## 모든 분들의 수정이 가능한 걸로 공유설정을 했었는데 구글 문서가 히스토리를 비교하기 어렵게 되어 있네요. 수정된 것을 찾으려면 전 문서를 다시 봐야 하는거 같아요. 위키문서로는 아직 기능이 풍성하지 않은 것 같습니다. 그래서 일단 댓글만 달 수 있는 것으로 전환했습니다. 불편하시더라도 댓글로 작성해 주시면 제가 추가하도록 하겠습니다 ###
윤종수(http://www.jayyoon.com)가 작성한 이 글은
크리에이티브 커먼즈 저작자표시 2.0 대한민국 라이선스에
따라 이용할 수 있습니다.

공공데이터의 개방과 과제
윤종수(Jay Yoon)
iwillbe99 at gmail.com
twitter : @iwillbe99
http://www.facebook.com/iwillbe99
목차
(1) 기계가독형 포맷(machine-readable format)#
(1) 코드 포 아메리카(Code for America)#
(2) 선라이트 재단 (Sunlight Foundation)#
I. 빅데이터 시대의 공공데이터
1. 빅데이터
빅데이터는 “보통 수십에서 수천 테라바이트 정도의 거대한 크기를 갖고, 여러가지 다양한 비정형 데이터를 포함하고 있으며, 생성-유통-소비가 몇 초에서 몇 시간 단위로 일어나 기존의 방식으로는 관리와 분석이 매우 어려운 데이터 집합”을 의미한다.[1] 위 정의에서 알 수 있듯이 빅데이터는 명확한 범주를 갖고 있다기보다는 공적·사적 영역에서 수집 되는 로우 데이터(Raw Data)의 어마어마한 양으로부터 기인한 새로운 현상을 지칭하는 것으로 보는 게 정확하다.
이 새로운 현상은 이른 바 3V로 설명된다.[2] 즉 일단 규모(Volume)가 커야 한다. 어느 정도 규모에 해당되어야 하는지는 명확하지 않지만 보통 수 테라바이트에서 수 페타바이트[3] 정도의 데이터 집합이면 빅데이터로 본다. 다음으로 다양성(Variety)이다. 단순히 규모만 크다고 해서 빅데이타로 분류하는 것은 큰 의미가 없다. 그 보다는 데이터의 다양성이 오히려 중요한 함의를 갖는다. 다양성은 다루어야 할 데이터의 형태가 매우 다양하다는 의미이다. 기존의 데이터들이 주로 특정 형식에 잘 맞추어 정리된 정형적·구조적(structured) 데이터들[4]이라 한다면 최근 다루어야 하는 데이터들은 그 보다는 비정형·비구조적(unstructured) 데이터, 즉 인터넷 뉴스나 온라인 커뮤니티의 게시물, SNS의 일상적인 대화부터 동영상, 음악, 사진 등 포맷이나 내용들이 제각각인 데이터들이 더 큰 비중을 차지한다.[5] 마지막으로 속도(Velocity)이다. 정보통신기술과 네트워크의 발전으로 데이터의 생성, 유통, 소비의 주기가 엄청나게 짧아진 특징을 갖는다. 특히 실시간(realtime) 데이터의 비중이 커지고 있다. 이 세 가지 특징, 즉 규모(Volume), 다양성(Variety), 속도(Velocity)를 어느 정도 만족할 때 비로소 빅데이터라 부를 수 있다.
이 세 가지 특징은 빅데이터가 무엇인지 파악할 때 핵심적 요소가 되지만 다른 한편으로는 왜 빅데이터가 유용한 것인 지에 대한 유력한 근거가 되기도 한다. 즉 데이터의 규모(Volume)가 커지고 이를 다룰 수 있는 처리, 분석기법이 발달하면서 데이터에서 뽑아낼 수 있는 가치는 높아지고 오류와 왜곡은 오히려 줄어들게 된다. 다양성(Variety) 역시 새로운 가능성을 제공한다. 최근 SNS(Social Network Service)를 분석하여 선거 결과를 예측하거나 트렌드를 잡아내듯이 과거의 구조적 데이터에서는 한계가 있었던 다양한 요소들이 처리, 분석됨으로서 좀 더 유용한 단서를 끄집어 낼 수 있게 되었다. 여기에 실시간 분석이 가능한 속도(Velocity)라는 특징이 더해지면서 과거에는 불가능하였던 빠른 대응과 정확한 결과 도출이 가능해진다. 빅데이터가 새로운 기술이나 개념이 아니고 마케팅 용어에 불과하다는 비판이 전혀 틀린 소리는 아니지만, 엄청난 규모, 다양성, 실시간적인 속도의 특징을 갖는 데이터들의 집합이 그러한 특징 때문에 사회적·경제적으로 큰 가치를 갖게 되는 것에 주목하였다는 점에서는 분명 의미가 있다.
2. 공공데이터
가. 빅데이터로서의 공공데이터
데이터의 생산이나 수집, 보유 측면에서 공공부문, 특히 정부의 비중은 거의 독보적이라 할 수 있다. 정부의 업무수행 과정에서 또는 특별한 목적에 따라 생성되거나 수집 되는 데이터는 국민의 모든 생활과 연관되어 있으며 그 중요성이나 민감성에서 사적 영역에서 수집 되는 데이터를 능가한다.[6] 빅데이터의 효과를 단기간내에서 얻을 수 있는 분야가 바로 공공부문이라는 지적도 바로 그점에 근거한다. 교통문제, 환경문제, 치안문제, 에너지문제, 실업문제 등 해결해야 할 산적한 문제들이 쌓여 있는 공공분야에서 빅데이터 처리 및 분석을 통해 효율적인 성과를 끌어내는 것 자체가 바로 공공부문, 정부의 역할과 직결되기 때문이다. 공공분야에서의 빅데이터 역시 기술의 문제라기 보다는 공적 이슈에 대한 새로운 해결책을 찾기 위해 빅데이터의 특성에서 기인하는 효용성을 활용하기 위한 임무로서 인식해야 한다. 즉 개개의 부서 뿐만 아니라 범정부 차원의 정책결정에서 좀더 개선된 결과를 얻고 생산성을 높이는데 빅데이터의 처리와 분석을 활용한다는 의미이다.
미국에서는 오바마 정부가 201년 봄부터 공공분야에서의 빅데이터 리서치 프로그램을 가동하기 시작했고[7] 2012년 10월경에는 단순한 연구가 아닌 실질적인 프로젝트 수행을 위한 정부 내의 빅데이터 프로젝트 로드맵을 발표하였으며,[8] 과학기술정책실의 주도로 빅데이터의 연구개발조정과 이니셔티브 확보를 위해 협의체인 ‘빅데이터 고위운영그룹(Big Data Senior Steering Group)’이 구성되었다.[9] 국내에서도 국가정보화전략위원회와 방송통신위원회, 행정안전부, 교육과학기술부, 지식경제부가 공동으로 '스마트국가 구현을 위한 빅데이터 마스터플랜'[10]을 마련한 바 있다.
나. 공공데이터의 특수성
공공데이터가 빅데이터와 밀접한 관계를 갖고 있음은 확실하다. 그러나 공공데이터와는 그 본질상 일반적인 빅데이터과는 약간 다른 맥락을 갖는다.
우선 가시성(Visibility)의 문제이다. 뒤에서 보는 바와 같이 전통적으로 공공데이터의 핵심적인 이슈는 공개(open)의 문제였다. 행정정보를 포함하는 공공데이터에 대한 국민의 접근(access)이 알권리 측면에서 쟁취해야 될 핵심적인 가치였고 그 정당성과 공개범위를 둘러싼 국민과 정부의 줄다리기가 지금까지 계속되고 있다. 사실 공공데이터에서 규모(Volume)는 정부가 과거에나 지금이나 사회 구성 주체 중 가장 덩치가 큰 단일 주체라는 점을 고려하면 공공부문에서 생성되고 보관되는 데이터의 양이 과거에도 그 규모의 측면에서 상당했으리라는 점은 쉽게 예상할 수 있으므로 새삼스러운 일은 아니다. 뒤에서 보는 바와 같이 빅데이터 시대에 들어와 공공데이터가 접근성의 차원을 넘어 혁신의 재료라는 측면에서 각광을 받게 되었지만 여전히 공공데이터의 가치는 규모(Volume)보다는 가시성(Visibility)에 달려있고, 공공데이터의 규모는 가시성의 성취에 따라 비로소 실질적인 의미를 갖는다. 다시 말해 빅데이터에 의한 혁신의 가능성이 데이터를 수집하고 보유하는 주체에 의한 처리와 분석능력에 의하여 실현된다고 한다면, 공공데이터는 데이터를 수집하고 보유하는 주체에 의한 데이터의 개방과 모든 시민의 참여, 활용여부에 따라 혁신의 가능성이 실현될 수 있다는 점에서 차별된다.
두번째는 다용성(Versatility)의 이슈이다. 비정형 데이터가 다수를 차지하는 일반적인 빅데이터와 달리 공공데이터는 구조적 데이터가 대부분을 차지한다. 주로 행정의 수행과정에서 생성되거나 취득되는 데이터들이므로 대게 일정한 규칙에 따라 수집되고 정해진 서식에 따라 관리되는 데이터들이기 때문이다. 따라서 빅데이터의 핵심적 특징이자 유용성의 근거가 되는 다양성(Variety)은 공공데이터에서는 그다지 두드러지지 않는다. 그 보다는 폭넒은 이용, 상위 및 하위 호완성(backward and forward compatibility), 상용제품으로부터의 독립성을[11] 의미하는 다용성(Versatility)이 의미를 갖는다. 뒤에서 보는 바와 같이 기계가독형(machine readable) 데이터이어야 하고 검색과 소팅(sorting)이 가능해야 하며 비독점적이거나 오픈소스 소프트웨어와 연결된 포맷이어야 한다. 공공데이터는 공개와 재이용, 매쉬업(mash-up) 등을 통해 투명성과 혁신성을 끌어내는데 중점이 주어지고 이를 위해 데이터의 품질과 활용성을 극대화시켜야 하기 때문이다.[12] 따라서 다용성을 보장하는 비독점적인 오픈 포맷의 채택이 공공데이터가 갖추어야 할 필수적인 조건이 된다(이에 관해서는 뒤에서 다시 상술한다).
결국 공공데이터를 굳이 3V로 표현한다면 빅데이터와는 달리 가시성(Visibility), 다용성(Versatility), 속도(Velocity)가 될 것이다.
II. 오픈 데이터로서의 공공데이터
1. 오픈 데이터(Open Data)
오픈 데이터(Open Data)[13]는 오픈 콘텐츠(Open Contents),[14] 오픈소스 소프트웨어(Open Source Software)와 같이 정보재의 개방을 추구하는 일련의 움직임 중 하나로서 데이터에 대한 자유로운 접근과 재이용, 재배포가 보장되어야 함을 의미한다. 문서의 연결과 공유를 기저에 깔고 있는 인터넷과 웹의 등장으로 더 주목을 받게 되었지만 오픈 데이터는 사실 학술 내지 과학 분야에서는 꽤 오래된 이슈[15]이다. 2004년 OECD 국가의 과학부장관들이 모여 공공펀드에 의하여 아카이빙된 데이타들의 공개를 결의하였고, 2007년에는 ‘공공펀드에 의한 리서치 데이타의 접근을 위한 OECD 원칙과 가이드라인(OECD Principles and Guidelines for Access to Research Data from Public Funding)’[16]을 공표한바 있다. 2005년 시작된 사이언스 커먼즈(Science Commons)[17]는 CC(Creative Commons)[18]의 주요 프로젝트 중 하나로, 과학, 학술 분야에서 좀 더 빠르고 효율적인 리서치가 가능하도록 불필요한 장애의 제거를 위한 정책 가이드라인과 법적인 합의를 이끌어내고 데이터의 검색 및 활용을 용이하게 하는 기술을 개발하는데 그 초점을 두고 있다. re-useful(재사용을 위한 정보 공개), one-click(효율적 프로세스로 정보에 대한 빠른 접근), integrating(정보 체계화 및 통합)을 기본 정책방향으로 삼아, 정보의 공개와 권리의 명시, 효율적인 프로세스에 의한 빠르고 쉬운 연구, 정보 체계화에 의한 용이한 분석을 통해 서로가 상호 보완하여 시너지 효과를 거둘 수 있는 생태계를 구축하려 한다.[19]
과학영역 외에 오픈 데이터가 지지를 받는 대표적인 주요 영역이 정부가 보유하고 있는 공공데이터이다. 과학데이터의 공개 논의가 주로 과학연구에서의 효율적인 리서치라는 실용적인 이유에서 나온 것이라면 공공데이터의 공개는 현실적·법률적·정책적 이유가 복합적으로 작용된 결과라 할 수 있다.
2. 공공데이터의 개방
가. 행정정보공개제도
공공데이터는 정보공개법의 차원에서 행정정보공개제도의 일환으로 개방 논의가 시작되었다. 스웨덴이 1766년 ‘출판의 자유에 관한 헌법 법률’에서 정보공개제도에 관한 규정을 둔 것이 최초라고 할 수 있는데, 근대적 의미의 정보공개법은 미 연방정부가 1966년 제정한 ‘정보자유법(Freedom of Information Act)[20]에서 비롯되었다. 정보자유법은 정보공개청구제도에 의한 정보공개뿐만 아니라 행정기관의 능동적인 공표의무도 규정하고 있어 통합적인 정보공개법의 형태를 갖추고 있다.[21]
국내에서는 대법원이 “국민의 알 권리, 특히 국가정보에의 접근의 권리는 우리 헌법상 기본적으로 표현의 자유와 관련하여 인정되는 것으로 그 권리의 내용에는 일반 국민 누구나 국가에 대하여 보유·관리하고 있는 정보의 공개를 청구할 수 있는 이른바 일반적인 정보공개청구권이 포함되고”[22]라고 하여 ‘공공기관의 정보공개에 관한 법률(이하 ‘정보공개법’이라고 한다)’이 제정되기 전부터 소극적인 권리로서의 알권리 뿐만 아니라 적극적인 권리로서의 정보공개청구권, 특히 그 중에서도 일반적인 정보공개청구권이 인정됨을 명백히 하였다. 이해관계를 전제로 하지 않는, 즉 개인의 자유로운 인격발현에 필요하거나 유용한 정보를 넘어서는 공공기관의 일반적 정보의 공개를 모든 국민이 청구할 수 있는 권리[23]라는 의미에서의 일반적 정보공개청구권의 헌법적 근거가 무엇이냐에 대해서는 다소 이견이 있었는데 1996. 12. 31. 정보공개법이 제정되면서 법률상의 권리로 학립되게 이르렀다.
나. 인터넷 시대의 공공데이터의 개방
(1) 오픈 데이터 개념으로의 확대
공공데이터의 개방은 인터넷 시대에 들어와 새로운 국면을 맞이하게 된다. 즉 알권리에 기반한 행정정보공개로서의 공공데이터의 개방은 민간에 의한 공공데이터의 재이용이라는 개념으로 확장되기 시작한 것이다.
인터넷의 효과적인 이용을 선거전략에 사용했던 오바마 대통령은 취임 직후인 2009. 1. 21. 정부의 투명성을 제고하고 참여와 협업을 위한 시스템 구축을 요구하는 첫 번째 행정명령인 ‘Memorandum for the Heads of Executive Departments and Agencies on Transparency and Open Government’[24]을 발령했다. 그후 대통령의 지시를 받은 OMB(Office of Management and Budget)의 디렉터는 각 부처에게 위 각서의 이행을 위한 구체적인 행동을 요구하는 행정명령인 MEMORANDUM FOR THE HEADS OF EXECUTIVE DEPARTMENTS AND AGENCIES,[25]이른 바 Open Government 명령을 발령하였다. 이에 따라 공공데이터 포털인 data.gov가 구축되었고 열린 정부 대쉬보드(Open Government Dashboard)에 의해 각 부처의 데이터 공개현황을 관리하고 있다. 2012. 5.경에는 “디지털 정부 : 미국민에 더 나은 서비스를 제공하기 위한 21세기 플랫폼 구축(Digital Government : Build a 21st Century Platform to Better Serve The American People)” 보고서를 발표하여 모바일기기를 통한 정부서비스 접근성 향상을 강조하면서 공공데이터의 개방이 전 국가에 걸쳐 혁신을 자극하고 공공서비스의 품질을 올리는 방법임을 다시 한번 확인한 바 있다.
영국은 2007년 6월 ‘정보의 힘(Power of Information)’ 보고서를 발표하여 이를 기초로 공공데이터의 개방을 시작하였고, 2010년 웹의 아버지인 팀 버너스리(Tim Berners-Lee)를 책임자로 하여 공공데이터 포털인 data.gov.uk를, 2012년 5월에는 오픈 데이터 연구소(Open Data Institute)를 개설한 바 있다. 시맨틱 웹의 주창자인 팀 버너스리의 주도하에 대부분의 데이타를 링크드 오픈 데이타(LOD, Linked Open Data)의 형태로 공개하고 있는게 특징이다. 한편 국제적으로는 오픈 데이터 이니셔티브(Open Data Initiative)를 만들어 공공데이터의 개방을 선도하고 있으며, 2011. 9.경 47개국과 오픈 거버먼트 파트너쉽(Open Government Partnership)[26]을 체결한 바 있다.
오픈 거버먼트[27]를 강력하게 추진하는 또 하나의 국가인 호주도 2009년 정부 2.0 태스크포스를 운영하여 보고서를 발표한 이래 공공데이터의 개방을 강력하게 추진하고 있으며 공공데이터 포탈인 data.gov.au. 를 운영하고 있다.
(2) 공공데이터 개방의 함의
공공데이터를 활용하여 경제적 가치를 만들어내고 혁신을 추구하고자 하는 시도는 위에서 보는 바와 같이 2000년 대 후반이 되서야 본격적으로 등장하였지만, 이미 세계 주요국가들로 전파되면서 21세기 정부의 주요 아젠다로 부각하고 있다.
이러한 변화는 크게 4가지 요소의 결합으로 이해할 수 있다.
