本資料の目次
Google BigQueryとGoogle Cloud Storageの関係イメージ
BigQuery Browser Tool を用いてWebブラウザ上でBigQueryを使う
演習.公開データをテーブルに取込み、BigQueryでデータを抽出してみる。
設定しておくと便利なTips:Streak Developer Tools
Google BigQuery で使われる用語
- Google BigQuery
- BigQueryとも呼ばれます。Google Cloud Platform サービスの中において、クラウド型DWH(データウェアハウス)として提供されています。クエリと呼ばれるSQLライクな構文で目的に沿ったデータを抽出することができ、かつ他のDWHと比較して従業課金制でリーズナブルに利用することができることが特徴です。
- Projects(プロジェクト)
- プロジェクトは、データセットとジョブで構成されています。いわばフォルダのようなものになります。BigQueryの使用料は、プロジェクト単位で課金処理され、請求となります。
- Datasets(データセット)
- データセットの中には、1つ以上のTable(テーブル)が入ります。いわばテーブルの集合体になります。
- Tables(テーブル)
- PCおよびサーバー上のCSVファイルやJSONファイルもしくはCloud Storage内のCSVファイルやJSONファイルをBigQueryにインポートすると、テーブルになります。テーブルはデータセットの中に格納されます。インポート時の文字コードはUTF-8になります。
- Jobs(ジョブ)
- クエリの実行やテーブル作成時のインポート処理、もしくはクエリ実行結果をエクスポート(出力)といった各プロセスはJob(ジョブ)と呼ばれます。Jobには、必ずJob ID(ジョブ アイディー)と呼ばれる番号が付与され、その処理が管理されています。
- ACLs
- Access Control Listsの略称で、複数のユーザーで、BigQueryを使用する際にアクセス制御のために利用されます。
- ACLsによりアクセス制御を行うことができるのは、プロジェクトとデータセットに対してとなります。
- BigQuery Browser Tool
- Webブラウザ(Windows環境の場合は、Google Chrome for Business 推奨)上で利用できるBigQuery専用サービスです。ツール上で、プロジェクト、データセット、テーブル、ジョブを実行することができ、見た目にもシンプルなため、利用することが多いです。
- BigQuery Connector for Excel
- MS Excel(Windows版およびMac版)と連携するBigQuery用ツールのことを指します。Excel内に記述したクエリを実行し、指定したシート内にクエリ実行結果を表示しますので、定形のクエリを実行することに向きます。
- Cloud Storage
- Google Cloud Storageのことを言います。有料のストレージサービスであり、通常は最大400TB(テラバイト)まで使用することができます。(2012年11月現在)
