO
value.converter.region=<AWS_REGION>
value.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.AvroSchemaNamingStrategy
value.converter.registry.name=<GLUE_REGISTRY_NAME>
Uber-jar file with Avro Kafka Connect Converter support and additional classes (com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistryKafkaSerializer & com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryKafkaSerializer) for supporting plain Apache Kafka producers and consumers is /opt/kafka/connect/lib/schema-registry-kafkaconnect-converter-1.1.15.jar
Protobuf
The configuration for Protobuf uses the DYNAMIC_MESSAGE format, which provides dynamic schema generation. The schema related properties for Kafka Connect are set as shown below:
key.converter=com.amazonaws.services.schemaregistry.kafkaconnect.protobuf.ProtobufSchemaConverter
key.converter.schemas.enable=true
key.converter.schemaAutoRegistrationEnabled=true
key.converter.protobufMessageType=DYNAMIC_MESSAGE
key.converter.dataFormat=PROTOBUF
key.converter.region=<AWS_REGION>
key.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.ProtobufSchemaNamingStrategy
key.converter.registry.name=<GLUE_REGISTRY_NAME>
value.converter=com.amazonaws.services.schemaregistry.kafkaconnect.protobuf.ProtobufSchemaConverter
value.converter.schemas.enable=true
value.converter.schemaAutoRegistrationEnabled=true
value.converter.protobufMessageType=DYNAMIC_MESSAGE
value.converter.dataFormat=PROTOBUF
value.converter.region=<AWS_REGION>
value.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.ProtobufSchemaNamingStrategy
value.converter.registry.name=<GLUE_REGISTRY_NAME>
Uber-jar file with Protobuf Kafka Connect Converter support and additional classes (com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistryKafkaSerializer & com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryKafkaSerializer) for supporting plain Apache Kafka producers and consumers is /opt/kafka/connect/lib/protobuf-kafkaconnect-converter-1.1.15.jar
Json
For JSON the schema related properties for Kafka Connect are set as shown below:
key.converter=com.amazonaws.services.schemaregistry.kafkaconnect.jsonschema.JsonSchemaConverter
key.converter.schemas.enable=true
key.converter.schemaAutoRegistrationEnabled=true
key.converter.dataFormat=JSON
key.converter.region=<AWS_REGION>
key.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.JsonSchemaNamingStrategy