행정정보공개제도
정보공개의 원칙을 천명하고 열람 및 사본 복제물의 교부와 정보통신망에 의한 정보의 제공을 규정하고 있는 ‘공공기관의 정보공개에 관한 법률’은 공공데이터 개방의 근거가 되는 기본법으로서 역할한다. 비록 적극적인 공공정보의 활용보다는 국민의 접근권 보장이라는 측면에서 입법된 전통적 의미에서의 정보공개를 다룬 것으로, 정보공개청구에 대한 처리규정의 성격을 띠고 있을 뿐 사전적· 적극적 공개제도는 마련되어 있지 않은데다가, 제9조에서 규정하고 있는 비공개대상정보에 다른 법률 또는 위임 명령에 의해서 비밀 또는 비공개로 처리 할 수 있는 것을 포함하는 등 그 예외 규정이 포괄적이고 명확하지 못하다는 면에서 공공정보의 적극적 개방을 위한 법률로서는 다소 부족하기는 하지만 국민의 헌법상의 권리를 구체화한 법률로서 공공데이터 개방의 기초가 되고 있다. 행정정보는 세금으로 생성되고 수집되는 것이니 만큼 모든 납세자에게 개방되어야 한다는 기본원리 역시 공공데이터의 경우에도 그대로 적용될 수 있다.
웹 2.0 (Web 2.0)
웹 2.0의 본질을 ‘인터넷 상의 사람들과 기업들이 수동적인 서비스 이용자가 아니라 능동적 표현자로서 인정받고 적극적으로 관계를 맺게 하는 기술과 서비스 개발 자세’라고 한다면, 모두에게 공평하게 열려있는 공간으로서의 웹에서 아마존이나 구글과 같이 자사의 데이터나 서비스를 공개하여 불특정 다수가 이를 기반으로 새로운 서비스를 구축할 수 있게 하는 구조가 바로 웹 2.0이다.[28] 웹 2.0의 핵심적 키워드인 ‘플랫폼으로서의 웹’은 바로 이점을 지칭해서 하는 말이다. 공공데이터의 공개와 시민의 참여를 내용으로하는 새로운 정부의 패러다임을 정부 2.0으로 부르는 이유도 여기에 있다. 즉 정부 2.0은 정부 서비스와 웹 2.0을 결합한 것으로, 정부 및 공공부문에 웹 2.0의 문화와 기술을 적용함으로써 구현되는 새로운 정부서비스를 지칭한다. 정부는 국민들이 스스로 필요한 서비스를 만들 수 있도록 재료와 툴을 제공하는 플랫폼형 정부가 되고, 국민은 단지 정부 서비스를 수동적으로 이용하는데 그치는 것이 아니라 직접 정부의 기능에 참여하고 공공서비스를 만들어 내는 적극적 기여자가 되는 것이며, 이를 매개하는 것이 공개된 공공데이터이다. 따라서 웹 2.0이 플랫폼으로서의 웹이라는 도구와 자유로운 접근과 이용자에 의한 가치추가가 가능한 데이터라는 재료의 두 가지 요소로 이루어진 것처럼, 정부 2.0도 플랫폼으로서의 정부라는 도구와 자유로운 접근과 국민에 의한 가치추가가 가능한 공공데이터라는 재료가 핵심요소가 된다. 이러한 도구와 재료에 의해 정보기술을 이용한 공공서비스 개발에 국민들의 적극적인 참여가 이루어지고, 매쉬업을 거쳐 공공부문의 데이터와 민간부문의 데이터 또는 민간부문의 서비스가 서로 통합되고 연결됨으로써 새로운 차원의 서비스가 가능해지는 것이다.[29]
오픈소스(Open Source)
오픈소스는 수정과 재배포가 가능하고 소스코드의 공개를 조건으로 하는 자유이용 라이선스의 적용을 받는 소프트웨어인 오픈소스 소프트웨어에서 유래된 용어이다. 보통 오픈소스라고 하면 오픈소스 소프트웨어를 의미하나 최근에는 개인들의 참여와 민주적이고 투명한 프로세스에 의한 효율적인 개발방법론을 응용해서, 소프트웨어 개발이 아닌 다른 영역에서 그러한 형태로 진행되는 프로세스 내지 그 프로세스에서 사용되는 소재 또는 결과물을 지칭하는 의미로 널리 사용되고 있다. 즉 오픈소스는 단순히 소프트웨어의 개발방법이 아니라 인터넷 시대의 작업방법으로서의 원리를 의미한다. 오픈소스 작업방식은 누구나 재이용할 수 있게 재료를 공개하고, 참여자들은 다양한 환경에서 다양한 방식으로 자신이 원하는대로 재료를 주물러 새로운 결과물을 만들어 내고 그 결과물을 공개하는 것을 의미한다. 오픈소스 작업방식이 다른 영역으로 퍼져가는 이유는 소프트웨어의 개발분야에서 오픈소스 방식의 위력을 실감하였기 때문이다. 오픈소스 방식은 잘 계획되고 통제된 환경보다 더 혁신적으로 빠르게 문제점을 고치며 그럼으로써 이용자를 만족시키는 성과를 얻을 수 있게 한다. 공공데이터의 개방도 바로 오픈소스 방식의 성과를 기대하는 것이다. 서비스의 재료인 공공데이터를 모두에게 개방한 후 스스로의 판단 하에 빠르게 움직이는 다수의 참여에 의한 혁신으로 공공서비스의 패러다임을 바꾸고자 하는게 공공데이터의 역할이다.
빅데이터
앞에서 살펴보았듯이 공공데이터는 빅데이터와 밀접한 관련이 있다. 엄청난 규모, 다양성, 실시간적인 속도의 특징을 갖는 데이터들의 집합이 데이터 본래의 가치를 넘어 새로운 사회적·경제적 가치를 창출한다는 빅데이터의 원리는 공공데이터 역시 단지 알권리의 대상이나 필요한 행정정보를 알려주는 역할에 그치지 않고 새로운 가치화 혁신의 원천이 될 수 있으므로 이를 적극 공개하여 혁신적이고 창의적인 시민의 참여로 가치를 끌어내보자 하는 것이 공공데이터의 개방에 깔린 의도이다. 공공데이터는 국민들의 일상적인 삶과 밀접하게 연결이 되어 있다. 따라서 그 어느 데이터보다 의미가 있는 공공데이터가 일반으로부터 분리된 채 그 잠재성을 발휘하지 못하는 것은 합리적인 이유를 찾기 어렵다. 빠르게 변화하는 빅데이터시대에 있어 시대에 뒤떨어진 데이터 정책은 국민으로부터도 호응을 얻기 어렵기 때문에 공공데이터는 개방되어야 하는 당위성을 갖게 된다.
다. 공공데이터 개방의 효과
(1) 투명성의 확보
투명성의 확보는 공공데이터 개방으로 성취가 기대되는 가장 기본적인 효과이다. 종래의 정보공개청구권에 따른 공공데이터의 소극적 공개제도 역시 투명성의 증진에 기여하나, 적극적·일반적 공개제도, 특히 ‘공개를 하지 못할 특별한 사정이 없는 한 전부 공개’라는 의미의 원칙적 공개는 정부와 행정의 투명성을 극대화 한다. 적극적 공개제도는 정보공개권의 행사와 그 처리에 소요되는 비용을 절감케 하고 복잡한 절차를 단순화 시킨다. 예산관련 자료, 지출관련 자료, 정부수행 평가자료, 인사자료 등 시민들이 알고 싶어하는 자료를 우선적으로 공개하고, 더 나아가 이를 사람뿐만 아니라 기계가 읽을 수 있는 형식(machine and human readable format)으로 공개한다면 정부와 행정의 투명성을 효율적으로 담보할 수 있다.[30] 데이터의 공개와 동시에 정부업무수행의 주요 현황을 시민들이 알기 쉽게 대쉬보드(dashboard) 형태로 함께 구현한다면 제일 바람직하다.[31] 업무공개나 정보공개에 익숙치 않은 경우 투명성의 추구는 상당히 부담스러운 작업임은 사실이나, 투명성으로 얻게 되는 이점도 크다. 비록 공개로 인해 데이터의 일부 오류가 드러나고 그로 인해 얼마 동안 질책을 받을 수 있겠지만 시간이 지날수록 긍정적 반응이 따라오게 된다. 공개를 전제로 데이터를 구축하기 시작하면 데이터의 질적 향상도 자연스럽게 얻어진다.
데이터의 공개는 데이터의 존재와 소재를 명확하게 함으로써 공공기관과 공무원에게도 업무상의 편의를 제공한다. 정부 조직내의 부처들 사이, 또는 공무원들 간의 정보공유와 협업 역시 데이터가 공개될 수록 원활하게 이루어진다. 특히 상당수의 사안들은 한가지 측면이 아닌 각 부처의 관장업무가 얽혀있는 복합적인 경우가 많은 바 공개된 데이터는 각 부처와 공무원 사이의 참여와 협업의 매개체 역할을 한다. 부처 간의 정보공유는 성숙한 전자정부의 가장 핵심적인 과제로 계속 추진되어 왔다. 전자정부법 제4조는 전자정부의 원칙으로 행정정보의 공개 및 공동이용의 확대(제1항 제5호). 중복투자의 방지 및 상호운용성의 증진(제1항 제6호)을 들고 있고 제36조에서는 행정정보의 공동이용을 촉구하고 중복투자를 금지하고 있다. 그럼에도 만족할 만한 수준으로 실질적인 정보공유가 이루어지고 중복투자방지 역시 제대로 효과를 보았다는 평가를 받지 못하고 있는 바, 공공데이터의 개방 확대는 자연스럽게 그 돌파구의 역할을 할 것으로 기대된다.
(2) 참여민주주의의 실현
오바마 정부의 열린 정부 구현을 위한 최고기술관리보(DCTO)를 역임한 베스 시몬 노벡(Beth Simone Noveck)은 그녀의 저서 ‘위키정부 : 기술은 어떻게 정부를 개선하고 민주주의를 강화하고 시민에게 권력을 분할할 수 있는가’[32]에서 네트워크 시대의 참여민주주의에 대해서 설파하고 있다. 그녀는 참여민주주의의 유형을 직접민주주의, 심의민주주의, 협력민주주의로 나눈 다음 버튼 하나로 특정한 상황에서의 복잡한 결정을 구조화하는 것은 불가능하다는 이유로 인터넷 시대에도 직접민주주의는 실현되기 어려우며, 대규모집단에서의 심의민주주의는 단지 의사결정에 간접적으로만 관계되는 토론에 그치고 실제 권력과의 연결고리는 끊어져 있다는 이유로 그 실효성을 의심한다. 결국 네트워크시대에 실현가능한 민주주의를 기술의 중요성을 인정하고 의사결정과 결과물의 효과성에 중점을 두는 참여민주주의에서 찾는다. 참여민주주의는 오픈소스 프로젝트와 같이 문제를 쪼개어 작은 단위로 나눈 다음 참여하기를 원하는 소수의 마이크로 엘리트들이 전문성을 기초로 자신의 분야를 찾아 서로 다른 방식으로 기여할 수 있도록 함으로써 협업에 의한 문제해결을 꾀하는 것이다.
베스 시몬 노벡이 말하는 협력민주주의는 공공데이터의 공개가 기대하는 네트워크 시대의 가장 이상적인 정치적 혁신이다. 웹 2.0 적인 기술과 문화 그리고 네트워크는 종래에는 불가능 했던 “각자의 곳에서, 각자 잘 할 수 있는 것을, 각자의 방식으로” 협업하는 것을 가능하게 한다. 개발자나 전문적 지식이 없더라도 웹 2.0 적인 참여와 공유에 친하다면 충분히 기여가 가능하다. 수요자 중심의 주민참여형 지도정보를 만들어가는 커뮤니티 맵핑(Community Mapping)[33]은 아무런 기술이 없는 시민들도 문제해결에 기여할 수 있음을 잘 보여준다. 온라인 디지털 환경은 손쉽게 협력하고 효율적인 업무배분을 가능하게 해주기 때문이다. 물론 모든 문제가 그러한 작은 단위의 자유로운 협업에 의해서 해결될 수 있는 것은 아니다. 하지만 많은 문제들은 제대로 협업을 디자인한다면 충분히 해결할 수 있을 것으로 보인다. 효율적인 업무배분과 실효성 있는 협업은 우리가 전혀 예상하지 못한 다양한 영역에서 일어나는 웹 2.0의 작은 기적들을 보여줄 것이다. 우리가 아직 가장 효율적인 민주주의에 대한 답을 찾지 못하였다면 그건 민주주의와 시민의 역할을 너무 무겁게 생각했기 때문일 수도 있다. 네트워크 시대의 협력민주주의의 핵심은 가벼운 디자인과 작은 것부터의 참여이다. 아직 낯설겠지만 정부는 이러한 가벼운 디자인에 익숙해질 필요가 있다. 그리고 가벼운 디자인에 익숙해지는 가장 효율적인 방법은 목적과 목표를 신중하게 선정한 다음 적합한 공공데이터를 적절한 포맷으로 개방하고 참여를 기다리는 것이다.
(3) 혁신의 성취
공공데이터의 공개는 투명성과 시민의 참여를 증진시킬 뿐만 아니라, 그에 따른 성과로 민간 또는 공공부문이 당면한 문제를 해결하고, 실생활에 유용한 어플리케이션을 제공해주며, 민간과 공공 양쪽 모두에서 시간과 비용의 절감을 가져오기도 한다. 서울버스 앱이 처음 나왔을 때 그 편의성과 효용에 감탄해 마지 않았던 경험은 공공데이터의 개방이 어떤 혁신을 가져올지 처음으로 깨닫게 해주었다. 이러한 조그만 혁신들이 축적되면서 전국가에 미치는 경제적 효과 또한 기대되는데, 국내 공공데이터의 개방으로 인한 경제적 효과는 2011년 기준 생산유발액 23조 9천억 원, 부가가치유발액 10조 7천억 원, 고용유발인원 14만 7천명으로 추산된다고 한다.[34] EU의 경우에도 공공데이터의 개방으로 인하여 EU 27개 회원국 전체에 미치는 직접적 경제적 효과를 연간 400억 유로(약 60조 원), 간접적인 경제효과까지 포함하면 연간 1,400억 유로(약 210조 원)로 전망하고 있다.[35] 공공데이터의 개방이 공공부문과 밀접하게 관련이 있는 투명성과 민주주의의 실현에 그치지 않고 시민생활 자체나 민간경제에 도움을 줄 수 있다는 사실은 정부의 역할을 전혀 다른 차원에서 바라봐야 함을 의미한다. 즉 정부는 단지 행정의 주체로서가 아니라 적극적이고 능동적인 시민들의 참여와 전문가 그룹 그리고 정부조직이 한 플랫폼위에서 움직이는 생태계를 만들어 나가는 혁신가가 될 것을 요구받고 있는 것이다.
라. 공공데이터 개방을 어렵게 하는 장해요소
(1) 개방의 효용성에 대한 부정적 인식
공공데이터의 개방에 대한 소극적인 자세는 어찌보면 자연스러운 일일 수도 있다. 데이터의 개방에 대한 부담, 망설임은 투명성에 대한 일반적인 두려움에서 비롯된다. 투명성을 증진시킬 데이터의 공개는 다른 의미에서는 실수나 오류가 여지없이 드러날 가능성을 의미하기 때문에 공개를 하고자 하는 주체의 입장에서 보면 여간 부담스러운 일이 아니다. 더구나 애초에 개방을 전제로 하지 않고 구축, 관리되어 온 데이터는 정확도 등의 품질이 떨어진다거나 오류가 제대로 걸러지지 않았을 가능성이 크고 이를 공개 전에 제대로 손을 보기도 사실상 힘들어서, 저품질의 부정확한 데이터에 대한 책임추궁이나 비난에 대한 위험부담을 안고 가야하는 문제가 있다. 설사 데이터의 품질에 문제가 없다고 하더라도 공개된 데이터에 터잡은 시민들의 참여는 정부 입장에서는 번거로운 간섭, 감시 또는 새로운 요구로 받아들여질 수 있다. 또한 데이터를 보유하던 부처나 공무원의 입장에서는 데이터의 공개는 정보 독점의 상실에 따른 부처의 위상이나 업무담당자의 권한이 축소되는 것으로 받아들여질 수 있기 때문에 개방에 대한 소극적 태도는 더 두드러지게 된다. 아무리 정부 고위층에서 정치적 결단을 내려 전격적인 공공데이터의 개방이 결정된다고 하더라도 실제 담당공무원 차원에서 이런 부정적인 인식이 개선되지 않을 경우 공공데이터의 개방은 형식에 그칠 가능성이 크고 의도된 효과를 제대로 얻기 힘들 것이다.
개방에 대한 부정적인 인식 외에도 데이터 공개를 부수적인 업무로 취급하거나 단지 기술적인 차원에서 접근하는 경우에는 역시 마찬가지 결과로 이어질 수 있다. 데이터 공개는 원래의 업무에 부가적으로 더해지는 것이 아니라 기존 업무의 패러다임을 바꾸는 것으로 이행되어야 한다. 따라서 데이터의 생성, 수집 단계에서부터 데이터 공개를 전제로 프로세스가 마련되어야 하며, 전체적으로 봤을 때 추가적인 업무부담이 생기지 않도록 최대한 자동화된 프로세스를 채택할 필요가 있다. 따라서 기존의 업무에 라이선스 설정 및 제한, 정보요청 및 심사절차 등 추가적인 절차를 자꾸 부가하는 형태로 제도가 마련될 경우 효율성은 저하되고 담당자의 부담은 커지므로 공공데이터의 개방은 자꾸 뒤처지게 된다. 또한 데이터의 개방을 IT 부서의 업무에 국한하는 기술적인 사안으로 인식하게 되면 전체 업무의 패러다임 전환은 이루어지지 않고 중복투자로 인한 예산낭비로 끝날 가능성이 크다.