400TB以上のストレージを使いたい場合は、Google社へ問い合わせる必要があります。
Google BigQueryとGoogle Cloud Storageの関係イメージ

Google BigQuery の役目
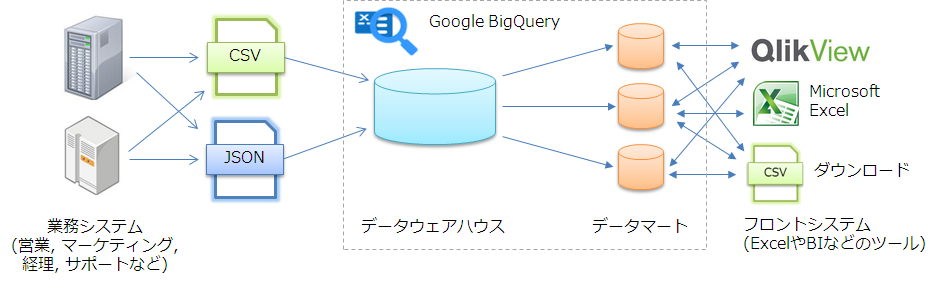
- データウェアハウス
- 業務システムに登録されたデータを長期的に取込み、時系列的整理される。クエリ(SQL)を実行することで、業務や部門などの目的に応じたデータを抽出することができる。
- データマート
- データウェアハウスにおいて、特定の目的や部門などの目的に応じて抽出されたデータのことを言う。
Google BigQuery を使えるようにする
この作業は、クレジットカードで支払処理を行うGoogle BigQuery Standardを利用する場合に発生します。請求書払いのGoogle BigQuery Premierとは異なりますので、予めご了承ください。
また、事前にGoogle Walletにクレジットカードを登録しておく必要があります。未登録の場合は、下記URLよりクレジットカードの登録をお願いします。
https://wallet.google.com/manage/ (Ctrlキーを押しながら左クリック)
- 消費者向けサービスのGmail.comもしくは企業向けのGoogle Appsにログインした状態で、Google APIs Cosoleにアクセスします。
http://code.google.com/apis/console (Ctrlキーを押しながら左クリック)
「API Project」という名称のプロジェクトが作成されておりますので、画面内の「Register...」をクリックし、Project IDを登録します。
Project IDの入力項目に英数字と”-”の組み合わせで入力、「Check availability」をクリックすることで、利用可能か確認してくれます。問題なければ、「Choose this ID」をクリックし登録となります - Google APIs Cosoleから画面左側の「Servicies」をクリックし、BigQuery API を有効にします。
- BigQuery API を有効にしましたら、使用料金を支払うための定期購買情報を登録します。
上記のように、Google APIs Console内の左側のメニューの「Billing」に注意マークが表示されますので、「Billing」の画面から、登録済みのクレジットカードに対して、「定期購入支払」の発注を行います。 - 無事登録が完了しますと、「Billing」には下記のように表示されます。これで有効化が出来ました。




BigQuery Browser Tool を用いてWebブラウザ上でBigQueryを使う
BigQuery Browser Toolを使うには、Google APIs Cosole内の「BigQuery」のメニューから「web interface」のリンクをクリックすると表示されます。もしくは下記URLからアクセスするもの手です。
https://bigquery.cloud.google.com/?pli=1 (Ctrlキーを押しながら左クリック)