key.converter.registry.name=<GLUE_REGISTRY_NAME>
value.converter=com.amazonaws.services.schemaregistry.kafkaconnect.jsonschema.JsonSchemaConverter
value.converter.schemas.enable=true
value.converter.schemaAutoRegistrationEnabled=true
value.converter.dataFormat=JSON
value.converter.region=<AWS_REGION>
value.converter.schemaNameGenerationClass=solutions.a2.aws.glue.schema.registry.JsonSchemaNamingStrategy
value.converter.registry.name=<GLUE_REGISTRY_NAME>
Uber-jar file with JSON Schema Kafka Connect Converter support and additional classes (com.amazonaws.services.schemaregistry.serializers.GlueSchemaRegistryKafkaSerializer & com.amazonaws.services.schemaregistry.deserializers.GlueSchemaRegistryKafkaSerializer) for supporting plain Apache Kafka producers and consumers is /opt/kafka/connect/lib/jsonschema-kafkaconnect-converter-1.1.15.jar
AWS Private Certificate Authority
When Amazon Managed Streaming for Apache Kafka (MSK) is configured to authenticate using mutual TLS Authentication and needs support on the oracdc side (i.e. oracdc’s CloudFormation template configuration parameter MskClusterAuth is set to mTLS) you must specify valid value for oracdc’s CloudFormation template configuration parameters AcmPcaARN (ARN of AWS Private CA) and AcmPcaCertDaysOfValidity. Configuration utility behind oracdc’s CloudFormation template checks that AcmPcaARN is present in list of AWS Private CA’s for given cluster
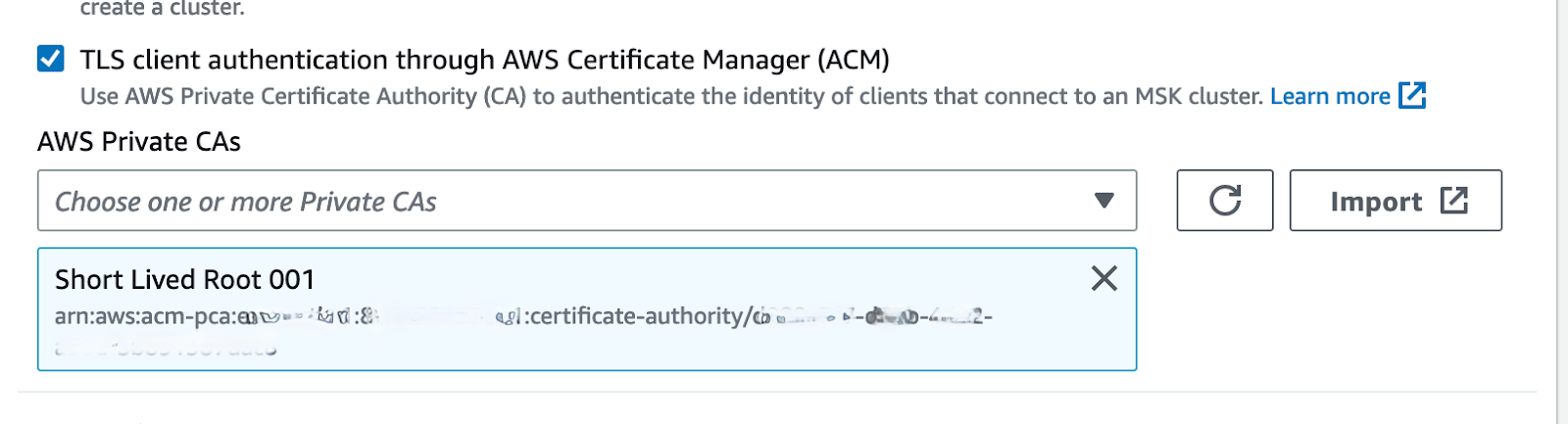
and then it automatically generates a key pair and a certificate signing request (CSR) in PKCS#10 format using following information:
CN=oracdc,L=<AWS_REGION>,O=<AWS_ACCOUNT_ID>,DC=<INSTANCE_ID>
This certificate request is printed in cloud-init.log of EC2 instance and to Amazon CloudWatch Logs log group /oracdc/configuration under stream <YYYY/MM/DD>.
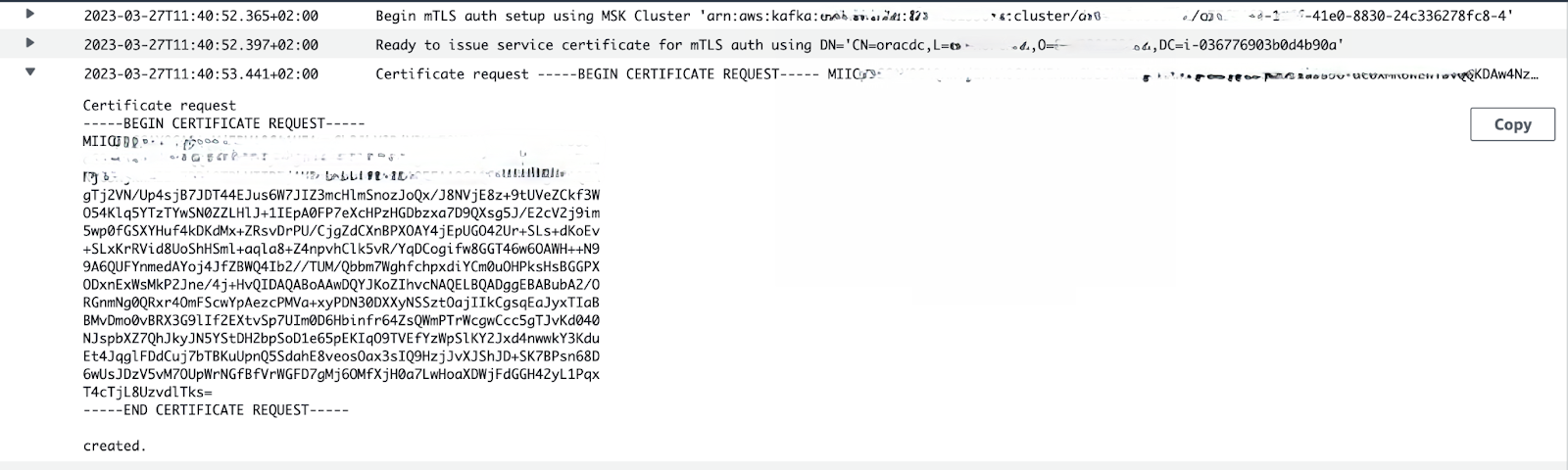
After that, a request is sent to issue a certificate using API call
aws acm-pca issue-certificate --certificate-authority-arn <Value_of_param_AcmPcaARN> --csr <Generated_CSR> --signing-algorithm "SHA256WITHRSA" --validity Value=<Value_of_param_AcmPcaCertDaysOfValidity>,Type="DAYS"
Upon receipt certificate from AWS Private CA oracdc’s configuration utility generates required Java keystore as /opt/kafka/connect/wallet/keystore.jks using <AWS_ACCOUNT_ID> as password for both keystore and private key. The resulting certificate chain and private key are stored under oracdc entry.