(2) IT 인프라와 왜곡된 개발 생태계
우리나라의 전자정부[36] 수준은 상당히 높은 것으로 평가된다. 중앙정부의 공공서비스 제공을 위한 정보통신서비스의 수준을 측정하는 종합적 지표인 UN 전자정부발달지수(e-Government Development Index)[37]에서 2005년 5위, 2008년 6위를 거쳐 2010년부터 줄곧 1위에 랭크되어 있다. 그러나 이러한 고도의 전자정부 수준이 오히려 공공데이터의 개방에 장애가 될 수 있다. 기존의 전자정부 시스템은 전형적인 자판기형 정부라 할 수 있다.[38] 즉 정부가 예산을 투입하여 서비스를 기획, 구축한 다음 마치 자판기에 상품을 배열하는 것처럼 서비스를 제공하여 국민들이 원하는 서비스를 선택, 제공받을 수 있게 해왔다. 아래 그림에서 보는 바와 같이 우리나라는 국가기간망 구축을 시작으로 그동안 기반시설인 네트워크 구축과 함께 전자정부서비스의 고도화에 많은 투자를 해왔고 그 결과 국민들에게 수준 높은 전자 행정서비스를 제공할 수 있게 되었음은 틀림없다.
문제는 우리가 그러한 기존의 자판기형 전자정부 구축방식에 익숙해져 있는데다가 그에 맞추어 모든 ICT 개발 프로세스와 개발 생태계가 확고하게 형성되어 있는 점이다. 정부가 예산을 투입해서 국민이 원하는 서비스를 직접 기획, 구축하는 방식에 익숙해져있는 상황에서는 공공데이터 개방을 통해 민간에서 필요한 서비스를 직접 만들어 낸다는 웹 2.0 적인 개념 자체를 쉽게 받아들이기 어렵다. 더구나 각 부처의 전자정부 수준의 평가가 국민들에 대한 전자 행정서비스의 양과 질로 판단되어 오고 있기 때문에 각 부처 입장에서는 기존의 평가기준에 의한 업무패턴을 반복할 수밖에 없다. 공공데이터의 개방에 대한 새로운 흐름이 등장한 이후에도 각 부처가 거액의 예산을 들여 직접 모바일 앱을 만들었고 그 활용도가 극히 낮아 예산의 낭비라는 지적을 들었던 사례[39]도 그와 같은 매락에서 이해할 수 있다. 오히려 기존의 전자정부 수준이 낮은 경우에는 공공데이터의 개방을 통한 공공서비스의 창출에 더 적극적일 수 있다. 예산절감과 함께 부족한 인프라를 보완해 줄 수 있기 때문이다. 아프리카의 케냐에서 오픈 데이터 정책을 적극적으로 시행[40]하여 정부의 투명성과 함께 사회, 경제적 성장을 끌어내려고 하는 시도가 그 예라 할 수 있다.
또한 지금까지의 ICT 개발 프로세스에 따라 구축된 공고한 생태계는 공공데이터의 개방과 시민의 참여라는 새로운 방식에 어떤 형태로든 반발할 가능성이 크다. 국내 공공부문의 ICT 용역은 대게 턴키 계약으로 진행되어 왔다. 턴키 계약은 기획, 조사, 설계부터 개발, 이관까지 전부 한 업체가 맡아서 하는 계약이다. 분리발주제도가 마련되어 있음에도 실질적인 이행이 제대로 되지 않는 이유는 여러가지가 있겠지만 주된 이유는 발주자가 업무별로 분리발주를 줄 수있는 능력이 안 되기 때문이다. 다시 말해 이미 모든 개발을 턴키 계약에 의한 아웃소싱으로 처리해온데다가 인원감축 등에 의하여 공공기관 내부에서 이를 관리할 수 있는 능력을 갖춘 인력이 없기 때문에, 정해진 일정을 준수하고 적절한 비용 범위내에서 업무를 수행해주는 기업에게 일괄하여 용역을 주게 된다. 발주자 입장에서는 사업을 총괄하는 한 업체와만 계약을 하고 관리를 하면 되고 문제가 생겨도 책임 추궁이 쉽기 때문이다. 한번 용역을 주게 되면 업무방식에 서로 익숙해지므로 같은 업체에게 반복해서 용역을 주기도 한다. 이런 식의 계약체결이 반복되다 보니 전문적으로 공공부문에 개발용역을 제공하는 업체들이 생기고 나름대로의 생태계가 생기게 되는데, 이들 입장에서는 계속적인 새로운 대형 시스템의 구축과 추가적인 용역에 이해관계가 크므로 시민의 참여에 의한 솔류선의 제공이라는 새로운 방식의 등장은 달갑지 않은 일일 수밖에 없다. 굳이 안좋은 시나리오를 생각해보면, 이들 업체는 전통적인 방식으로 개발이 계속되도록 시스템을 종속적으로 만들고 담당공무원을 설득 하는 등 지위를 공고히 하기 위한 작업을 할 가능성이 크고, 담당 공무원 역시 종래의 방식이 훨씬 수월한 면이 있으므로 공공데이터의 제공에 의한 어플리케이션의 개발방식을 선호하지 않을 가능성이 크다. 이러한 시나리오는 제3자 입장에서 언급하기 조심스러운 부분이기는 하나 충분히 가능성이 있다. 게다가 관련법과 내부규정은 유연한 시스템 개발 방식의 채택을 어렵게 만들기도 한다.
(3) 시민참여문화의 부족
데이터의 공개는 공개 그 단계에서 끝나는 것이 아니라 그 이후의 이용과 재활용, 그로 인한 경제적, 사회적 혁신을 끌어내는데에 진정한 의미가 있다. 따라서 공공데이터에 대한 시민의 관심을 끌어내고 적극적인 시민의 참여와 활용을 유도하는 것이 모든 정책의 최우선적인 고려가 되어야 하고 그래야만 의도한 효과를 얻을 수 있다. 문제는 공공부문의 경험과 문화가 그러한 시민과의 협업 내지 시민의 적극적 참여를 조장하는 것과는 거리가 있었다는 점이다. 사실 국내 공공부문의 역량과 자질은 어느 나라보다 우수하다고 평가된다. 관료조직은 경제발전 초기에 중요한 위치를 차지했으며 국내 IT 산업을 견인함에 있어서도 결정적인 역할을 한 바 있다. 하지만 그러한 경험에서 굳어진 업무 프로세스는 관 주도의 업무추진에 집중되어 왔고 정책결정에 있어 시민들을 참여시키거나 시민 주도로 문제 해결을 시도하는 경우는 찾아보기 힘들었다. 시민들 역시 그러한 경험이 적었기 때문에 정부와의 거리가 있었고 정부 내의 사정이나 업무 프로세스에 대해서도 정확한 정보를 갖지 못하였다.
비영리 단체인 CC Korea[41]가 2011. 8. 경 호주 정부 2.0 태스크포스 보고서의 번역서를 출간하면서 그중 100권을 공무원에게 보내기로 하고 이를 꼭 읽어봤으면 하는 공무원을 시민들로부터 추천 받은 사례[42]가 있었다. 책을 보내기로 한 이유는 시민들의 자발적 참여로 이루어진 번역서를 공무원에 보내어 업무에 참고가 되게 함으로써 이왕이면 참여와 소통의 정부 2.0을 책출간부터 실현해보고자 했기 때문이다. 그 비용을 확보하기 위해 소셜펀딩을 진행하는 와중에 몇가지 부정적인 피드백이 있었는데 민간 쪽에서 나왔던 것은 왜 돈을 들여가며 효과도 없는 일을 하느냐는 지적이었다. 책을 보내봤자 아무런 소용이 없을 거라는 취지였다. 반대로 공공쪽에서 나왔던 반응은 마치 민간이 공공부문을 가르치려고 하는 것 같아 불쾌하다는 것이었다. 이 두가지 반응은 현재 시민과 공공부문의 관계에 있어 앞서 언급했던 문제점을 그대로 보여주는 것이라 할 수 있다. 시민참여문화의 미숙과 무경험은 상호간의 불신을 야기하고 이는 다시 시민과 공공부문의 협업, 행정에의 시민참여의 기회를 막게 된다. 이 불신을 걷어내고 협업과 참여의 경험을 계속 만들어나가지 않는 한 공공데이터 개방은 머뭇거리게 되고 그나마 제공된 공공데이터는 별다른 효과를 얻지 못할 것이며, 이는 다시 협업의 참여의 기회를 상실하게 만드는 악순환에 처하게 될 위험이 있는 것이다.
(4) 다른 법익과의 충돌
현재로선 정보공개법이 공공데이터의 개방의 구체적인 근거법으로 역할하므로 제9조[43]에서 정한 비공개대상정보에 대한 규정 역시 공공데이터의 개방에 적용된다. 뒤에서 보는 바와 같이 공공데이터의 제공 및 이용활성화에 관한 법률안도 위 규정을 원용하고 있다. 위 규정에 따르면 상당히 넓은 범위의 정보가 비공개정보로 규정되어 있고, 특히 대부분 불확정 개념이 포함되어 있어 경우에 따라서는 적용 범위가 넓어질 가능성이 크다. 적극적으로 청구를 구하는 청구인이 있는 정보공개청구에 따른 공개결정과 달리, 공공기관 스스로 공개를 결정하게 되는 공공데이터의 개방 절차에 있어서는 아무래도 위 비공개정보 규정을 더 많이 의식하게 될 가능성이 크다. 공공기관 입장에서는 갈등의 여지가 있는 예민한 공공데이터를 애써 스스로 공개하기는 부담이 크기 때문이다. 특히 제6호에서 이름, 주민등록번호 등 개인에 관한 사항으로서 공개될 경우 개인의 사생할의 비밀 또는 자유를 침해할 우려가 있다고 인정되는 정보를 비공개정보로 규정해놓고 이어서 공공기관이 작성하거나 취득한 정보로서 공개하는 것이 공익 또는 개인의 권리구제를 위하여 필요하다고 인정되는 정보를 다시 제외하고 있는데, 사실 공개에 대한 수요가 많은 공공데이터들 중에는 공익에 관계된 정보로서 누군가의 개인정보나 사생활의 비밀을 침해할 우려가 있는 정보일 경우가 많기 때문이다. 제7호에서 규정하고 있는 법인이나 개인 등의 경영정보나 영업정보에 관한 것들도 마찬가지이다. 이 경우에도 위법, 부당한 사업활동으로부터 국민의 재산 또는 생활을 보호하기 위하여 공개할 필요가 있는 정보는 다시 제외되기 때문인데 이 부분 역시 공개에 대한 수요가 많을 정보들이다. 약 2년 전 위생단속 정보를 이용한 어플리케이션이 처음 등장했을 때 호응이 컸으나 해당 업주들이 단속 결과에 문제가 있다며 강력하게 항의를 하는 해프닝이 있었던 사안을 생각해보면 충분히 예상할 수 있을 것이다. 범죄발생정보를 지도와 매쉬업을 하는 어플리케이션은 다른 나라의 경우 공공데이터 활용의 대표적인 사례[44]인데 인근 주택의 가격하락을 우려하는 주민들의 저항을 두려워하면 역시 제3호의 국민의 생명, 신체 및 재산의 보호에 현저한 지장을 초래할 우려가 있다는 규정에 기해 비공개가 될 우려도 있다.
비공개범위의 판단은 그동안 축적된 심판례와 판례들이 참고가 될 것이나, 공공데이터의 개방은 이전의 정보공개청구보다 한걸음 더 나아가는 것이니 만큼 과거보다 좀더 전향적인 자세가 필요하다는 견해도 귀를 기울일만하다. 투명성의 확대는 종종 이전에는 걱정하지 않아도 되었던 사태를 우려하게 만들고 실제 관련자들의 이해관계에 영향을 미치기도 하므로 신중할 필요가 있다는 견해도 일응 납득은 가나 그렇다고 해도 이를 너무 의식하고 소극적인 자세로 나아간다면 변화의 기회를 놓칠 수 있다는 점을 잊지말아야 한다. 예를 들어 지역의 범죄발생정보가 공개되면 그에 대한 지역사회의 관심과 함께 발생을 억제하려는 노력이 이어질 수도 있기 때문이다. 그러나 법익간의 충돌 문제는 해결이 쉽지 않은 이슈이고, 자주 경험하게 되는 이익형량의 문제니 만큼 일률적으로 말하기는 힘들다. 그렇기 때문에 오히려 공공데이터의 공개에 부정적으로 작용할 가능성이 크다. 이에 대한 사회적 합의를 어떻게 만들어 나갈지, 담당공무원과 사법부의 판단이 어떻게 전개될지에 따라 공공데이터의 개방도 전혀 다른 그림을 그리게 될 것이다.
III. 국내 공공데이터 개방의 현황[45]
1. 중앙정부
2010. 6. 국가지식포털 내에 공공정보개방 및 활용과 관련된 공공-민간의 다양한 애로를 지원하는 것을 목적으로 공공정보 활용지원센터가 설치되어 공공정보목록 안내서비스와 공공정보 신청안내 등의 서비스를 시작하였다. 그러나 각 부처의 소극적인 자세와 데이터의 관리가 제대로 이루어지지 않아 실효성 있는 서비스를 제공하지 못한다는 평가를 받았다. 2011. 7. 공공데이터 포털인 국가공유자원포털(htp://data.go.kr)이 설치되어 공공데이타 제공서비스가 시작되었는데, 최근 국가공유자원포털에 국가지식포털이 통합되는 등 국가정보자원 개방, 공유체계를 전면적으로 개편하는 내용의 국가정보자원 개방, 공유체계 구축의 완료가 발표된 바 있다.[46] 그에 따르면 국가통계정보, 생활기상정보, 농수축산 가격정보 등 14개 기관, 100개의 서비스, 386개의 오퍼레이션으로 이루어진 10종의 공유서비스가 개발되었고, 국가법령정보, 항공운행정보, 산악안전정보 등 12종의 타기관에 의한 24개 서비스, 457개의 오퍼레이션이 연계되었으며, 경기도 버스정보, 국민권익위의 국민정보, 국회도서관 학술정보 등 기 구축된 13개 기관의 105개 서비스, 362개의 오퍼레이션이 고도화 되었다고 한다. 현재 총 16,497,972건의 데이터 링크와 84,509건의 데이터 원문, 총 241개의 오픈 API를 제공하고 있어 일단 외형적인 면에서는 상당한 성장을 이룬 것으로 보인다. 그 밖에 요약 DB적용 및 튜닝으로 응답속도를 개선하였으며 동적 정보제공에 따른 실시간 업데이트, 통합검색제공, 기관별, 분야별 공공정보 보유, 개방, 이용현황을 도식화하여 제공하는 등 여러 기능을 추가하였다.
2. 지방정부
서울시를 제외하고는 지방정부 중 공공데이터의 개방에 두드러진 성과를 보이는 곳은 별로 없는 것으로 보인다. 서울시는 2010년 경부터 보유 콘텐츠의 CCL(Creative Commons License) 적용과 함께 공공데이터 개방을 위한 현항파악과 개방에 따른 기술적, 법률적 검토를 진행하였다. 현 시장 취임 이후 공공데이터의 개방이 적극적으로 추진되어, 2012. 5, 공공데이터 포털인 ‘서울 열린 데이터 광장(http://data.seoul.go.kr)’의 시범서비스를 시작한 이래 고도화 작업을 계속하여 왔다. 최근 2013. 2. 26. 서울 열린 데이터 광장이 대폭 개편되었는데, 현재 서울 열린 데이터 광장을 거쳐 제공되고 있는 데이터넷은 총 1,026건이며, 데이터 서비스는 1,594건으로 그중 338건이 오픈 API이다. 본청 외에 6개의 투자·출연기관의 공공 DB를 포함하고 있다. 카달로그 서비스를 신설하여 서울시가 제공하는 공공데이터 외에 행정안전부 등 타기관의 목록토 통합제공하고 있다. 눈에 띄는 것은 공공데이터 활용성 극대화를 위하여 데이터 성격에 따라 오픈 API, 파일, csv 등 복수의 형태로 서비스를 제공하기 시작한 점이다. 또한 시민제안과 개선의견을 올릴 수 있는 공간과 소셜 댓글 서비스를 제공하고 있으며 서울 공공데이터를 활용한 사례를 소개할 수 있는 소개 페이지를 개설했다. 소통, 협력, 참여의 열린 시정 2.0을 모토로 내걸고 서울 열린 데이터 광장에 이어 정보소통광장(http://gov20.seoul.go.kr)도 개설하였는데, 이 곳에는 행정정보공표, 웹콘텐츠, 전자결재문서, 비정형문서 등이 공개되어 있다.
IV. 공공데이터 개방의 확산을 위한 방안
1. 법제도의 정비
가. 공공데이터 개방의 법제화
공공데이터의 개방은 개별 부처 차원에서의 결단이나 담당공무원의 의지만으로 해결되지 않는다. 공공데이터의 개방은 그 이후의 책임이 따르는 문제이고 국유재산 또는 공유재산의 관리라는 측면에서도 고려해야 하는 만큼 개별 단위에서 결정하기가 쉽지 않다. 가사 책임자의 리더쉽으로 공공데이터 개방이 이루어졌다고 해도 이를 제도적으로 확고하게 정착시키지 않으면 지속적인 정책추진이 보장되기 어렵다. 따라서 공공데이터 개방 정책의 명확한 법제화는 반드시 필요하다.
공공데이터의 개방과 관련된 현행법으로는 앞서 본 정보공개법과 2009. 5. 2. 지식정보자원관리법,정보화촉진기본법, 정보격차해소법 등이 폐지, 통합되어 새롭게 제정된 국가정보화기본법이 있다. 국가정보화기본법은 제18조에서 ‘지식, 정보의 공유, 유통’이라는 제목 하에 “국가기관 등은 국가정보화의 추진을 통하여 창출되는 각종 지식과 정보가 사회 각 분야에 공유, 유통될 수 있도록 필요한 기반을 마련하여야 한다”고 규정하고, 시행령 제17조로 국가기관 등에게 “지식 및 정보의 공유, 유통 기반을 마련하기 위하여 해당 기관이 보유하고 있는 정보를 국민이 편리하게 검색, 활용할 수 있도록 할” 의무 등을, 시행령 제23조로 중앙행정기관의 장과 지방자치단체의 장에게 “정보공개법 제9조 제1항 단서에 따라 공개하지 아니할 수 있는 정보를 제외하고는 저작권법 등 관련 법률에서 보호하고 있는 권리가 침해되지 아니하는 범위에서 국민이 정보통신망을 통하여 지식정보자원을 전자적인 형태로 이용할 수 있도록 노력”할 의무를 부과하고 있다. 지식, 정보의 공유, 유통에 대한 정부의 의무 등을 천명하였다는 점에서 일응 의의가 있으나 공유, 유통의 절차나 방식, 조건 등에 대해서 아무런 규정이 없어 공공데이터의 무조건적인 적극적 개방을 뒷받침하기에는 부족하다. 시행령 제23조가 정보공개법에서 한 걸음 더 나아가 정보의 적극적 공개를 노력할 것을 요구하고 있는 것으로 해석할 수 있는 여지는 있으나 그나마 그 대상을 지식정보자원[47]에 한정하고 있어 충분하지 못하다.