BigQuery Browser Toolは、このようにWebブラウザ上で動作します。画面内には、左側に、新規クエリの作成に始まり、直近のクエリや各Jobの実行履歴、プロジェクト、データセット、テーブルといった順番になっています。各プロジェクトはGoogle APIs Cosoleで設定しますが、データセットの作成や名称変更、テーブル作成/編集/インポート、エクスポート作業はこの画面から行いますので、Google BigQueryでは先ず最初に覚えることになる画面となります。(操作の様子の動画を見る ← Ctrlキーを押しながら左クリックすると別タブで表示されます。)
データセットの作成
通常、BigQuery Browser Toolにアクセスした段階で、プロジェクトは1つだけ出来ていますので、プロジェクトはそのままとし、データセットを作成します。このデータセットは、内部にCSVファイルをインポートすることでできる「テーブル」が格納されますので、テーブルの集合体と言えます。

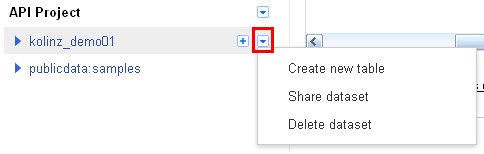
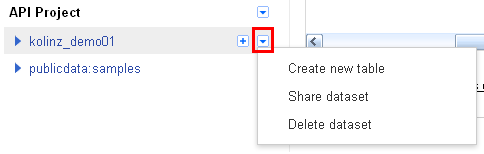
BigQuery Browser Toolの画面を表示しましたら、Google APIs Consoleで登録されているプロジェクト名や予め用意されている「publicdata:samples」といったサンプルデータセットが表示されます。プロジェクト名の右側の「▼」のアイコンをクリックし、「Create new dataset」をクリックし、データセットを作成します。なお、一度作成したデータセットの名称を変更することはできず、名称変更の際には、再度作成となります。また、データセットを他のユーザーと共有したり、削除することは可能となっています。
データセットの共有
作成したデータセットを共有する場合は、データセット名の右側の「▼」のアイコンをクリックし、「Share dataset」をクリックし、共有設定画面を呼出します。共有設定画面では、Google Drive等でお馴染みの共有設定画面が表示されますが、共有できるユーザーは、同じくGoogle BigQueryを使用している必要がありますので、Google BigQueryを使っていないユーザーに対しては、データセットの共有を行うことは出来ませんのでご注意ください。共有する前に、事前にメールやチャットで確認しておくと良いでしょう。
テーブルの作成
データセットを作成したら、次はいよいよテーブルの作成となります。テーブルでは、10MB未満のファイルであれば、テーブル作成時にアップロードすることで、テーブルを作成することができますが、10MB以上のファイルをテーブルにインポートする場合は、予めGoogle Cloud Storage内に該当ファイルをアップロードしておく必要があります。(本資料では、10MB未満のファイルを取り扱います。)
- 作成済みのデータセットから、「▼」のアイコンから、「Create new table」をクリックします。
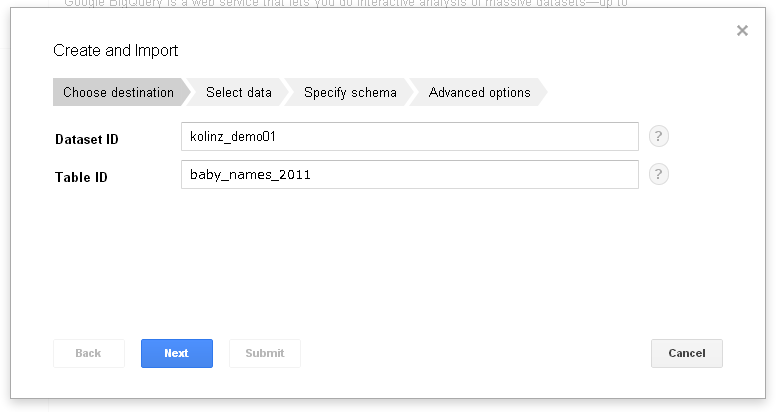