N.B.: Please remember that after the expiration date of the certificate you need a new certificate.
To support automatic generation of certificate for mutual TLS Authentication additional permissions are automatically added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"acm-pca:IssueCertificate",
"acm-pca:GetCertificate"
],
"Resource": "${Value_of_param_AcmPcaArn}",
"Effect": "Allow"
}
]
}
Amazon CloudWatch Logs
Amazon CloudWatch Logs is used to store the logs. Configuration utility behind oracdc’s CloudFormation template writes to logs only during running EC2 instance userdata script to group /oracdc/configuration under stream <YYYY/MM/DD>.
Runtime log /opt/kafka/logs/connect.log is delivered to Amazon CloudWatch Logs group /oracdc under stream <INSTANCE_ID> using CloudWatch Agent.
Retention for this log group is thet to value of oracdc’s CloudFormation template configuration parameter LogsRetentionInDays.
Additional permissions are automatically added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:PutRetentionPolicy"
],
"Resource": "arn:aws:logs:${AWSRegion}:${AWSAccountId}:log-group:/oracdc*:*",
"Effect": "Allow"
}
]
}
AWS Systems Manager
When oracdc’s CloudFormation template configuration parameter SystemsManagerAccess is set to value 'yes', operating system service amazon-ssm-agent is enabled and started, and the following permissions are added to the instance role of oracdc’s instance(s)
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ssm:ListAssociations",
"ssm:PutInventory",
"ssm:UpdateInstanceAssociationStatus",
"ssmmessages:CreateControlChannel",
"ssmmessages:CreateDataChannel",
"ssmmessages:OpenControlChannel",
"ssmmessages:OpenDataChannel",
"ec2messages:AcknowledgeMessage",
"ec2messages:DeleteMessage",
"ec2messages:FailMessage",
"ec2messages:GetEndpoint",
"ec2messages:GetMessages",
"ec2messages:SendReply"
],
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"ssm:UpdateInstanceInformation",
"ssm:ListInstanceAssociations",
"ssm:UpdateInstanceAssociationStatus"
],
"Resource": "arn:aws:ec2:${AWSRegion}:${AWSAccountId}:instance/*",
"Effect": "Allow"
},
{
"Action": [
"ssm:GetDocument"
],
"Resource": "arn:aws:ssm:${AWSRegion}::document/*",
"Effect": "Allow"
}
]
}
This allows you to use a AWS Systems Manager to manage oracdc’s instance(s)
Reference information
Technology Stack
Apache Kafka 3.3.2 installed in /opt/kafka_2.13-3.3.2 with symlink /opt/kafka
Maven 3.9.1 installed in /opt/apache-maven-3.9.1 with symlink /opt/maven-3
Gradle 7.6.1 installed in /opt/gradle-7.6.1 with symlink /opt/gradle
AWS Glue Schema Registry Client Library: source installed in /opt/aws-glue-schema-registry, runtime jar’s in /opt/kafka/connect/lib
IAM Access Control for Amazon MSK library: source installed in /opt/aws-msk-iam-auth, runtime jar in /opt/kafka/libs
Oracle JDBC Driver 21.9.0.0