그밖에 전자정부법 제12조가 행정정보를 인터넷을 통하여 국민에게 제공할 의무를 부과하면서 제13조에서 행정정보로 인하여 특별한 이익을 얻는 자가 있는 경우에는 수수료를 부과할 수 있다는 규정과 함께 그 절차 등에 관하여 규정하고 있다. 역시 공공데이터의 원칙적인 공개원칙이 천명되었다기는 보기 어렵고 공개의 구체적인 절차나 방식에 대한 규정이 없어 실효성이 있는 규정이라고 보기는 힘들다.
개별법으로는 통계법이 통계결과의 지체없는 공표, 신속 편리한 이용을 위한 데이터베이스의 구축 등을 규정하고 있지만, 이 역시 예외 규정의 범위가 넓고 특정 대상에 대한 수량적 정보작성, 학술연구 등에 한정되며 통계자료의 이용제공신청을 하면 타당성심사를 거쳐 제공하는 방식으로 되어 있어 공공정보의 적극적 활용으로는 한계가 있다
나. 공공데이터의 제공 및 이용활성화에 관한 법률안
2012. 5. 31. 김을동 의원이 대표발의자로 된 ‘공공데이터의 제공 및 이용 활성화에 관한 법률안(이하 법률안이라고만 한다)’이 제출되어 2012. 9. 17. 행정안전위원회 전체회의에 상정된 바 있다.[48] 위 법안은 그동안 공공데이터 개방을 위하여 논의되어 온 여러가지 쟁점에 대해 두루 규정을 두고 있어 여러모로 의미가 있다. 아직 입법이 되지는 않았지만 쟁점들과 함께 살펴 볼 가치가 있어 이하에서는 그 주요 내용에 대해 검토를 해보기로 한다.
(1) 공공데이터의 제공
법률안 제2조 제2호는 공공데이터의 정의를 ‘공공기관이 생성 또는 취득하여 관리하고 있는 광(光) 또는 전자적 방식으로 처리되어 부호, 문자, 도형, 색채, 음성, 음향, 이미지 및 영상 등(이들의 복합체를 포함한다)으로 표현된 모든 종류의 자료 또는 정보’로 정의함으로써 국가지식정보화기본법이 그 대상을 지식정보에 한정한 것과 달리 가공된 정보나 지식이 아닌 행정과정에서 생성, 취득되는 사실로서의 모든 공공데이터를 포괄하도록 규정하고 있다. 공공데이터를 디지털 데이터로 명확히 한정한 것도 눈에 띄는데 공공데이터 개방의 목적상 디지털 데이터가 주 대상인 것은 명확할 뿐더로 현 정자정부 환경하에서 거의 모든 데이터가 디지털로 관리되고 있는 점을 고려하면 큰 문제는 없을 것으로 보이나, 좀더 명확하게 하기 위해 특별한 사정이 없는 한 아날로그 데이터의 디지털로의 전환의무를 공공기관에 부과하는 것도 고려해볼 필요가 있다. 전자정부법에서 행정기관 등의 문서를 전자문서를 기본으로 하도록 하고 종이문서의 감축방안을 마련하도록 규정하고 있으며 정보통신기술에 적합한 업무재설계를 요구하고 있어 간접적인 효과를 얻을 수 있기는 하지만 좀 더 명확한 의무부과가 바람직하다.
법률안 제3조는 기본원칙을 규정하고 있는데, 공공기관에게 공공데이터의 이용권의 보편적 확대를 위한 필요한 조치의무를 부과하고, 공공데이터에 관한 국민의 접근과 이용에 있어서의 평등의 원칙의 보장과 함께 정보통신망을 통하여 일반에 공개된 공공데이터에 관하여 정당한 사유없는 이용자의 접근제한이나 차단 등의 이용저해행위 등을 금지하고 있다. 공공데이터 이용에 관한 전반적인 원칙을 규정한 것으로 보이나 공공데이터의 개방원칙이 명확하게 천명되었다고는 보기 어렵다. 제4조 제2항에서 이 법에서 정한 사항 이외에 공공데이터의 제공 등에 관하여 정보공개법에서 정하는 바에 따르도록 규정하고 있어 정보공개법의 정보공개의 원칙(동법 제3조)이 적용되고 동법 제18조에서 “공공기관은 보유, 관리하는 공공데이터를 제공하여야 한다”[49]고 규정하여 공공데이터의 제공의무를 부과하고 있기는 하지만 앞서 본바와 같이 그 단서로 정보공개법의 비공개대상정보 등을 제공에서 제외하고 있는바, 정보공개법의 경우 비공개정보의 범위(동법 제9조)가 너무 광범위하고 추상적 개념으로 인해 명확하지 않다는 비판을 받은 바 있고 실제 그 규정을 근거로 공공데이터 공개에 소극적 태도를 취해왔던 점을 고려하면 아쉬운 점이 있다. 정보공개법의 정보공개범위와 이 법률안의 공공데이터 제공범위가 같이 갈 수밖에 없는 한계가 있는 것은 것은 사실이다. 하지만 정보공개법이 공공데이터의 적극적 공개가 요구되는 변화된 환경이 도래하기 전의 법이라는 점을 고려하면 이 기회에 공공데이터의 제공 범위를 좀더 적극적으로 포섭해서 정보공개법의 비공개대상정보에 대한 범위를 재검토하도록 할 필요가 있다.
기본원칙에서 눈에 띄는 것은 제4항에서 “공공기관은 법률 또는 정당한 사유에 의하지 아니하고는 공공데이터의 영리적 이용인 경우에도 이를 금지 또는 제한하여서는 아니된다”라고 규정하여 영리적 이용의 허용을 원칙으로 하고 있다는 점이다. 공공데이터의 영리적 이용에 대해서는 의외로 부정적 견해가 자주 눈에 띈다. 공공데이터를 이용한 가장 인기있는 모바일 앱 중 하나인 서울버스 앱의 운영자가 서버운영비를 충당하기 위해 광고를 붙였다가 국민의 세금으로 만든 공공정보를 이용해서 돈벌이를 한다는 비판을 받아 철회를 했던 사례[50]에서 볼 수 있듯이 민간에서도 이에 대한 부정적 의견이 상당수 존재한다. 하지만 공공데이터의 영리적 이용은 공공데이터로 돈을 버는 것이 아니라 서비스제공자가 공공데이터를 기반으로 창조한 새로운 가치를 제공하여 돈을 버는 것이라는 점에서 영리적 이용에 대한 부정적 시각은 재고될 필요가 있다. 공공데이터에 대한 사용료를 내고 라이선스를 받아 영리행위를 하는 것이 오히려 공공정보에 대한 모든 이의 활용기회를 빼앗고 공공데이터 자체에 대한 가치를 독점하는 것이며, 누구든지 활용할 수 있는 공공데이터를 활용해서 수익을 얻을 수 있다는 것은 다른 이가 제공하지 못한 새로운 편의와 가치를 제공하였다는 의미이므로 혁신의 창조자로서 칭찬을 받을 일이기 때문이다. 그런 점에서 영리적 이용을 원칙으로 한 위 규정은 아주 큰 의미가 있다.
(2) 전담 부처
법률안 제5조는 공공데이터에 관한 정부의 주요 정책과 계획을 심의, 조정하고 그 추진사항을 점검, 평가하기 위하여 대통령 소속으로 공공데이터전략위원회를 두는 것으로 되어 있다. 공공데이터전략위원회는 공공데이터의 개방에 관한 기본계획 및 시행계획의 수립, 변경, 공공데이터의 제공 및 이용과 관련된 정책, 법, 제도 개선에 관한 사항등을 심의하는데, 그 중에서도 의미가 있는건 공공기관으로 하여금 해당 공공기관의 공공데이터를 등록하도록 의무를 부과하고 공공데이터전략위원회로 하여금 등록한 공공데이터 제공대상이 되는 공공데이터 목록을 심의, 의결한 후 이를 행정안전부장관으로 하여금 종합하여 공표하도록 하고 이에 따라 각 공공기관의 장으로 하여금 목록이 공표된 공공데이터를 공공데이터 포털에 등록하도록 한 점이다. 공공데이터의 공개는 범정부적 차원의 문화와 관행의 변화를 이끌어내어야 하는 만큼 이를 효과적으로 수행할 수 있는 리더쉽이 없는 한 불가능하다. 따라서 개별 부처에 모든 부담을 주는 것보다는 공공데이터의 정책을 전담하면서 각 공공기관에 대하여 리더쉽을 발휘할 수 있는 기관을 설정하는 것이 필요하다. 이런 점에서 공공데이터전략위원회는 공공데이터의 개방에 관한 최고 심의, 의결기관으로서 그와 같은 리더쉽을 발휘할 것으로 기대할 수 있다. 정보공개법이 정보공개여부의 결정을 각 공공기관에 맡기고 단지 각 기관 내에 소속공무원 또는 외부전문가등으로 구성된 정보공개심의회를 설치하여 부분적으로 심의절차를 거치도록 함으로써[51] 실질적으로는 해당 공공기관의 공무원에게 공개여부를 판단하게 하였고 이는 결국 소극적인 공개로 이어지게 되었다는 비판이 있는데 이에 비하면 진일보한 방식이라 판단된다. 과거 경험에 비추어 볼 때 위원회 형식의 조직이 실질적인 추진력을 가질 수 있을지에 대해서 부정적인 전망도 나올 수 있으나 각 부처를 총괄하는 지위를 가져야 하는 만큼 일단은 적절한 구조로 보인다. 다만 추진력이 확보될 수 있도록 집행부처인 안전행정부와의 관계, 예산의 확보, 제재 수단의 마련 등이 필요할 것으로 보인다.
다만 한가지 고려해야 될 점은 개인정보보호기구와의 관계이다. 특히 2011. 9. 30.부터 시행된 개인정보보호에 관한 일반법인 ‘개인정보보호법’에 설치된 개인정보보호위원회와의 관계가 문제될 수 있다. 개인정보보호와 공공데이터의 개방은 동전의 앞뒷면과 같은 관계에 있다. 물론 앞서 본 바와 같이 공공데이터의 비공개 사유는 개인정보보호에 한정되지 않지만 정보의 공개와 관련해서 제일 큰 걸림돌이자 자주 이슈가 되는 것은 개인정보보호 문제임은 틀림없다. 따라서 개인정보보호위원회의 개인정보보호범위에 대한 심의 의결과 공공데이터전략위원회의 개방범위에 대한 심의 의결이 충돌하는 경우도 충분히 상정할 수 있다. 예를 들어 위 법안이 공공데이터 개방의 예외로 삼고 있는 정보공개법의 비공개대상정보로 당해 정보에 포함되어 있는 이름, 주민등록번호 등 개인에 관한 사항으로서 공개될 경우 개인의 사생활의 비밀 또는 자유를 침해할 우려가 있다고 인정되는 정보를 규정하면서 다시 그에 대한 예외로 공공기관이 공표를 목적으로 작성하거나 취득한 정보로서 개인의 사생활의 비밀과 자유를 부당하게 침해하지 않는 정보나 공공기관이 작성하거나 취득한 정보로서 공개하는 것이 공익 또는 개인의 권리구제를 위하여 필요하다고 인정되는 정보 등을 규정하고 있는데 그 내용이 불확정개념으로서 판단 주체에 따라 결론이 달라질 수 있다. 정보공개법에서는 그 판단 주체가 개별 공공기관이었으므로 개인정보가 포함된 정보공개여부에 대해서는 개인정보보호의 최고 심의, 의결 기관인 개인정보보호위원회의 결정이 우선한다고 볼 수 있을 것이다. 그런데 위 법안에 의한 공공데이터전략위원회와 개인정보보호법에 의한 개인정보보호위원회는 모두 최고 심의, 의결기관으로서 대통령 소속의 독립위원회이다. 따라서 유사한 위상과 업무 형태를 갖는 두 위원회의 결정이 서로 충돌될 경우 이를 어떻게 조정해야 될지 애매할 수 있으므로 이에 대한 입법적인 해결이 필요하다.
그러나 더 근본적인 문제는 사실상 같은 결과를 초래하는 두 위원회의 업무가 별개로 추진되는 경우 효율성의 측면이나 균형성의 측면에서 부정적인 평가를 받을 수 있다는 점이다. 정보보호와 정보공개는 결국 같은 의미라는 점을 고려하면 한 기관이 모든 법익과 가치, 효과를 종합적으로 고려하여 일관되고 균형있는 판단을 내리는 것이 더 바람직하다고 볼 수 있기 때문이다. 호주 정부가 정보공개법을 개정하면서 총괄기구인 정보감독관(Information Commissioner)제도를 둔 것도 이런 측면에서 이해할 수 있다. 호주의 정보감독관은 정보자유법, 프라이버시, 기타 공공정보관리보고에 관한 세가지 임무를 모두 수행하며, 기존의 정보자유법 감독관(FOI Commissioner)은 정보자유법 업무외에 프라이버시 업무를, 프라이버시 감독관(Privacy Commissioner) 역시 프라이버시 업무외에 정보자유법 업무를 수행하도록 하고, 이 셋을 한팀으로 해서 범정부적인 정보관리라는 목표를 능동적으로 추진하도록 하고 있는 바 많은 시사점을 준다.[52]
(3) 공공기관 및 공무원의 책임제한 및 평가
아무리 제도적으로 공공데이타의 개방을 추진한다고 하더라도 결국 공공데이타를 보유하고 있는 공공기관과 그 업무를 처리하는 담당공무원의 적극적 참여 없이는 공공데이터의 개방을 끌어내기는 쉽지 않다. 그중에서도 공무원의 참여를 끌어내는 것이 중요한데, 공공기관의 내부의 문화적 변화나 공공데이터의 개방이 실제 공공기관 내부에도 긍정적인 효과를 미친다는 인식의 변화도 공공데이터의 적극적인 개방을 끌어 내는데에 기여하겠지만 단기적으로는 불안요소의 제거와 적절한 인센티브의 제공이 좀더 효과적일 것이다. 특히 공공데이터의 공개에 따른 결과에 대해서 담당공무원의 책임을 감면하는 정책이 필요하다. 앞서 언급한 바와 같이 공공데이터의 개방을 망설이는 이유 중 하나는 개방으로 인해 자칫 부담하게 될지도 모를 책임에 대한 걱정이다. 데이터의 품질이 떨어진다거나 데이터의 오류가 걸러지지 않아서 발생하는 이용자의 손해에 대한 책임추궁이나 비난은 굳이 공개해봤자 얻을 건 없고 위험부담만 늘어난다는 인식을 가지게 해 소극적인 태도를 취하게 만든다. 하지만 데이터의 품질을 걱정해서 개방을 머뭇거리는 것은 오히려 데이터 품질의 향상 기회를 놓치게 되는 결과가 된다. 개방을 통한 시민의 참여를 통해 데이터의 개선을 가져 올 수 있기 때문이다. 따라서 평소 데이터의 품질을 높이고 오류를 최소화하는 노력도 필요하겠지만 그럼에도 불구하고 발생하는 문제에 대해서는 좀더 넓게 면책을 인정해 줄 필요가 있다.
위 법안은 제34조 제1항에서 “공공데이터의 제공에 관하여 해당 공공기관 및 그 소속의 공무원 및 임직원은 데이터의 품질, 제21조에 따른 목록의 제외, 제29조에 따른 공공데이터 제공중단 및 업무상 사유의 공공데이터 일시적 제공중단 등으로 인하여 이용자 또는 제3자에게 발생한 손해에 대하여 민사상·형사상의 책임을 지지 아니한다”고 규정하고 같은 조 제2항에서 “해당 공무원 또는 임직원은 이 법에 따른 절차에 따라 성실히 직무에 임한 경우에는 「국가공무원법」 및 그 밖의 법령에 따른 불이익처분을 받지 아니한다”고 규정하여 공공기관 및 소속공무원의 면책에 대하여 규정하고 있다. 위 규정은 데이터의 제공 등에 따른 대내외적 책임을 면책시킴으로서 공무원들이 적극적으로 공공데이터의 개방에 나서도록 유도하고자 하는 것으로 보인다. 우선 내부적인 관계에서 볼 때 소극적인 불이익 처분의 면제를 규정하고 있는데 그 보다는 좀 더 적극적으로 인센티브를 부여하는 방안을 검토해볼 필요가 있다. 즉 보유한 공공데이터의 개방 및 활용 정도를 공무원의 업무수행평가에 중요한 측정요소로 삼도록 공무원의 평가체계를 정비하는 것이다. 위 규정대로 개방의 과정에서 발생할지 모르는 부작용에 대해서는 최대한 책임을 덜어주는 것뿐만 아니라 성과에 대해서 적극적으로 인센티브를 제공한다면 공무원들의 인식도 자연스럽게 바뀔 것이다. 위 법안 제9조는 행정안전부장관으로 하여금 매년 공공기관을 대상으로 공공데이터의 제공기반조성, 제공현황 등 제공 운영 실태를 평가하고 그에 따른 평가결과가 우수한 공공기관이나 공공데이터 제공에 이바지한 공로가 인정 되는 공무원 또는 공공기관 임직원을 전략위원회 위원장 및 행정안전부장관이 선정하여 포상할 수 있도록 규정하고 있는데 여기에 덧붙여 그러한 요소를 공무원의 평가체계에 정례화하고 공식화시킬 필요가 있다.