- 初めてテーブルを作成する場合のみ、下記のスクリーンショットのようにProject IDとTable IDの指定から始まります。この画面では、Project IDは指定されていますので、Table IDのみを英数字と”_”(アンダーバー)で入力し、「Next」をクリックします。
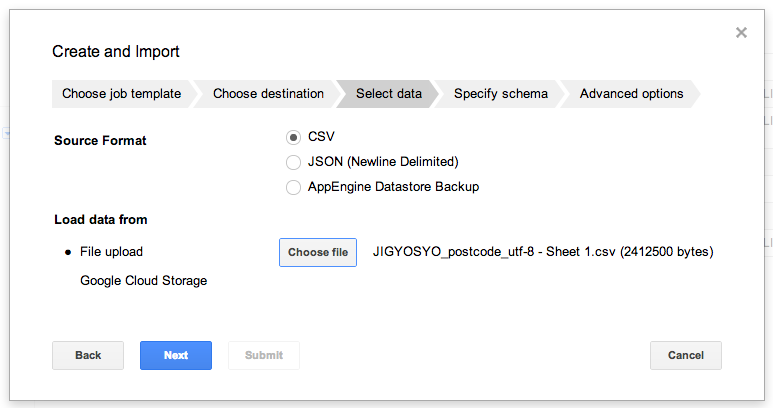
- データ選択画面が表示されます。本資料では、10MB未満のファイルを取り扱いますので、ここからダウンロード(Ctrlキーを押しながら左クリック)したサンプルデータを解凍し、中にあるCSVファイルを「Choose file」から選択しておきます。なおファイル形式は、殆どの場合、CSVファイルを指定することが多いです。
次の画面に進むため、「Next」をクリックします。 - テーブルにインポートするためのCSVファイルを選びましたので、次はスキーマを定義します。CSVファイルを用いた場合のBigQueryにおけるスキーマのデータタイプでは、string(文字列や記号の入った数値), integer(整数), float(integerよりも扱えう桁数が多い数値), Boolean(“true” or “false”といった二択)の4種類となっており、データ選択画面で指定したファイルに合わせてスキーマを定義します。
例1. names:string, gender:string, count:integer
例2. names:string. Prefecture:string, City:string, Street:string, Zipcode, integer - オプションとして、選択したデータ(CSVファイル)が、カンマ区切りなのか、タブ区切りなのか、パイプ区切りなのか、最初の何行目までを無視するのか、エラー情報はどの程度許可するのかといった数値を入力します。よく使うものとしては、Filed delimiter:Comma(カンマ区切り), Header rows to skip:1 で指定することがあります。カンマ区切りのデータで、最初の1行目を無視するという意味です。CSVファイルの1行目は、各列名が入っていることが多いためです。
この列名を英数字に変え、先ほどのスキーマ定義に活用すると後々わかり易くオススメです。 - テーブルの作成画面で、最後に「Submit」をクリックしますと、少し時間を経過した後に画面左側の「Job History」に、テーブル作成のJob(ジョブ)が稼働していることが確認できます。
画面内で、数のように、「緑色のアイコンにLoad」となっていれば、テーブル作成完了となります。
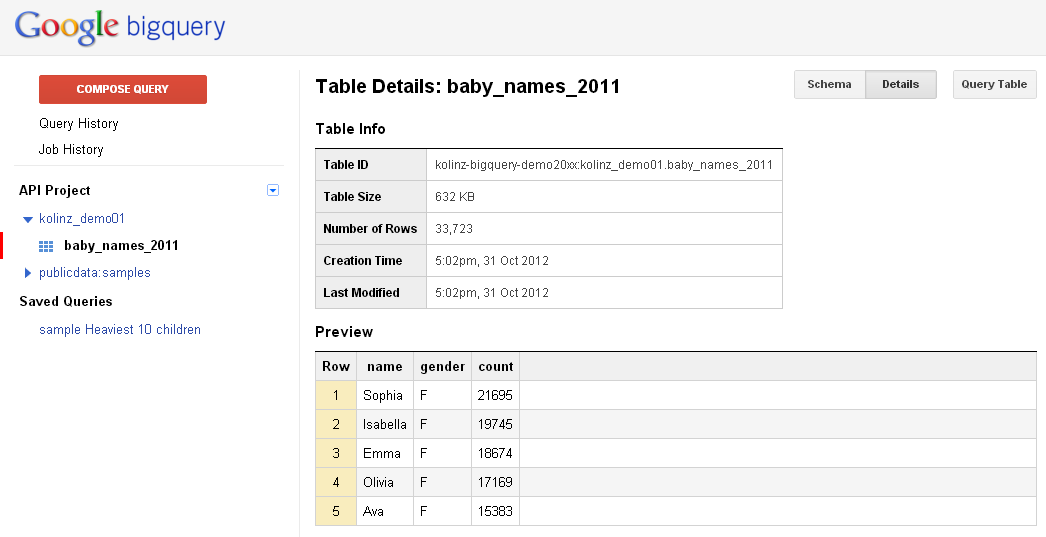
取り込むファイルサイズとネットワーク速度によって暫く時間を要することがあります。 - 画面左側からデータセット名をクリックし、先ほど作成したテーブル名をクリックしますと、作成したテーブル情報が表示されます。
「Shema」と「Details」、「Query Table」というボタンが画面右上にあります。「Schema」をクリックすると、登録したスキーマ情報が表示され、「Details」では、テーブル内の詳細情報と実際のデータの一部が表示され、どういったものが格納されているか確認することができます。 - テーブルの内容を確認できましたので、早速画面右上の「Query Table」をクリックし、テーブルからクエリを使って、目的のデータを抽出する手順をご紹介していきます。
- クエリを実行するためには、クエリと呼ばれるSQLライクな命令文を記述しなければなりません。
今回は、下記のサンプルをコピー&ペーストで入力します。
SELECT name,count FROM [データセットID.テーブルID] WHERE gender = 'M' ORDER BY count DESC LIMIT 5;
もし貴方の使っているBigQueryにて、
データセットID = kolinz-demo01
テーブルID = baby_names_2011
とすれば、[データセットID.テーブルID] は、[kolinz_demo01.baby_names_2011] となります。
クエリを入力しましたら、「RUN QUERY」をクリックし、クエリを実行します。 - 無事クエリが実行できましたら、画面右下にクエリに則って抽出されたデータが表示されます。
このデータは、「Download as CSV」により、CSVファイルとしてダウンロードしたり、「Save as Table」により、新たにテーブルとして登録することができますので、クエリを何段階に分けてデータを抽出していくような作業に重宝します。







ここまでで、BigQuery Browser Toolsにおける基本的な操作を覚えることが出来たと思われます。
但し、ハンズオンとしてデータ量が少ないですから、今度は2万2000行の少し大き目のデータをテーブルに取り込み、クエリを用いて目的のデータを抽出してみましょう。
演習.公開データをテーブルに取込み、BigQueryでデータを抽出する。
- サンプルデータの準備
郵便番号データダウンロードより、事業所の個別郵便番号をクリックし、最新のデータ(lzh形式なのためファイル解凍時に注意)のダウンロードを行う
http://www.post.japanpost.jp/zipcode/download.html (Ctrlキーを押しながら左クリック)
ダウンロード後、ファイルを解凍し、MS ExcelやGoogle スプレッドシートにて、下記のように加工。
なお文字コードは、UTF-8となるように加工し、CSVファイルとして保存しておきます。
ファイルを加工した段階で、BigQueryでテーブル作成時に設定するスキーマ定義を検討します。
Name:string, Prefecture:string, City:string, Street1:string, Street2:string, Zipcode:integer, Postoffice:string
このようにスキーマ定義をデータ加工時に検討しておくと作業を効率的に進められます。 - BigQuery Browser Toolにおいて、テーブルの作成を行います。必要に応じて、データセットから作成しても良いです。
Table IDを入力し、「Next」をクリックします。
加工済みのCSVファイルを選択し、「Next」をクリックします。
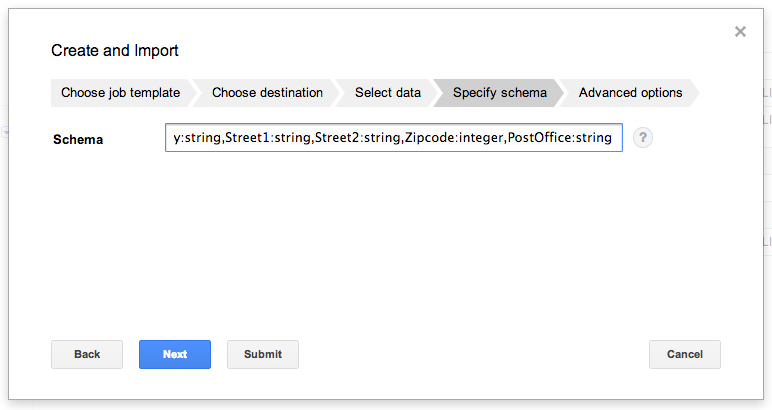
サンプルデータを準備する際に検討しておいたスキーマ定義を入力します。