문제는 제1항에서 규정하고 있는 대외적인 면책규정이다. 위 규정은 문언상 고의나 중과실 여부를 가리지 않고 공공기관 및 공무원의 절대적인 면책을 규정하고 있는데 그 입법취지에는 공감할 수 있으나 이를 법률로 강제하는 것에 대해서는 국가배상법의 규정과 관련해서 법리상 문제가 있을 수 있고 국민들의 반발에 부딪힐 우려도 있다. 따라서 고의에 의한 손해(또는 중과실에 의한 손해도 포함해서)를 제외한 나머지 과실책임을 면책하거나 면책조항(disclaimer)을 활용하여 계약으로 해결하는 방법을 검토해 볼 필요가 있다.
다. 국유재산법과 공유재산 및 물품관리법의 개정
공공데이터의 개방을 위해서는 그 근거로서의 법제도의 마련도 필요하지만 다른 한편으로는 공공정보 개방의 걸림돌이 되는 법제도의 정비도 중요하다. 공공데이터의 개방을 어렵게 만드는 것으로는 앞서 본바와 같이 개인정보보호와의 충돌 문제도 있지만 공공데이터를 재산적 측면에서 규율하는 다른 법제도의 존재이다. 공공데이터가 저작물에 해당하는 경우에는 저작권이, 개개의 데이터는 저작물에 해당하지 않지만 그 편집물이 데이터베이스에 해당하는 경우에는 데이터베이스제작자의 권리의 대상이 되고, 이와 별도로 콘텐츠산업진흥법의 콘텐츠[53]에 해당되는 경우에는 콘텐츠제작자로서 보호받는다. 다만 배타적 권리가 아닌 경쟁사업자의 영업에 관한 이익의 침해를 금지하는 형태(동법 제37조)로 보호되고 있는 콘텐츠의 보호는 영업에 관한 이익을 인정하기 어려운 공공기관의 공공데이터에는 적용될 여지가 거의 없을 것이므로 저작권과 데이터베이스제작자의 권리가 선택적 또는 중첩적으로 적용될 수 있다. 그런데 국유재산에 관한 기본적인 사항을 정한 ‘국유재산법’이나 지방자치단체의 재산인 공유재산에 관한 법률인 ‘공유재산 및 물품관리법’은 그 재산 중 하나로 “특허권, 저작권, 상표권, 디자인권, 실용신안권, 그 밖에 이에 준하는 권리[54]”인 무체재산권을 포함함을 명백히 하고 있어 공공데이터가 저작권 또는 데이터베이스제작자의 권리의 대상이 되는 경우 국유재산법 또는 공유재산 및 물품관리법(이하 공유재산법이라고만 한다)의 적용을 받게 된다.
문제는 위 법률들이 대체로 목적 재산이 건물이나 토지와 같은 전통적인 유형물임을 전제로 하고 있어 비경합성을 갖는 무형의 지적 재산인 저작권의 처분과 관리에는 적합하지 않은 규정을 갖고 있다는 점이다. 즉 제3자에게 일정기간 유상이나 무상으로 사용, 수익할 수 있도록 허용하는 행위를 행정재산의 경우에는 사용허가(국유재산법 제2조 제6호, 공유재산법 제2조 제7호)로, 일반재산의 경우에는 대부계약(국유재산법 제2조 제7호, 공유재산법 제2조 제8호)으로 규정하고, 재사용, 수익허가나 재대부계약을 금지(국유재산법 제30조 제2항, 제47조 제1항, 공유재산법 제20조 제2항)하고 원칙적으로 일반경쟁에 부쳐 이용자를 정하도록 하고 있으며(국유재산법 제31조, 제47조 제1항, 공유재산법 제20조 제3항, 제29조 제1항), 유상을 원칙(국유재산법 제32조, 제47조 제1항, 공유재산법 제22조 제1항, 제32조)으로 하고 예외적으로 특정한 주체에 한해서 사용료를 면제(국유재산법 제34조, 제47조 제1항, 공유재산법 제24조, 제34조)할 수 있는 것으로 규정하고 있다. 이를 공공데이터에 적용하는 경우 공공데이타의 제공과 민간이용은 입찰에 의하지 않는 다수를 상대로 한 무상의 사용, 수익허가나 대부계약에 해당하게 되므로 위 규정을 위반하는 결과가 된다. 따라서 공공정보나 공공데이터의 개방을 위해서는 국유재산법과 공유재산법의 개정이 필요하다는 지적이 계속되어 왔다. 이에 따라 국유재산법이 2012. 12. 18. 법률 제11548호로서 개정돠어 2013. 6. 19.부터 시행될 예정인데, 저작권, 저작인접권 및 데이터베이스제작자의 권리 등은 저작권법에 따른 등록절차를 거친 경우에 한정함으로써 국유재산법의 적용범위를 제한하는 한편, 제4장의2로 지식재산 관리, 처분의 특례를 신설하여, 재사용허가 등을 허용(동법 제65조의7 제1항)하고 승인을 전제로 저작물 등의 변형, 변경 또는 개작을 허용(같은 조 제2항)하는 한편, 수의계약으로 다수에게 일시에 사용허가(동법 제65조의8 제1항)를 할 수 있도록 하고 지식재산을 공익적 목적으로 활용하기 위하여 중앙관서의 장 등이 필요하다고 인정하는 경우 감면을 할 수 있다(동법 제65조의 10 제2호)고 개정함으로써 공공데이터를 개방하는데 있어 법적 장애를 대부분 해결하였다. 다만 사용허가기간 또는 대부기간을 5년 이내로 정한 것은 실제 운용과 관련해서 실효성 없는 제한을 가할 우려가 있어 이에 대해서는 정비가 필요하다. 또한 공유재산법은 아직 개정이 이루어지지 않고 있어 문제가 계속 남아 있다. 위 공공데이터의 제공 및 이용활성화에 관한 법률안이 공공데이터의 무상 이용의 근거법률이라고 할 수 있어 위 법안이 통과될 경우 이로써 공유재산법의 규정을 대체할 수 있을 것으로 보이기는 하나 명확하지는 않다. 어찌되었든 위 법안의 결과와 상관없이 변화된 환경에 대응하는 공유재산법의 개정이라는 측면에서 국유재산법과 같은 방향으로 개정이 이루어지는게 바람직하다고 할 것이다.
2. 공공데이터 개방의 효용성 증대
가. 양에서 효과로
공개된 공공데이터의 양은 여전히 부족하고 이를 늘리기 위한 작업은 계속되어야 하겠지만 정책의 중점은 단지 제공목록의 수를 늘리는데 주어져서는 안된다. 공공데이터의 개방은 그 자체에 목적이 있는 것이 아니라 그로써 가능하게 된 사회적, 경제적, 정치적 변화에 궁극적인 목적이 있다. 따라서 데이터 개방의 성과는 얼마나 많은 데이터가 공개되고 얼마나 많은 데이타 셋 목록이 제공되느냐로 평가되는게 아니라, 공개된 데이터를 이용한 모바일 앱이나 솔류션들이 얼마나 많이 나오고 얼마나 많이 활용되었는지, 성취된 혁신과 변화가 무엇인지로 평가될 필요가 있다. 이용자 측의 공공데이타에 대한 불만 중 하나는 제공된 데이터 목록은 많지만 막상 활용하려고 하면 쓸만한 데이터가 없다는 것이다. 공공데이터에 대한 부정적 경험이 반복되다 보면 기대가 줄어들고 관심이 멀어질 수밖에 없다. 공공데이터의 제공이 민간의 수요를 만족시키지 못하는 이유는 공공데이터의 개방 초기인 만큼 공개에 적합한 데이터의 절대적인 수가 적어서 이기도 하지만 데이터 활용에 대한 명백한 그림 없이 제공된 공공데이터의 목록수를 늘리는데 급급하기 때문인게 가장 큰 이유로 설명된다. 공공데이터 개방은 먼저 데이터 개방의 목적과 목표가 명확하게 설정되어야 하며 그 이후의 추진에 있어서도 설정된 목적과 목표를 기초로 필요한 전략과 수단이 모색되어야 한다. 민간의 수요분석 및 명확한 목표설정, 수립된 전략에 따라 공공데이터가 제공될 때 비로서 민간에서 반응하기 시작하고 제공된 데이터를 이용한 사례들이 나오기 시작할 것이다. 별 의미없는 수십개의 데이터 셋보다 정말 유용한 하나의 데이터 셋을 다양한 방식으로 제공함으로써 그 효용성을 실감하게 하는 것이 공공데이터에 대한 인식증진과 참여를 끌어내는데 도움이 된다. 특히 지방정부에서는 작은 것이라도 그 지역에서 정말 필요로하고 도움이 될 수 있는 해결책에 집중해서 그에 맞는 데이터를 공개하는 것이 필요하다.[55]
이런 점을 고려하면 굳이 공공데이터의 목록수를 늘리기 위해 비공개 데이터의 공개작업에 인력과 예산을 무리하게 투입할 것이 아니라 이미 공개되어 있는 데이터를 활용하는 것이 더 효과적일 수 있다. 즉 이미 공개는 되어 있지만 눈에 띄지 않는 곳에 있거나 제공된 데이터의 형식상 가독이 힘들고 재활용이 불가능하여 공개되지 않은 것과 마찬가지인 데이터들을 발굴해서 아래에서 보는 바와 같이 오픈 데이터 포맷으로 바꾸거나 시각화하여 데이터 포털에서 공개하는 것만으로도 새로운 효과를 얻을 수 있다. 민간에서 관심이 많고 의미도 큰 데이터들은 이미 공개되었을 가능성이 크기 때문이다. 또한 공공데이터의 목록을 늘리는 과정에서도 민간의 관심과 참여를 처음부터 끌어내기 쉽고 실제 제공작업에서도 큰 어려움이 없는 데이터를 먼저 다루는게 바람직한데, 예산과 인사에 관한 데이터를 우선적으로 공개하고 이를 시각화하여 이해하기 쉽게 만든 다음 윤리적인 이슈를 담고 있는 데이터로 넘어가는 방식이다.[56] 이는 시민들에게 우선적으로 제공되어야 할 데이터는 시민들이 가장 알고 싶어하는 내용을 담고 있는 데이터이고 그것은 제공하는데 별로 어려움이 없지만 제공이 꺼려질 수 있는 데이터라는 점을 시사한다.[57] 결론적으로 데이터 공개는 공급자 측이 아니라 수요자 측의 기준에서 공개의 순서와 범위가 결정되어야 한다는 취지이다.
나. 오픈데이터 포맷의 준수
공공데이터의 개방에 있어서는 데이터의 내용도 중요하지만 데이터의 형식이 결정적인 역할을 한다. 오픈 데이터 포맷은 다소 기술적인 내용이기 때문에 비전문가, 특히 공공기관의 종사자들이 그 중요성에 대해 간과하기 쉽지만 단순한 기술적, 형식적 의미에 그치는 것이 아니라 데이터의 활용 수준을 좌우하는 핵심적인 요소이다. 그래도 최근에는 포맷의 중요성에 대한 인식이 확대되고 기술적으로도 많이 지원되고 있지만 아직 미흡한 사례들이 발견되고 그것이 개발자들을 포함한 시민들의 참여를 막고 있어 이에 대한 개선이 시급하다.
(1) 기계가독형 포맷(machine-readable format)[58]
공공데이터의 제공에 있어 저지르기 쉬운 실수는 제공 이후의 이용과 활용을 생각하지 않고 PDF나 hwp와 같이 재활용이 어려운 포맷으로 공개하는 것이다. 이는 데이터 공개의 목적과 목표 설정, 그에 따른 프로세스의 채택, 공개 후의 피드백과 활용수준 등을 고려하지 않고 다만 공개목록을 늘리는데 집착하기 때문일 수도 있고, 실제 데이터제공 업무를 담당하는 공무원의 전문성 부족과 시민 등 이용자 측과의 커뮤니케이션 부족 때문일 수도 있다. 앞서 본바와 같이 지금의 공공데이터 개방은 단순한 알권리의 충족을 위한 정보공개나 투명성의 성취에 그치는 것이 아니라 ICT 기술에 의한 기술적인 활용과 매쉬업의 성취에 있다. 제공된 데이터는 사람보다는 컴퓨터와 소프트웨어, 즉 기계에 의하여 처리되는 경우가 많고 따라서 데이터가 기계의 처리가 가능한 포맷으로 제공되는지 여부가 중요한 의미를 갖는다. 데이터의 포맷은 단지 기술적인 이슈에 그치는 것이 아니라 데이터에 대한 접근성과 활용성을 결정짓는 핵심적인 요소이다.
데이터의 유형이 워낙 다양하므로 그에 맞는 데이터 포맷 역시 다양하다. 또한 이용목적이나 환경에 따라 이용자가 필요한 데이터 포맷도 달라질 수 있으며 선호하는 포맷 역시 차이가 있기 때문에 이를 백퍼센트 만족시키기는 어렵다. 하지만 최대한 활용성이 넓고 프로세싱에 추가적인 과정과 비용이 소모되지 않는 형식으로 제공할 필요가 있는데, 유형별로 추천되는 포맷을 간단하게 설명하면 다음과 같다.
우선 표형식의 데이타는 마이크로소프트의 스프레드쉐트인 Excel의 XLS/XLSX 형식도 가능하나 처리에 추가적인 과정이 필요할 수 있으므로 그 보다는 더 간결한 CSV(Comma-Separated Values) 형식으로 공개하는 것이 더 적절하다. 다만 CSV 형식은 각 컬럼의 의미를 정확하게 설명해주는 적절한 문서작업이 병행되지 않으면 어려움을 겪을 수 있으므로 주의가 필요하다. 문서의 경우에는 XHTML/XML 등이 추천되고 워드 프로세스 파일은 피하는 것이 좋다. 만일 프린트를 위한 레이아웃이 중요한 의미를 갖는다면 PDF/A-1b같은 형식으로 제공하는 것도 좋다. 표형식의 데이타와 같은 간단한 구성이 아니라 계층적이고 구조적인 관계를 포함하는 데이터는 대표적인 기계가독형 오픈 포맷인 XML(Extensible Markup Language)를 사용하는 것이 바람직하다. 최근에는 XML보다 더 간략하게 구성할 수 있고 프로세싱하기 쉬운 JSON(JavaScript Object Notation) 형식이 인기를 끌고 있다. 놓치지 말아야 할 점은 어떤 데이터 포맷을 쓰느냐 뿐만 아니라 그 포맷이 어떻게 사용되느냐에 따라서 데이터의 활용정도가 결정된다는 점이다. XML문서도 중요한 용어들이 부가적인 태그로 충분하게 기술이 되지 않는다면 프로그램이 활용하기 어려워진다.[59]
이와 함께 같은 기계가독형 포맷이라고 하더라도 그것이 공개된 포맷이냐 아니냐가 중요한 의미를 가진다. 공개 포맷(open format)은 사용에 비용이 안들고 명세(specification)가 공개된 포맷을 말한다. 이에 반해 비공개 포맷(closed format)은 상용포맷이거나 명세가 공개되지 않은 포맷이다. 이러한 비공개포맷으로 데이터가 제공될 경우 이용을 위해서 추가적인 비용이 지출되고 밴더에 의존할 수밖에 없어 활용에 제약이 가해진다. 따라서 사진이나 영상, 음성의 경우에는 접근성의 확대를 위해 상용포맷보다는 이미지의 경우 png나 오디오의 경우 ogg와 같은 개방형 포맷을 쓰는게 바람직하다. 객체와 객체의 연결이 중요한 의미가 있는 데이타의 경우에는 RDF(Resource Description Format) 포맷이 적합하다.
마지막으로 데이터는 가공되지 않은 로우 데이터로 제공되어야 한다. 제공자 측에서 일정한 기준에 맞추어 가공한 데이터를 제공하게 되면 오히려 활용도가 떨어지기 때문이다.
(2) 오픈 API 와 다운로드
데이터를 제공하는 방식은 API(Application Programming Interface, 응용프로그램 프로그래밍 인터페이스)와 데이터베이스의 다운로드 방식으로 나눌 수 있다. API는 일반적으로 응용프로그램에서 운영체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 의미하는데, 공공데이터와 관련해서는 공공데이터를 이용한 어플리케이션이 공공데이터 제공 서버에 요청을 보내고 응답을 받기 위해 정의된 명세라고 이해할 수 있다. SOAP나 REST 방식에 의해 구현되는데 REST가 HTML과 같은 메카니즘을 사용하기 때문에 기존의 개발자들이 쉽게 이해할 수 있어 더 선호되는 것으로 보인다. REST에 의해 전달되는 데이터는 앞서 본바와 같이 XML과 JASON이 사용되는데 현재는 JASON이 더 선호되는 편이다.[60] 어플리케이션 개발자 입장에서 API는 큰 비용을 들이지 않고도 대규모의 데이터를 활용할 수 있는 수단이다. 최근 들어와 API는 비즈니스에 있어 점점 필수적인 요소로 자리잡고 있으며 활용의 범위도 커지고 있다. 공공데이터에 있어서는 특히 데이타의 양이 많거나 실시간 데이터처럼 자주 변동이 있는 데이터의 경우 API로 제공하는 것이 더 효율적일 수 있다.
API는 그 효용성에도 불구하고 몇 가지 문제점이 지적[61]되는데 우선 데이터는 그 데이터를 활용하고자 하는 이용자에 의하여 가장 효율적으로 이용될 수 있는데, API는 제공자의 의도에 따라 설계될 수밖에 없으므로 설사 아무리 이용자의 입장에서 데이터 활용을 예상하고 설계를 한다고 하더라도 그가 예상하지 못한 데이터의 활용이 요구될 수 있어 유연성이나 활용성에 제한이 가하여진다는 점이다. 또한 단순히 데이터베이스 다운로드를 제공하는 경우와 달리 인프라 구축을 위한 비용과 시간이 소요되어 신속한 대응이 어렵다는 점도 문제이다. 데이터베이스 다운로드 방식은 파일을 다운로드 받을 수 있게 업로드 하면 모든 것이 완료되는데 반해 API구축은 디자인과 제작, 유지 등 공급자측의 부담이 커지는 단점이 있다. 게다가 내부시스템이 각 이용자들로부터 직접 데이터 요청을 받기 때문에 예상하지 못한 다량의 요청이 있을 경우 시스템에 부하가 걸릴 위험이 있다. 그렇게 때문에 API 제공자는 이용자의 키값을 요구하고 이를 기초로 요청의 회수나 양을 제한하는 등 일정한 제어를 하게 되는데 이용자 입장에서는 이를 활용성의 제한으로 받아들이게 되고 진정한 ‘Open’ API 여부에 대한 논란을 일으킬 수 있다. 따라서 API 설계를 함에 있어서는 풍부한 수요조사와 함께 이용자로부터 수시로 피드백을 받아 개선을 해나가는 작업이 필요하다. 또한 URL의 변경같은 시스템의 변경은 이에 맞추어 작성된 모든 어플리케이션의 수정을 요구하게 되므로 애초에 API를 설계할 때 유의해서 추후 변경의 여지를 최소화해야 한다.