Name:string, Prefecture:string, City:string, Street1:string, Street2:string, Zipcode:integer, Postoffice:string
入力後「Next」をクリックします。
ここで、Filed delimiter:Comma(カンマ区切り), Header rows to skip:1 を指定します。
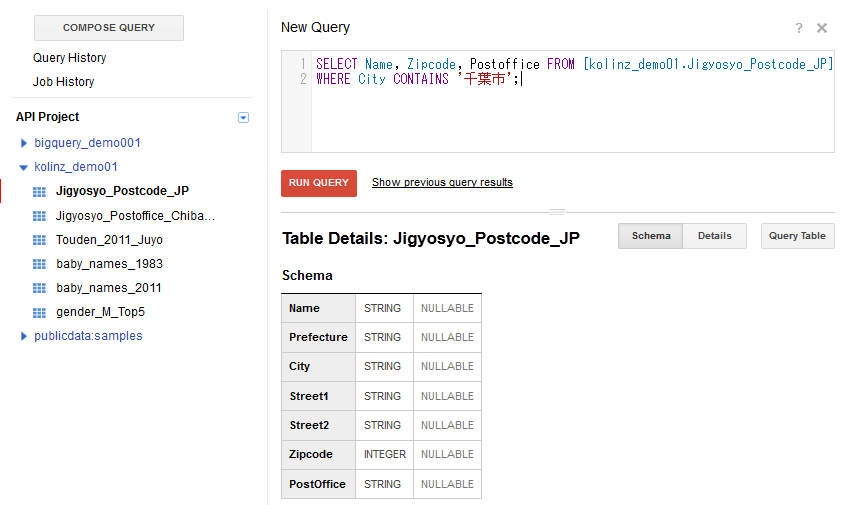
指定後、「Submit」をクリックします。 - Job(ジョブ)が処理され、画面左側にテーブルが登録されます。テーブルが登録されましたら、テーブルIDをクリックし、テーブル情報の画面から「Query Table」をクリックするか、画面左上の「COMPOSE QUERY」をクリックし、下記のクエリを入力します。
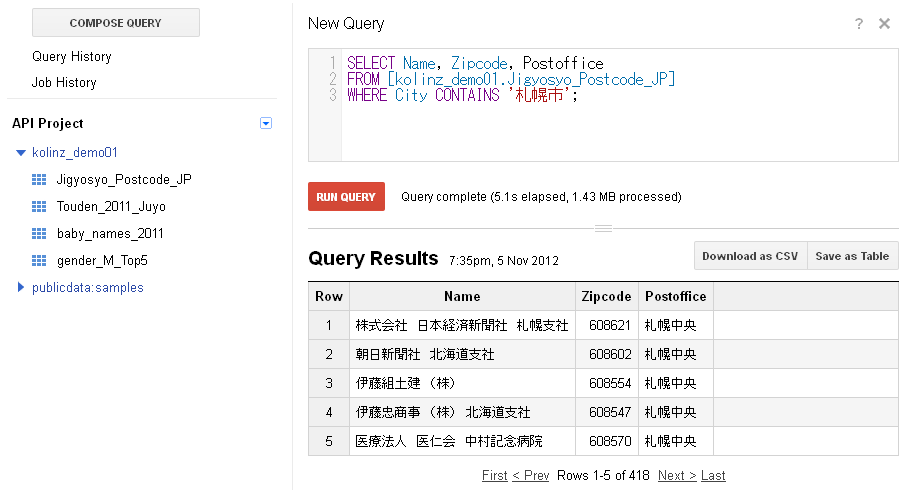
クエリ例. SELECT Name, Zipcode, Postoffice FROM [データセットID.テーブルID] WHERE City CONTAINS '札幌市';
先ほど作成したテーブルから、Cityの列に札幌市が入っている行で、Name(企業の事業所名), Zipcode(郵便番号), Postoffice(管轄の郵便局)を列として抽出ということになります。
このクエリの実行結果は、下図のようになります。
元データにおいて、札幌市内の事業所数が418件でしたので、抽出された件数と合致します。




このように、2012年11月現在、画面こそ英語ではありますが、簡単な操作で、WebブラウザからGoogle BigQueryを利用し、目的に応じてデータを抽出することができます。
補足資料
設定しておくと便利なTips:Streak Developer Tools
Google Chromeをお使いになっている場合は、下記URLより「Streak Developer Tools(Ctrlキーを押しながら左クリック)」というツールをインストールすると、BigQuery Browser Toolで、クエリを実行した際に、クエリ実行に何ドルないし何セント使ったのか、クエリ実行に要した時間と容量とともに表示してくれるようになります。また、標準では出来ない「クエリの保存」も行うことができます。
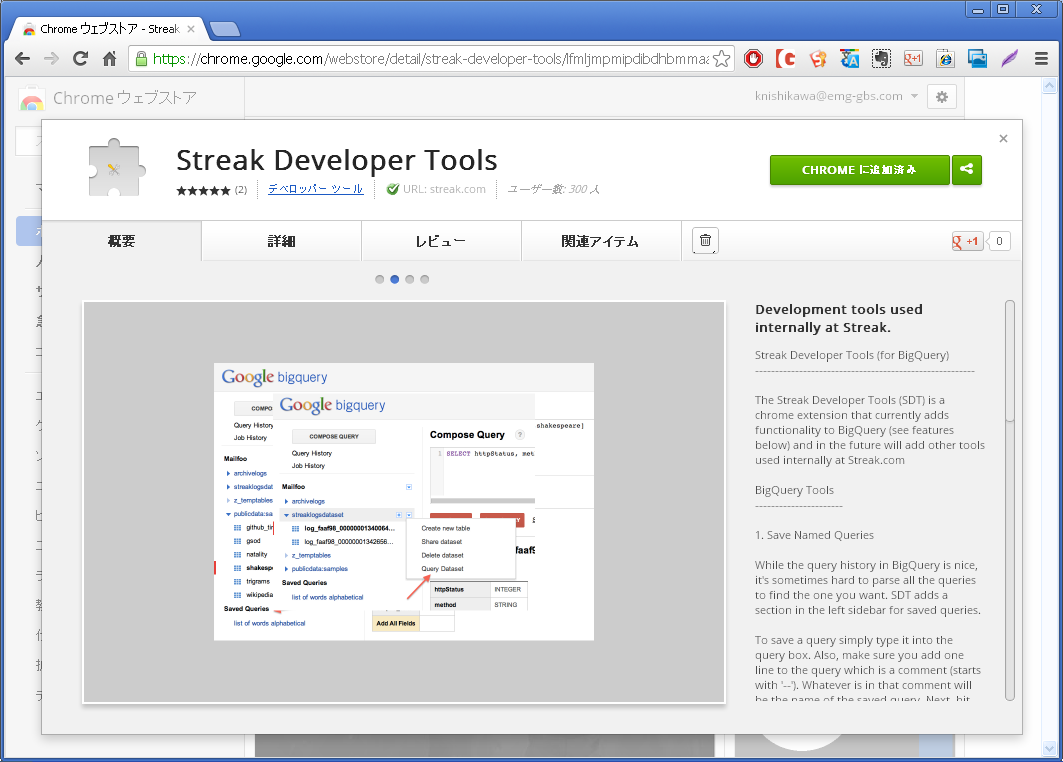
お使いのGoogle Chromeに、「Streak Developer Tools」をインストールしましたら、BigQuery Browser Tool の画面でクエリを実行してみましょう。
クエリ実行にかかった費用を表示する
元々付属しているサンプルデータからクエリを実行します。
- テーブルID:publicdata:samples.natality
- テーブル容量:21.9GB
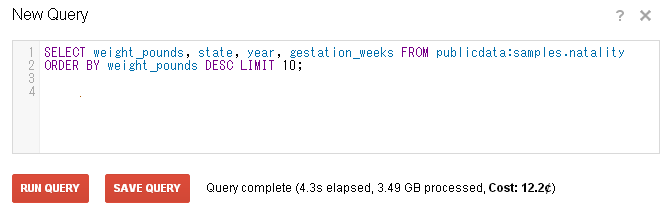
このテーブルに対して、クエリとして、「SELECT weight_pounds, state, year, gestation_weeks FROM publicdata:samples.natality ORDER BY weight_pounds DESC LIMIT 10;」とし、実行します。