가장 바람직한 것은 번거롭더라도 API와 데이터베이스 다운로드를 병행하는 방식이다. 즉 기본적으로는 오픈 데이터 포맷으로 데이터베이스를 제공하고 이용자가 이를 다운로드받아 자신의 시스템에 API를 구축하거나 자신들의 필요에 따라 활용할 수 있도록 하되 빠르게 변화하는 데이터나 엄청난 양의 데이터, 또는 데이터를 다루는데 있어 좀 더 고급의 기술이 필요해서 데이터를 그대로 공개했을 경우 활용이 폭이 적어질 수 있는 데이터의 경우에는 API를 함께 제공하는 것이다.[62] 경우에 따라서는 데이터 조작의 위험성이 크거나 데이터의 정확성이 민감하게 요구되는 경우에는 다운로드 대신 API 만을 제공하여 데이터 관리를 꾀하여야 할 필요도 있을 수 있지만 이것이 원칙이 될 수는 없다. 수시로 업데이트되는 데이터의 경우 다운로드를 자주 받아야 하는 불편이 있을 수 있지만 자주 업데이트되는 파일명과 URL이 일관되게 지속되면 이를 업데이트하는 것이 큰 부담이 되지 않을 수도 있고, 데이타미러링의 API를 제공하는 방식으로 데이터의 업데이트를 지원할 수 있으므로 되도록 다운로드 방식을 병행하는 것이 적합하다.
(3) 링크드 데이터(Linked Data)
링크드 데이터는 웹 상에 존재하는 데이터를 개별 URI로 식별하고, 각 URI에 링크 정보를 부여함으로써 상호 연결된 웹을 지향하는 모형이다. 즉 RDF[63]와 URI[64]를 기반으로 데이터 웹을 구조화 시키고자 하는 것이다. 월드 와이드 웹의 창시자인 팀 버너스 리(Tim Berners-Lee)는 온톨로지에 기반한 시맨틱웹을 주창한다. 웹상의 정보가 점점 방대해지면서 매번 인간이 이를 인식하고 처리하는데 한계가 있으므로 웹상의 정보를 컴퓨터가 이해하고 처리할 수 있는 의미를 갖는 데이터로 표현해야 되는데 이것이 시맨틱 웹이다. 즉 전통적인 웹을 문서의 웹(Web of Documents)이라 한다면 시맨틱 웹은 데이터의 웹(Web of Data), 더 자세히 말하면 연결된 데이터의 웹(Web of linked data)을 말한다.[65] 링크드 데이터는 이러한 시맨택 웹의 핵심적 요소인 것이다.[66]
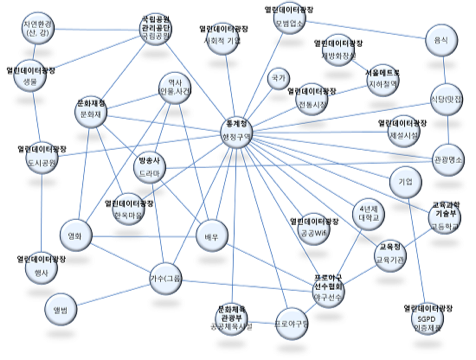
링크드 데이터의 활용은 앞서 언급한 오픈 API 방식에 의한 공공데이터 제공의 단점을 보완할 수 있다. 즉 API는 제공자가 정의한 형식으로만 데이터에 접근이 가능하므로 이용자가 원하는 조건을 구성해 질의하는것이 불가능하고, 데이터에 접근하는 과정에서 각기 다른 API 세트를 결합시킬 수 없는 단점이 있는데,[67] 데이터를 RDF에 기반한 링크드 데이터로 저장시켜 놓으면 이용자가 이 구조를 파악하여 SPARQ 질의를 통해 원하는 방식으로 접근할 수 있고 서로 다른 서버에서 서비스 된다고 하더라도 이를 연결해서 한번에 질의가 가능하게 된다. 또한 링크드 데이타는 데이터의 각각의 특성을 객체로 표현할 수 있으므로 해당 객체로 직접 접근이 가능하다는 장점이 있어, 오픈 데이터를 효과적으로 사용할 수 있도록 해준다. 링크드 데이터는 문화재정보, 기업정보 등 시간에 따른 변동이 그리 크지 않고 객체로서의 특징이 있는 데이터의 경우에 유용하고, 특히 어떤 정보에 참조가 되는 정보일 경우에는 효용성이 크다. 아래 그림과 같이
공공데이터에 한정하지 않고 민간데이터와도 연계를 시킬 수 있어 활용의 폭이 커진다. 아직 링크드 데이터가 널리 확산되지 않고 있으나 제대로 구축될 경우 공공데이터의 효과적인 활용에 큰 도움이 되므로 앞으로 이에 대해서는 지속적인 연구와 시도가 추구될 필요가 있다.[68] 링크드 데이터의 활용이 제일 적극적으로 추진되고 있는 곳은 팀 버너스리가 참여하고 있는 영국의 공공데이터 프로젝트[69]이나, 국내에서도 링크드 데이터의 구축이 점차 확산되고 있다.[70]
다. 인간가독형 인터페이스
공공데이터는 좀더 많은 시민이 자신의 용도에 맞게 활용할 수 있을 때 더 큰 가치를 갖는다. 따라서 데이터의 수요자를 개발자 등 전문적인 기술을 가진 시민에 한정하여 기계가독형 데이터의 공개에만 집중하는 것은 데이터 활용의 기회를 놓치는 결과가 될 수 있다. 혁신은 훌륭한 어플리케이션의 개발을 통해서만 만들어지는 것은 아니며 평범한 일반 시민들의 소박한 기여를 통해서도 성취될 수 있는 것이다. 특히 최근 소셜 큐레이팅(Social Curating)이 사람들의 관심을 끌고 있는데 간단히 말해서 인터넷이나 SNS에 넘쳐나는 정보들 중 유용한 정보를 선별하고 나름의 기준으로 제공함으로서 특정한 맥락을 제공하는 서비스 내지 행위를 의미한다. 빅데이터에 관한 논의에서도 볼 수 있듯이 다양한 비정형 데이터의 폭발적인 증가와 정보과잉의 시대에서는 기존의 검색서비스는 이용자의 의도를 만족시킬 수 없는 지경에 이르렀고, 그에 따라 데이터 마이니팅 등 다양한 마이닝 기법이 주목을 받고 있다. 소셜 큐레이팅은 이러한 마이닝과 맥락을 같이 하지만 좀더 대중적인 솔류션을 제공하는데 SNS시대에 걸맞게 누구나 정보를 선별하고 제공하는 큐레이터가 될 수 있도록 하는 서비스가 소셜 큐레이션 서비스이다. 즉 기존의 소셜네트워크 서비스가 타임라인 위주의 실시간 정보제공에 촛점이 맞추어 졌다면 소셜 큐레이션 서비스는 정보탐색과 열람방법에서의 편의성을 극대화하였다는 점에서 기존의 소셜네트워크서비스와 차이를 지닌다.[71] 공공데이터에서도 이와 같은 소셜 큐레이션이 활용될 수 있음은 물론이다. 넘쳐나는 공공데이터 중 특정 목적에 맞는 유용한 정보를 골라내어 맥락있는 정보를 제공해줌으로써 이전에는 간과했던 문제점을 발견할 수 있고 새로운 해결책을 모색할 수 있는 것이다. 따라서 기계가독형 데이터의 제공뿐만 아니라 효율적인 인간가독형(human-readable)의 인터페이스를 함께 제공하는 것도 중요한 의미를 갖는다. 인포그래픽스나 대쉬보드 형태의 뿐만 아니라 데이터의 내용과 함의를 상호작용이 가능한 인터페이스를 통해 시각화시켜주는 비쥬얼라이제인션(Visualization) 등을 시도해볼 수 있을 것이다.
3. 표준(Standard)
공공데이터의 제공 방식으로서 점점 큰 비중을 차지하고 있는 오픈 API의 경우 XML이나 JSON 형식으로 결과값을 반환하는데 태그(속성)에 값(Value)이라는 형식을 사용한다. 오픈 API를 이용해 서비스를 개발하는 경우 값을 활용하기 위해서 속성의 의미를 정확하게 컴퓨터가 이해하여야 하는데 만약 그 의미를 제대로 파악하기 힘들면 제대로 활용할 수가 없다. 또한 복수의 오픈 API를 결합하는 경우에 같은 의미의 속성이 전혀 다른 단어를 사용하게 되는 경우 이를 조합하기 힘들거나 조합을 위해서 번거로운 과정을 거쳐야 하는 문제가 있다. 공공데이터를 분석하다보면 심지어 같은 기관에서 나온 데이터의 경우에도 같은 속성을 다른 단어로 사용하는 것을 종종 발견할 수 있다. 따라서 자주 사용하는 속성에 대해서는 통일된 용어를 사용하는 것이 바람직한테 이러한 이슈들이 표준의 문제이다. 주의해야 할 것은 공공부문에서 독자적으로 표준을 설정해 나가는 것은 바람직하지 않다는 점이다. 전세계의 표준이 되지 않는 한 독자적인 표준은 결국 호환성과 유연성을 떨어뜨려 공공데이터의 활용과 매쉬업을 어렵게 할 것이므로 삼가해야 한다. 그 보다는 기존에 구축되어 있거나 많이 사용되는 더블린 코어(Dublin Core), FOAF 등의 민간의 표준을 사용하는 것이 훨씬 효과적이다.
또한 API의 파라미터 형식도 제각각이어서 정리가 필요하다. API의 URL은 서비스 기능의 계층과 특성을 명시적으로 표현하여 구성하는 것이 바람직하고 직관적으로 이해하기 쉬워야 한다. 예를 들어 서울시의 화장실 정보에 대한 URL을 http://OpenAPI.seoul.go.kr:8088/sample/xml/SearchPublicToiletPOIService 로 표현하는 것보다는 계층의 구조를 알 수 있는 http://OpenAPI.seoul.go.kr:8088/pubInfo/public-toilets 과 같은 방식으로 표현하는 것이 훨씬 가독성이 있고 나중에 계층적인 속성을 추가하는 경우에도 적합하다. 공공데이터의 활용을 가로막는 장해는 의의로 사소한데에 있는 경우가 많다. 대부분의 것이 제공되더라도 어느 사소한 부분이 표준에서 어긋나거나 부정확한 값을 갖고 있는 경우 이를 해결하는데 추가적인 프로세스와 비용이 소요되는 바람이 활용을 포기하는 경우가 종종 발견된다. 따라서 데이터의 제공은 활용의 모든 편의성을 고려한 꼼곰한 배려가 필요하다. 앞으로 데이터의 표준 이슈는 계속 제공될 것이니 만큼 이에 대한 꾸준한 대비와 고민이 요구된다.
4. 준비된 시민
가. 시민의 역할
공공데이터의 개방이 특별한 의미를 갖는 것은 시민과 정부가 만나는 방식의 근본적인 변화를 꾀하기 때문이다. 시민의 공무원에 대한 무시와 공무원의 시민에 대한 불신을 깨트리고 상호 신뢰하에 참여와 협업을 통해 이상적인 참여민주주의를 실현하고자 하는 것이다. 정부는 ICT 기술의 발전이 가져온 생활방식, 문화, 비즈니스에서의 혁신과 효율성을 공공영역으로 끌어 옴으로써 정부의 기능과 역할을 한 단계 더 높이고자 하는 바, 이를 위해서는 민간과 공공의 접점에서 열정과 창의성을 발휘할 혁신가들인 능동적인 시민의 기여가 절대적으로 필요하다. 그 혁신가들은 결코 거창한 포부나 수준높은 기술을 갖추어야만 하는 것은 아니다. 다양한 경험과 지식을 매개로 다양한 방식에 의한 기여가 가능하다.
이러한 혁신가들을 끌어들이기 위해 국내외에서 여러가지 시도들이 있어왔다. 그 중에서도 2013년 6월 1일과 2일 양일간에 계획되어 있는 미국의 ‘National Day of Civic Hacking’[72] 이벤트는 시민들의 참여를 끌어내고 커뮤니티를 조성하기 위한 노력이 돗보이는 행사라 할 수 있다. 정부, 사기업, 민간단체, 시민이 커뮤니티의 개선이라는 공통 목표를 갖고 전국에서 행사를 개최하는데, 각 도시의 사정에 맞게 블ㄹ록 파티(block party), 해커톤(hackathon),[73] 브리게이드 미팅(brigade meetup) 등 다양한 포맷의 행사가 계획되어 있다. 즉 또한 개발자 뿐만 아니라 특별한 기술이 없는 모든 시민들을 초대하고자 단순한 파티부터 전문적인 해커톤까지 다양한 포맷으로 진행된다. 각 주당 최소 1개의 도시에서 행사가 이루어지는 것을 목표로 참여신청을 받고 있는데 현재 뉴욕, 샌프란시스코 등 54개의 도시가 참여신청을 마친바 있다. 이 행사에서 눈여겨 봐야 할 것은 해킹이라는 단어이다. 해커에 대한 일부의 부정적인 의미에도 불구하고 이 단어를 사용하는 것은 최소한의 리소스로 최대의 지력과 천재성으로 기존의 시스템을 분석하고 문제점을 찾아내어 영향을 미치는 해커들의 역동성을 강조함으로써 창의적인 시민들의 참여를 끌어내려는 의도로 보인다.
시민들의 참여를 끌어내려는 정부측의 노력은 사실 많은 시행착오를 거쳤다. 문화와 관습이 다를 수 밖에 없는 두 영역이 자연스럽게 어울려 효율적인 협업이 일어나기 위해서는 상대방에 대한 충분한 이해와 함께 상대방을 존중하는 겸손함, 상대방의 문화를 기꺼이 수용하려는 열린 자세가 필요한데 이게 그렇게 쉽지않기 때문이다. 정부는 그 동안 오랜세월을 거쳐 축적된 업무처리방식과 나름대로의 프로토콜이 있어 그 틀에서 벗어나기가 사실 쉽지 않다. 정부의 전통적인 행정과 거버넌스는 협업보다는 규제와 서비스라는 차원에서 다루어졌기 때문에 민간의 문화와 관습을 정부 안으로 끌어들일 기회가 드물었다. 그렇기 때문에 시민의 참여와 협업을 기대하면서도 그 추진 방식은 종래의 전통적인 커뮤니케이션 관습에 머물렀고 그렇기 때문에 시민의 호응을 얻는데 실패를 하는 경우가 많았다. 이건 국내나 해외 모두 마찬가지 현상일 것이다. 하지만 경험이 쌓이고 시민의 참여와 협업에 대한 이해와 노하우가 쌓이면서 정부도 점차 세련되고 효율적인 방식으로 시민들을 초대할 것으로 기대되는 바, National Day of Civic Hacking 와 같은 행사는 이점에 있어서 좋은 사례라 할 수 있다.
이러한 상황에서 우리는 ‘시민’의 역할과 그 역량에 대해서 생각해볼 필요가 있다. 그동안 공공데이터의 개방과 열린 정부를 논하면서 항상 강조해왔던 것은 정부의 변신이었다. 공공데이터의 개방에 대한 결단을 요구하고 시민이 참여할 수 있는 플랫폼의 구축을 주장하면서 정부를 재촉하여왔다. 때로는 정부의 미온적인 대응에 실망하고 그 한계를 지적하며 비난을 하기도 했다. 마치 정부만 모든 준비를 마치면 준비된 시민들이 달려가 참여와 협업에 의한 혁신을 금방이라도 이룰 것 같은 분위기다. 그러나 과연 시민은 ‘준비’되었는가.
열린 정부와 공공데이터의 개방은 기회를 주면 시민이 결정적인 역할을 하게 될 것이라는 기대를 전제로 한다. 여기에서의 시민은 단지 정부가 제공하는 편리한 서비스를 즐기거나 불평을 하는 역할에 그치지 않고 행정과 정부를 함께 만들어나가고 자신들의 문제를 스스로 해결하려는 능동적인 주체들이다. 물론 자신의 직업과도 관련될 수 있지만 대부분 그것과는 별개로 공동체에 대한 기여와 열정을 가진 자발적 참여자들로서 자신의 시간과 노력을 제공하는 활동가들이 바로 열린 정부가 바라는 시민이다. 이는 단지 열정과 의욕만으로 되는 것이 아니라 그러한 경험과 함께 나름대로의 노하우와 능력도 갖추어야 한다. 물론 정부와 마찬가지로 시민도 시간과 경험이 쌓이면서 점차 성숙되어가리라 예상되지만 열정과 능력을 갖춘 시민이 얼마나 많으냐에 따라 공공데이터의 개방에 따른 혁신은 늦어질 수도 있고 속도를 낼 수도 있다. 우려가 되는 것은 몇번의 시도가 별다른 효과를 얻지 못하였을 대 자칫하면 그 이후의 진행에 영향을 미칠 수 있는 점이다. 시민들의 요구에 따라 막상 공공데이터를 개방하고 플랫폼을 만들었는데 시민들의 참여가 더디고 별다른 성과나 반응이 없을 경우 안 그래도 그 효용성에 대한 부정적인 인식을 가지고 있는 측에서는 정책의 후퇴를 주장할지도 모른다. 분명 시민은 참여와 협업에 목말라 있다. 하지만 참여야 협업은 단지 열어주면 자동적으로 발생하는 것이 아니다. 준비된 시민들의 협조가 필수적일 수밖에 없다. ‘준비된 시민’은 개개인 차원에서도 요구되지만 추진동력과 지속성을 갖는 단체나 커뮤니티 차원에서의 준비가 더 큰 의미를 갖는다. 특히 우리의 경우 미국 등에 비해 공공데이터의 개방과 혁신에 동력을 불어넣어줄 실체들인 커뮤니티나 전문 조직이 부족한 것이 사실이다. 문화적 차이나 환경의 차이도 있겠지만 열린 정부의 혁신은 커뮤니티나 동력을 제공할 단체의 뒷받침이 없으면 제대로 효과를 얻기가 쉽지 않다. 따라서 이러한 커뮤니티나 주체를 어떻게 조성하고 지속성 있는 역할을 어떻게 할 것인가가 풀어야 할 중요한 숙제 중 하나라 할 수 있다.