Google Chromeに、「Streak Developer Tools」をインストールしたことで、通常は表示されないクエリ実行に要した費用を表示してくれます。但し、気をつけなければいけない点として、2012年11月現在、1¢(セント)未満は、0セントとして表示されてしまいます。費用が0.1セントであっても0セントと表示されますが、実態は、0セントということは無く、きちんと課金されています。
自分がどの程度のファイルにクエリを使ってアクセスしたか確認するには、Google APIs Cosoleの「Billing」という項目を参照するとわかります。Billing内の「Unbilled usage (estimate, updated daily)で表示される”Analysis”で毎日更新されている容量」に表示されている容量となり、ご契約されているものが「Google BigQuery Standard」であれば、
Analysisに表示されている容量 × USD 0.035/GB = 当月に課金されるクエリ費用
となります。なお、クエリの費用ですが、毎月100GBまで無料ですので、Google APIs Consoleの「Billing」は必ずGoogle BigQueryを使用する前にチェックしておくことをオススメいたします。
実行したクエリを保存し、再利用できるようにする
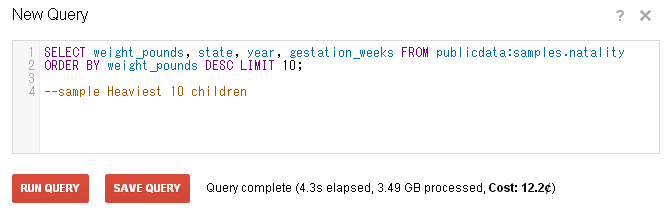
一度実行したクエリは、BigQuery Browser Tools 内の「Query History」に履歴として残されていますが、実行に失敗したものと一緒に履歴に残っていますので、クエリをお気に入りのように登録しておき、再利用し易くするために、「Streak Developer Tools」が役に立ちます。
クエリを実行し、問題なく結果が出た後に、クエリ内に、「--sample クエリ名(英数字, 半角スペース可)」で、追記し、画面内の「SAVE QUERY」をクリックしますと、画面左側の「Saved Queries」に保存されます。
保存されたクエリをクリックすると、画面右側に保存した内容のクエリが表示され、実行できますので、定型クエリや作業を中断する場合に重宝します。

また、保存したクエリを削除する場合は、保存したクエリ名の右側に表示される「▼」のアイコンをクリックすると表示が消えます。
Google BigQueryの費用計算のコツ
毎月のクエリの総費用 + ストレージ費用 = 請求費用 となります。
Google BigQueryには、Standard版とPremier版の2種類のエディションがあり、Premier版についてはGoogle社に要問合せですので、ここではStandard版の場合について解説いたします。なお、Premier版の場合でも考え方は同じです。
Goolge BigQueryのサービス概要では、
- クエリの総費用 = クエリ実行結果の各月の総容量 × クエリ実行回数 × USD 0.035/GB
- ストレージの費用 = Google Cloud Storageの各月の使用容量 × USD 0.12/GB