나. 주요 사례로부터 얻는 교훈
(1) 코드 포 아메리카(Code for America)[74]
코드 포 아메리카는 2009년에 설립된 미국의 비영리단체로 시정에의 민간 참여를 새로운 방식으로 디자인하고 있다. 코드 포 아메리카는 몇 가지 프로그램을 통해 미국 각 지역의 시정부가 민간의 재능있는 인터넷, IT 전문가들의 도움을 통해 저비용으로 웹과 효율성 있는 IT 기술의 혜택을 받도록 한다. 시정부들의 전반적인 열악한 재정상태와 그로 인한 IT 인프라의 부족을 시민의 참여를 통해 해결하여 시정부의 기능을 개선시키고 효율성을 높이고자 하는 수요와 이에 힘을 보태려는 민간의 기여가 결합하여 새로운 파트너쉽이 등장한 셈이다. 코드 포 아메리카는 시와 시민의 연결을 다양한 방식으로 시도하고 있는데, 그 중 펠로우쉽(Fellowship) 프로그램[75]이 가장 핵심이라 할 수 있다.
펠로우쉽은 젊은 웹개발자, 디자이너, 프로그램 메니저 등을 펠로우로 선발하여 11개월 기간동안 그룹별로 특정한 시정부와 함께 해당 시의 문제점을 분석하고 그에 대한 솔류선 어플리케이션을 개발하며 이를 오픈소스로 공개하여 다른 시들도 활용할 수 있도록 한다. 2011년에 처음 시작되어 펠로우와 시정부의 신청을 받아 선발된 20명의 펠로우들이 보스톤 등 4개 도시와 함께 작업을 하였고, 2012년에는 26명의 펠로우들이 선발되어 오스틴 등 8개의 시와 작업을 하였다. 2013년에는 9개시와 작업을 하기로 되어 있고 현재 2014년에 참여할 시정부의 지원을 받고 있다. 시정부는 3명의 펠로우에게 지급할 보수를 부담하고, 펠로우들은 많지는 않지만 소정의 보수를 받아가며 다양한 전문가들로부터 도움을 받아가며 작업을 하게 된다. 시정부 입장에서는 비교적 저렴한 예산을 들여 전문가들의 도움을 얻을 수 있는 기회를 얻고, 펠로우들은 적당한 보수를 받아가며 열린 정부에 기여하는 경험과 실력향상의 기회를 얻을 수 있는 윈윈(win-win) 전략이다. 특히 중요한 점은 펠로우들은 평소 자유롭게 외부에서 시정부와 긴밀하게 연락하며 작업을 하다가 일부 기간 동안은 시정부의 사무실에서 머무르며 작업을 하게 되는데 젊은 개발자들 특유의 자유롭고 혁신적인 문화가 정부조직에 스며들 기회가 될 수 있다는 점이다. 이는 기존의 공공부문의 IT 개발이 주로 이른바 갑을 관계에 의한 외주방식으로 획일적으로 진행되어 오고 공공부문과 개발회사가 대등한 위치에서 협업을 통해 솔류션을 찾아가는 이상적인 프로세스를 경험하지 못하는 우리의 환경에서 특히 주목할 부분이다. 실제 그러한 방식이 어떠한 효과를 가져오는지, 또는 이미 반복된 외주를 통해 공공부문을 둘러싼 개발 생태계가 공고하게 자리잡고 있는 국내 사정상 이러한 방식의 도입이 실현될 수 있는지는 아직 미지수이지만, 분명 이와 같은 새로운 방식의 공공부문 솔류션 개발은 열정과 재능을 가진 젊은 전문가들이 재정적 지원을 받아가며 열린 정부에 실질적인 기여를 할 수 있다는 점에서, 공공부문은 시민과의 협업을 경험하면서 동시에 내부 문제에 대한 디테일한 솔류션을 얻을 수 있다는 점에서 분명 시도해 볼 만하다. 실제 종래의 관료주의하에서의 다층구조를 통한 프로세스와 소수의 전담인력에 대한 과부화는 다른 영역에 비추어 공공분야의 효율성에 의문을 품게한 중요한 이유였다. 민간에서는 이미 과거에는 몇몇 전문가나 규모가 큰 조직만이 할 수 있었던 일들을 싸고 널리 공급되는 툴들을 이용해서 손쉽게 만들어내고 있다. IT 인프라도 마찬가지이다. SI나 혁신성이 떨어지는 기존 업체에 의한 획일적인 인프라의 구축 외에도 빠르고 디테일한 경량의 프로세스를 통해서 비용을 훨씬 절감하면서 효율적인 솔류선의 개발방법이 필요한 영역은 분명 존재한다. 코드 포 아메리카의 펠로우쉽 제도는 이러한 측면에서 많은 점을 시사하고 있는 것이다.
그 밖에도 코드 포 아메리카는 지방정부와 지역커뮤니티 서비스를 위한 플랫폼으로서의 웹을 이용해서 자신의 능력을 기여하고자 하는 자원활동가들의 커뮤니티인 브리게이드(Brigade)[76], 지방정부에 혁신을 가져오기 원하는 공무원들의 학습 네트워크인 피어 네트워크(Peer Network)[77] 등을 운영하면서 시민과 정부의 관계를 새롭게 만들어가고 있다. 코드 포 아메리카는 지속성 있게 시민의 실질적 기여를 끌어내는 효율적인 모델로서 의미가 크다 할 것이다.
(2) 선라이트 재단 (Sunlight Foundation)[78]
선라이트 재단은 2006년에 설립된 미국의 비영리재단으로 연방정부의 투명성과 책임성을 증진시키기 위한 것을 목적으로 한다. 주로 연방정부와 의회의 투명성을 감시하여 열린 정부를 만들기 위한 정책의 전환을 끌어내는 한편 시민들로 하여금 정보를 모으고 디지털화하는 작업에 참여하도록 독려한다. 코드 포 아메리카가 공공데이터의 개방과 시민의 참여에 의한 시정의 개선과 효율성의 증진을 추구한다면 선라이트 재단은 공공데이터의 활용과 시민의 참여를 바탕으로 정부의 투명성에 집중한다. 2006년에 투명성 프로젝트를 위해 오픈소스 개발자와 디자이너의 힘을 모으기 위한 선라이트 연구소(Sunlight Labs)[79]를 런칭하여 열린정부를 개선하기 위한 아이디어를 논의하는 커뮤니티를 만드는 한편, Apps for America[80]를 개최하여 매쉽업 컨테스트를 진행하였다. 2007년에는 의회가 좀더 유연한 웹사이트를 구축하고 위원회 정보의 공개와 투표결과의 XML 버전 등을 도입하기 위한 Open House Project[81]와 입법안과 의회활동을 추적하는 OpenCongress.org를 런칭했다. 2010년 복잡한 정부정보를 좀더 이해하기 쉽게 만들어주는 시각화 프로젝트인 Design for America, 정부기관들의 지출내역보고서를 분석하는 ClearSpending 프로젝트, 2011년 의회기록을 분석하여 가장 자주 언급된 용어와 문장을 리서치한 Capitol Words, 2012년 효율저인 리서치를 위해서 투명성툴의 사용을 돕는 포탈인 Sunlight Academy 등을 런칭하였다. 그밖에 다양한 Congress, Sitegeist, Ad Hawk, Realtime Congress, Sunlight Health 등 관련 서비스를 제공하는 모마일 어플리케이션을 보급하였다. 이처럼 선라이트 재단은 전문가들이 모여 공공데이터의 기술적 활용과 모바일 어플리케이션 등 효율적인 툴을 이용해서 열린 정부의 투명성을 지속적으로 추구한다는 점에서 전통적인 국정감시 시민단체나 개별적인 시민들에 의한 투명성 감시와 차별된다.
선라이트 재단이 공공데이타의 개방에 미친 영향은 지대하다. 2006년 이래 공공데이터를 발굴하고 공개를 요구하여 왔으며, 오픈데이터에 대한 가이드라인[82]을 마련하는 등 선도적인 역할을 하였을 뿐만 아니라, 공개된 데이터를 이용한 혁신적인 프로젝트와 어플리케이션을 지속적으로 개발 보급함으로써 공공데이터의 개방이 정부의 투명성 증진과 혁신에 어떻게 기여하는지 인상깊게 보여주었다. 국내에서도 선라이트 재단과 같이 열린 정부와 공공데이터의 개방과 관련된 시민의 참여를 지속적으로 지원할 수 있는 재정적 능력을 갖춘 조직이 필요하다는 의견들이 많이 들린다. 그런 지원을 통해 능동적이고 준비된 시민이 계속 길러지고 참여와 협업을 통해 성장해 갈 수 있기 때문이다.
(3) 코드나무(Codenamu)[83]
코드나무는 공공데이터의 개방과 열린 정부에 관심을 갖는 자원활동가들이 모인 국내 커뮤니티이다. CC Korea의 자원활동가들은 오래전부터 공공정보의 개방과 활용에 관심을 갖고 관련 세미나를 개최하고 관련자료들을 만들어 왔다. 2009년 초 서울버스 앱 사건으로 촉발된 공공데이터의 활용 문제를 주제로 국회에서 세미나를 개최하여 정부 2.0에 대한 본격적인 논의를 시작하였고, 2010년 정부 2.0 블로그인 http://gov20.kr을 구축하였다. 그후 정부 2.0 자료 집필 프로젝트를 진행하였고, 2011년 가장 우수한 정부 2.0 보고서로 평가되었던 호주의 정부 2.0 태스크포스 보고서를 번역하여 출간하여 이를 100인의 공무원에게 보내는 캠페인을 개최하는 한편, IT 전문 온라인 매체인 블로터 닷넷(http://bloter.net) 과 함께 정부 2.0 시리즈를 연재하였다. 2012년에는 팀오라일리 등이 공동으로 저술한 ‘Open Government’를 번역한 ‘열린 정부 만들기’를 출간하는 한편, 정부 2.0 프로젝트 로드맵을 위한 스터디 모임을 진행하였다. 알권리에 기초한 정보공개와 관련해서는 시민단체인 투명사회를 위한 정보공개센터[84]가 활발한 활동을 하면서 큰 역할을 하여 왔으나 본격적인 정부 2.0과 공공데이터의 이슈에 대해서는 이를 추진할 만한 조직이나 커뮤니티를 찾아보기 어려웠다. 그나마 CC Korea가 2009년 이래 정부 2.0과 공공데이터의 개방을 다루어 온 거의 유일한 국내 커뮤니티라 할 수 있다.
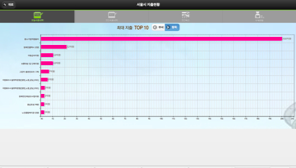
2012 초 CC Korea는 지속적이고 전문적인 정부 2.0 프로젝트를 추진하기 위해 별도의 커뮤니티을 출범시켰는데 그것이 코드나무이다. 코드나무에는 CC Korea의 자원활동가들 외에 정부 2.0과 공공데이터에 관심있는 개발자, 디자이너 등이 참여하고 있다. 2012. 6. 1. 서울디지털포럼에서 팀오라일리, 돈 탭스콧, 니콜라스 그루엔 등 해외 유명인사와 서울시, 문화부, 행안부의 담당자들이 참석한 가운데 대한민국의 정부 2.0을 논하는 자리를 마련하여 우리의 현재, 다른 나라의 사례, 열린정부와 정부 2.0을 통해 우리가 나아갈 미래등을 진지하게 논의[85]한 이후 공공데이터를 본격적으로 다루기 위해 준비모임을 거쳐 2012. 7. 20. 해커톤 형식의 첫번째 공공데이터 캠프[86]를 개최하였다.[87] 캠프가 종료되면서 나온 결과는 기대이상이었다. 약 20시간의 짧은 시간 동안 8개 팀에서 8개의 어플리케이션이 나왔는데 그중 ‘지켜보고 있다’와 ‘안심병원’이 참가자들의 투표로 1, 2위에 뽑혔다. ‘지켜보고 있다’는 서울시의 예산 데이터를 시각화한 어플리케이션으로 서울시 예산의 일일지출액과 용도까지 자세히 보여줘 시예산 및 지출현황을 이해하기 쉽게 전달하여 호평을 받았다.[88] 안심병원은 건강보험 심사평가원의 병원 정보에서 항생제 처방 빈도, 주사제 처방 빈도 등을 크롤링하여 오픈 지도 플랫폼인 우샤히디 플랫폼 지도에 뿌려서 보여주는 서비스이다.[89]
공공데이터 캠프가 시사하는 것은 열정적이고 창의적인 시민들의 존재와 그들의 역량에 대한 기대이다. 게다가 행사 당일 서울시와 한국정보화진흥원에서 나온 전문가들이 함께 밤을 새며 필요한 데이터의 소재를 알려주는등 진행중에 발생하는 문제들을 해결해주면서 협업을 하였던 경험은 앞으로 공공데이터의 개방과 활용을 추진함에 있어 무엇이 제일 중요한 부분인지 이해하게 해준다. 정부와 시민이 파트너로서 서로의 역량을 제공하며 협업할 때 공공데이터의 개방이 갖는 본래의 의미가 실현될 수 있다는 교훈이다. 이를 계속 확인하면서 신뢰를 만들어 가는 작업이 코드나무와 같은 커뮤니티가 해줘야 할 역할이다. 자발적인 커뮤니티는 이러한 역할을 지속적으로 하면서 공공데이터의 개방과 혁신에 동력이 되어주고, 시민들에게 지속적으로 경험과 정보를 얻을 기회를 제공해 주어야 한다. 코드나무는 캠프 이후에는 소규모의 코드잼을 정기적으로 진행해 오고 있고, 서울시의 API 검증 등 공공데이터의 활용에 기여할 수 있는 크고 작은 프로젝트를 진행해 오고 있다.
다. 데이터 허브의 구축
시민들이 공공데이터의 확산과 활용에 기여할 수 있는 방법은 다양하다. 앞서 언급한 협력민주주의의 전형처럼 각자의 전문성과 사정에 적합한 방식으로 참여를 하면 된다. 문제는 이러한 시민의 참여를 효율적으로 끌어내 줄 플랫폼의 디자인이다. 앞서 본바와 같이 시민들의 참여를 지속적으로 자극하고 지원해 줄 조직이나 커뮤니티의 존재도 중요하지만 그들이 만들어 내는, 혹인 개별적인 시민들 스스로가 만들어 내는 실용적인 플랫폼의 구축도 중요한 의미를 갖는다. 가장 먼저 생각해 볼 것은 시민들 스스로 유용한 공공데이터를 찾아내고 관련된 공공 또는 민간데이터의 목록을 정리하며, 더 나아가 오류제거, 누락된 정보의 추가 등 데이터의 품질을 향상시키는 크라우드 소싱에 의한 작업이 이루지게 되는 데이터 허브이다. 이제 중요한 것은 공공데이터 그 자체가 아니라 공공데이터의 품질이다. 품질 좋고 효용성있는 공공데이터가 꾸준하게 확산되어야 혁신이 이어질 수 있다. 공공데이터의 품질은 제공자인 정부측에서 끊임없이 노력해줄 것이지만 시민들이 함께 참여할 때 좀더 큰 효과를 얻을 수 있다. 민간의 데이터 허브는 공공의 데이터 포탈과 연계되어야 하고, 공공데이터의 활용을 통해 얻어지는 시민의 경험이 꾸준하게 피드백 되는 창구로 역할해야 한다.
V. 마무리
지금까지 공공데이터의 개방과 그에 따른 혁신의 추구에 있어 한단계 더 올라가기 위한 필요한 몇가지 중요한 요소들을 중심으로 언급해보았다. 그동안 공공데이터의 가치와 열린 정부가 갖는 이념적, 이론적 의미에 대해서는 숱하게 언급되어 왔고, 상징적인 사례들에 대한 찬사는 이제 진부하게 느껴질 정도이다. 하지만 그렇기 때문에 공공데이터의 개방에 대한 인식은 그 저변을 넓혀 왔고, 길지 않은 시간 동안 공공부문이 이룬 발전 역시 아주 인상적이다. 이 시점에서 주의해야 할 것은 공공데이터의 개방에 대한 회의와 시민의 참여라는 새로운 방식에 대한 거부감도 문제이지만 공공데이터의 개방에 대한 막연한 기대와 환상 역시 아무런 도움이 되지 않는다는 점이다. 공공데이터 목록을 늘린다고 혁신이 자동적으로 생기는 것도 아니고 시민들이 참여한다고 해서 세상이 갑자기 바뀌는 것도 아니다. 혁신에 대한 기대 역시 마찬가지이다. 우리가 그렇게 기대하던 공공데이터의 개방에 따른 혁신은 거창하기보다 소소하고 일상적인 것이 대부분일 수 있고, 막연했던 이론은 현실에서 별다른 성과를 보여주지 못할 수도 있다. 오히려 공공데이터의 개방에 대한 섵부른 환상과 혁신에 대한 서투른 기대는 약보다는 독이 될수도 있음을 기억해야 한다.