- クエリの総費用 + ストレージの費用 = 当月におけるGoogle BigQueryの利用料としての請求金額
このようになりますが、クエリ実行結果の容量を正確に計算することは一般的なスキルを所有する人には不可能に近いため、最も現実的な計算としては、Google BigQuery内のテーブル容量と予定しているクエリ実行回数、クエリ実行結果の容量 1GBあたりUSD 0.035 の3項目を乗算することになります。
たとえば、Google BigQuery内に、テーブルA(容量:5GB), テーブルB(容量:10GB)と予測します。
また、クエリの1ヶ月あたりの実行回数は、テーブルAで100回、テーブルBで100回と予測します。
この時、最初の月のクエリ総費用は、
- テーブルAのクエリ費用 = 5GB × USD 0.035/GB × クエリ100回実行 = USD 17.5
- テーブルBのクエリ費用 = 10GB × USD 0.035/GB × クエリ100回実行 = USD 35
と各自なりますので、これを合算すると、クエリ総費用 = USD 52.5 となります。
これでクエリの総費用がわかりました。次は、Google Cloud Storageの費用を算出します。Google Cloud Storageの費用 = (テーブルCの容量 + テーブルDの容量) × USD 0.12/GB = USD 1.8
最後に、クエリの総費用とGoogle Cloud Storageの費用を合算しますと、最初の月のGoogle BigQueryの請求費用は、クエリの総費用 + Google Cloud Storageの費用 = USD 54.3 となります。
クエリの実行結果の容量は、各テーブル容量を超えることはありません。よって、この計算方法で算出される費用は想定される最大値になり、実際の費用はその範囲内に収められます。また、テーブルの容量は毎月増えることが一般的ですから、増えたテーブル容量に対して、上記のロジックで計算すると、簡単で確実な見積りを行うことができます。
Google Cloud Storageを活用する
Webブラウザ上で、10MB以上のファイルをインポートし、テーブルを作成する場合は、Google Cloud Storageを利用する必要があります。既にGoogle BigQueryをお使いの皆様向けに、Google Cloud Storageの利用に関する資料を公開しております。こちらの資料をご覧ください。 (Ctrlキーを押しながら左クリック)
関連資料(出来れば目を通した方が良い)
BigQuery Browser Tool :Quick Start (原文, 英語のみ, Ctrlキーを押しながら左クリック)
Query Reference (英語のみ, Ctrlキーを押しながら左クリック)
API Overview(V2) Data Formats (英語のみ, Ctrlキーを押しながら左クリック)
BigQuery Browser Tool 操作デモの動画 (日本語, Ctrlキーを押しながら左クリック)
本資料についてのお問い合わせ先
ゼネラル・ビジネス・サービス株式会社 ソリューション事業部 Cloud-Solution担当 西川 浩平
E-mail:knishikawa@gbs.co.jp