그동안 공공데이터의 개방과 열린 정부에 관심을 갖고 커뮤니티와 함께 해온 입장에서 드는 생각은 모든 변화의 출발이자 완성은 문화의 변화에 있다는 사실이다. 공공데이터의 개방이 가져올 최고의 혁신은 투명성의 확보나 협력민주주의 실현, 창의적인 솔류션의 개발이나 막대한 산업적 효과라기보다는, 공공데이터의 개방과 이를 매개로 한 시민과 정부의 경험이 가져올 문화의 변화이다. 이는 정부내 공무원들 간의 문화적 변화일 수도 있고, 시민과의 관계에 있어서의 문화적 변화일수도 있다. 또한 시민들의 협업에 관한 문화적 변화일수도 있고, 시민들이 정부를 대하는 방식의 문화적 변화일 수도 있고, 시민들이 시정에 참여하는 형태의 문화적 변화일 수도 있다. 결국 민관 전반에 걸쳐 공공데이터의 개방에 따른 혁신과 열린 정부를 실현하기 위해 가장 필수적인 요소가 문화적 변화이고, 공공데이터의 개방과 열린 정부가 가져올 가장 큰 혁신 역시 문화적 변화라는 의미이다. 문화적 변화는 공공데이터 개방의 동인이자 최대의 성과이다. 결국 우리들의 모든 노력은 시간이 걸려 조금씩 조금씩 바뀌는 이 문화적 변화에 기여하게 된다. 문화적 변화는 경제성과처럼 눈에 쉽게 띄는 것도 아니고 금새 실감하기도 쉽지 않다. 그렇기 때문에 간과하기 쉽고 소홀하기 쉬운 것이다. 크게 변한거 같지는 않겠지만 돌이켜 보면 공공데이터를 둘러싼 크고 작은 논의들과 경험은 시민과 정부가 서로를 바라보는 관점에 이미 변화를 주었음이 틀림없다. 우리가 경험한 이 변화들은 앞으로의 단계에서 큰 자산으로 역할할 것이다. 준비된 시민과 열려진 정부가 만들어 낼 다음 단계의 혁신들에 대한 기대해 보는 것도 바로 이 작은 문화적 변화들 때문이다.
[1] 황유근, 채승병, ‘빅데이터, 경영을 바꾸다’, 삼성경제연구소, 2012, 36
[2] 미국 IT분야의 시장조사 및 연구컨설팅 업체인 가트너(Gartner)에 의해 처음 소개되었다고 한다.
[3] 1 테라(Tera) 바이트는 1,000기가(Giga) 바이트, 1페타(Peta) 바이트는 1,000 테라바이트를 의미한다.
[4] 황유근, 최승병, 전게서, 29
[5] 관계형 데이터베이스에 저장될 수 있는 구조형 데이타는 15퍼센트에 불과하고, 이메일이나 SNS, 비디오, 사진, 블로그 등의 비정형 데이타가 85퍼센트에 달하는 것으로 알려져 있다. 구조적 데이터가 주로 각종 거래를 처리하는 과정에서 발생하고, 비 구조적 데이터는 주로 사람들 간, 사람과 기계간, 혹은 기계들 간의 상호작용으로 생산되는 점에 착안하여 전자를 빅 거래 데이터, 후자를 빅 상호작용 데이터로 구분하는 견해도 있다. 황유근, 채승병, 전게서, 37
[6] 2000년 부터 미연방정부가 수집하는 데이터의 양은 거의 기하급수적으로 증가하기 시작해서 2009년에는 848 페다바이트의 데이타가 수집되었으며 건강분야 데이터만 해도 150 엑사바이트에 달한다고 한다. Source: IDC, US Bureau of Labor Statistics, McKinsey Global Institute Analysis, Roger Foster, “How to Harness Big Data for Improving Public Health,” Government Health IT, April 3, 2012, at http://www.govhealthit.com/news/how-harness-big-data-improving-public-health
[7] http://www.nytimes.com/2012/03/29/technology/new-us-research-will-aim-at-flood-of-digital-data.html?_r=0
[11] Joshua Tauberer, “Open Data is Civic Capital: Best Practices for Open Government Data”,
http://razor.occams.info/pubdocs/opendataciviccapital.html#bestprac 2013. 3. 20. 최후 방문
[12] Sunlight Foundation, “Guidelines for Open Data Policies” http://sunlightfoundation.com/policy/opendata/ , 2013. 3. 20. 최후 방문
[13] 한편, 최근 빅데이타가 이슈가 되면서 페이스북과 같은 SNS 서비스가 보유하고 있는 개인들 관련 정보들에 대한 공개여부가 논란이 되고 있다. SNS에 올린 이용자들의 글, 사진, 동영상 뿐만 아니라 친구관계, 위치정보, 프로필, 댓글 또는 ‘좋아요’ 등 SNS업가 빅데이터로 활용할 수 있는 정보들이 정보주체와 SNS 서비스 주체 중 과연 누구 것인지에 대한 논쟁이 야기되고 국내 이용자들에 관한 모든 정보를 외국기업이 보유하고 있는데에 대한 우려가 나오면서, 빅데이터에 대한 국가적 또는 공공적 차원의 권리를 주장하거나 오픈 데이터로의 전환을 주장하는 경우가 종종 나오고 있다. 이에 대해서는 아직 논의가 무르익은 상태가 아니어서 섣불리 견해를 밝히기 어려우나, 각 개인들이 자신들 관련 데이터를 활용할 수 있도록 원하는 경우에는 언제든지 관계 데이터가 유지된 기계가독형 포맷으로 넘겨 주어야 한다는 데이터 이동성(data portability) 주장은 설득력이 있는 것으로 보인다.
[14] 콘텐츠, 데이터, 정보가 명확하게 구분되는 것은 아니다. 보통 콘텐츠는 저작권의 대상이 되는 저작물과 유사한 개념으로 사용되는데 반하여 데이터는 단순한 사실들의 기록으로 이해되나 콘텐츠를 포함하는 개념으로 파악되기도 한다. 이에 비하여 정보는 다양한 의미로 사용되는바, 정보화촉진기본법은 ‘광 또는 전자적 방식으로 처리하여 부호, 문자, 음성, 음향, 영상 등으로 표현되는 모든 종류의 자료 또는 지식’으로 정의하여 데이터와 거의 비슷한 개념으로 정의하고 있다.
[15] 1955년 국제과학조합위원회(International Council of Scientific Union)가 과학데이터의 접근성을 극대화하고 데이터손실을 최소화하기 위해 몇군데에 세계 데이터 센터(World Data Center)를 설립하면서 과학 데이터에 대한 오픈 억세스 정책을 수립했다고 한다. http://en.wikipedia.org/wiki/Open_data 2013. 3. 20. 최후방문
[16] http://www.oecd.org/science/sci-tech/oecdprinciplesandguidelinesforaccesstoresearchdatafrompublicfunding.htm 2013. 3. 20. 최후 방문
[19] CC Korea, ‘CCL과 클린사이트가이드라인’, 저작권보호센터, 2009, 102, http://goo.gl/IEBhq 에서 다운받을 수 있다
[20] 정보자유법은 1996년 전자정보시대를 맞아 ‘전자정보자유법(Electronic Freedom of Information Act)로 개정된바 있다.
[21] 설계경, “행정정보공개제도에 관한 고찰”, 외법논집, 2005, 289
[22] 대법원 1999. 9. 21. 선고 97누5114 판결
[23] 경건, “정보공개청구권의 근거”, 행벙판례백선, 1999, 380
[27] 오픈 거버먼트는 공공데이터의 개방과 밀접한 관계가 있지만 그 보다는 좀더 넓은 개념이라고 할 수 있다. 공공데이타의 개방이 오픈 거버먼트의 핵심적인 요소이긴 하지만 정부 및 행정의 투명성을 높이기 위해 더 많은 웹 2.0 적인 기술과 문화가 채택되고 이를 포괄하는 것이 오픈 거버먼트인데, 정부 2.0과 혼용되기도 한다.
[28] 최선희,“웹2.0과 정부의 역할변화”,정보통신정책 제20권, 2008, 8
[29] 윤종수, “인터넷산업에 대한 법적규제 및 활성화방안”, 2009, 35
[30] 선라이트 재단의 투명성 체크 리스트(http://sunshinereview.org/index.php/Transparency_checklist)는 정부의 투명성을 측정하는 몇가지 유용한 기준을 제시한다.
[31] 미국 시카고시의 업무수행 메트릭스(Performance Metrics, http://goo.gl/Ipvzc), 캐나다 에드몬트시의 대쉬보드(The Citizen Dashboard, http://goo.gl/Rq8Wr) 등이 그 예이다. 서울시도 뒤에서 보는 바와 같은 정보소통광장을 개설하여 행정정보와 공개청구목록 등 시정의 투명성을 높이기 위한 정보를 제공하고 있는데, 형식에 있어 주요 정보를 위와 같은 대쉬보드 형태로 정보를 제공하였으면 하는 아쉬움이 있다.
[32] Beth Simone Noveck, ‘Wiki Government : How Technology Can Make Government Better, Democracy Stronger, and Citizens More Powerful’, Brookings Institution Press, 2009. 팀 오라일리 등이 공저한 ‘열린정부 만들기’(에이콘출판주식회사, 2012) 에 실려있는 “단일장애포인트”는 위 책에서 주요내용을 발췌한 것이다.
[33] 우리나라에서의 다양한 커뮤니티맵핑 사례는 http://wansooim.wordpress.com/%ED%95%9C%EA%B5%AD-community-mapping-project/ 를 참조, http://www.diycity.kr/, http://diycity.org/, http://www.fixmystreet.kr/, http://www.fixmystreet.com/ 와 같이 시민의 참여하에 도시시설의 보수를 해나가는 프로젝트들도 역시 커뮤니티 맵핑의 한 유형이라고 볼 수 있다.
[34] 한국과학기술원, “공공데이터 민간개방의 경제적 효과 분석 연구”, 한국정보화 진흥원, 2012
[35] 진영, 김을동, “공공데이터의 민간개방 및 이용활성화를 위한 정책방안”, 2012, 7
[37] http://www.un.org/en/development/desa/publications/connecting-governments-to-citizens.html 참조, 2013. 3. 15 최종방문
[38] 팀 오라일리, “플랫폼으로서의 정부”, 열린정부 만들기, 2012, 49
[42] http://www.cckorea.org/xe/?mid=news&search_target=tag&search_keyword=%EC%A0%95%EB%B6%802.0&document_srl=29902 2013. 3. 20. 최종방문
[43] 제9조(비공개대상정보) ① 공공기관이 보유·관리하는 정보는 공개대상이 된다. 다만, 다음 각호의 1에 해당하는 정보에 대하여는 이를 공개하지 아니할 수 있다.
1. 다른 법률 또는 법률이 위임한 명령(국회규칙·대법원규칙·헌법재판소규칙·중앙선거관리위원회규칙·대통령령 및 조례에 한한다)에 의하여 비밀 또는 비공개 사항으로 규정된 정보
2. 국가안전보장·국방·통일·외교관계 등에 관한 사항으로서 공개될 경우 국가의 중대한 이익을 현저히 해할 우려가 있다고 인정되는 정보
3. 공개될 경우 국민의 생명·신체 및 재산의 보호에 현저한 지장을 초래할 우려가 있다고 인정되는 정보
4. 진행중인 재판에 관련된 정보와 범죄의 예방, 수사, 공소의 제기 및 유지, 형의 집행, 교정, 보안처분에 관한 사항으로서 공개될 경우 그 직무수행을 현저히 곤란하게 하거나 형사피고인의 공정한 재판을 받을 권리를 침해한다고 인정할 만한 상당한 이유가 있는 정보
5. 감사·감독·검사·시험·규제·입찰계약·기술개발·인사관리·의사결정과정 또는 내부검토과정에 있는 사항 등으로서 공개될 경우 업무의 공정한 수행이나 연구·개발에 현저한 지장을 초래한다고 인정할 만한 상당한 이유가 있는 정보
6. 당해 정보에 포함되어 있는 이름·주민등록번호 등 개인에 관한 사항으로서 공개될 경우 개인의 사생활의 비밀 또는 자유를 침해할 우려가 있다고 인정되는 정보. 다만, 다음에 열거한 개인에 관한 정보는 제외한다.
가. 법령이 정하는 바에 따라 열람할 수 있는 정보
나. 공공기관이 공표를 목적으로 작성하거나 취득한 정보로서 개인의 사생활의 비밀과 자유를 부당하게 침해하지 않는 정보
다. 공공기관이 작성하거나 취득한 정보로서 공개하는 것이 공익 또는 개인의 권리구제를 위하여 필요하다고 인정되는 정보
라. 직무를 수행한 공무원의 성명·직위
마. 공개하는 것이 공익을 위하여 필요한 경우로써 법령에 의하여 국가 또는 지방자치단체가 업무의 일부를 위탁 또는 위촉한 개인의 성명·직업
7. 법인·단체 또는 개인(이하 "법인등"이라 한다)의 경영·영업상 비밀에 관한 사항으로서 공개될 경우 법인등의 정당한 이익을 현저히 해할 우려가 있다고 인정되는 정보. 다만, 다음에 열거한 정보를 제외한다.
가. 사업활동에 의하여 발생하는 위해로부터 사람의 생명·신체 또는 건강을 보호하기 위하여 공개할 필요가 있는 정보
나. 위법·부당한 사업활동으로부터 국민의 재산 또는 생활을 보호하기 위하여 공개할 필요가 있는 정보
8. 공개될 경우 부동산 투기·매점매석 등으로 특정인에게 이익 또는 불이익을 줄 우려가 있다고 인정되는 정보
[44] http://spotcrime.com/, https://www.crimereports.com/, http://www.police.uk/crime/?q=??%20??, http://www.crimemapping.com 등 참조, 한편 ChicagoCrime 등으로 잘 알려졌던 로컬정보 사이트인 http://everyblock.com/ 는 모회사인 msnbc의 결정에 따라 2013. 2. 7. 문을 닫은 바 있다. 문을 닫은 구체적인 이유에 대해서는 알려져 있지 않다.
[45] 새로 개편된 데이터 포털들에 대해서는 아직 구체적인 이용자들의 피드백이 충분히 확보되지 않아 이 글에서는 간략하게 개요 정도에 대해 소개하는 걸로 그친다. 피드백이 확보되는 대로 다시 정리할 예정이다.
[46] http://goo.gl/7MQOg 2013. 3. 20. 최종방문
[47] 국가정보화기본법 제3조 제7호에 의하면 국가적으로 보존 및 이용 가치가 있는 자료로서 학술, 문화, 과학기술, 행정 등에 관한 디지털화된 자료나 디지털화의 필요성이 인정되는 자료로 정의되어 있다. 모든 공공데이터를 포함하기에는 제한적인 개념이다.
[48] 자세한 내용은 http://goo.gl/l7EBl 과 http://goo.gl/LHddq 참조, 2013. 3. 20. 최후 방문
[49] 위 법률안은 “공공기관이 보유, 관리하는 공공데이터를 제공하여야 한다”라고 규정하여 공개의 주체가 애매하나, ‘공공기관이’는 ‘공공기관은’의 오타로 보이므로 공개의 주체는 공공기관으로 봐야 할 것이다.
[50] http://news.dongascience.com/PHP/NewsView.php?kisaid=20110521100000000198&classcode=0108 2013. 3. 15. 최후 방문
[51] 정보공개법 제10조, 제11조, 동법 시행령 제11조
[52] 이와 관련해서는 호주 정부의 정부 2.0 태스크포스 보고서의 제2장 제2절을 참조. 원문은 http://www.finance.gov.au/publications/gov20taskforcereport/index.html, CC Korea가 번역한 번역서는 http://goo.gl/ybr8E 에서 확인할 수 있다.
[53] 콘텐츠진흥법은 종래의 온라인디지털콘텐츠산업발전법에서의 온라인디지털콘텐츠와 달리 오프라인이나 아날로그 콘텐츠 모두를 포괄하는 개념으로서 “부호ㆍ문자ㆍ도형ㆍ색채ㆍ음성ㆍ음향ㆍ이미지 및 영상 등(이들의 복합체를 포함한다)의 자료 또는 정보”로 보호대상인 콘텐츠로 규정하고 있다.
[54] 데이터베이스제작자의 권리도 포함되는 것으로 해석된다.
[55] 미국 시카고시의 겨울철 생활에 필요한 앱의 모음인 Winter Apps(http://goo.gl/9lf6v )나 보스턴 시의 겨울철 눈에 덮힌 소화전을 찾을 수 있도록 도와주는 Adopt a Fire Hydrant(http://adoptahydrant.org/) 는 지역의 특성에 맞는 시기적절한 솔류션이 나올 수 있는 데이터를 제공해서 실질적인 효용을 만들어 낸 좋은 예라고 할 수 있다.
[56] http://www.socrata.com/open-data-field-guide-chapter/implementation/ 참조 2013. 3. 15. 최후 방문
[57] 오바마 정부는 가장 예민한 데이터들이라 할 수 있는 선거 캠페인의 재정자료, 로비자료. 백악관 방문기록 등을 윤리(Ethics) 데이터라 하여 별도록 페이지를 만들고 공개하고 있다. https://explore.data.gov/ethics, 미연방 정부의 데이터 포탈에서 실제 가장 많이 검색되고 조회된 데이타셋도 백악관의 방문기록이다.
[58] 앞서 본 공공데이터의 제공 및 이용 활성화에 관한 법률안에서는 ‘기계 판독이 가능한’이란 표현을 사용하고 이를 “데이터가 충분히 구조화되어 이어서 소프트웨어로 그 개별내용 및 내부구조를 확인하고 수정, 변환, 추출 등 가공할 수 있는 상태”로 정의하고 있다. 모든 데이터는 어떤 의미에서든 기계가 읽을 수 있으므로 정확한 표현은 기계가 처리(process)할 수 있는지 여부라는 관점에서 기계처리형(machine processable) 포맷으로 불러야 한다는 견해도 있다. http://opengovdata.io/2012-02/page/5-1-2/principle-data-format-matters 참조
[59] Joshua Tauberer, ‘Open Government Data’
[61] http://www.peterkrantz.com/2012/publishing-open-data-api-design/ 참조,2013. 3. 15. 최후 방문
[62] 이러한 의미에서 데이터 성격에 따라 오픈 API, 파일, csv 등 복수의 형태로 서비스를 제공하고 있는 서울 열린 데이터 광장의 Dataset Multi Service는 바람직한 시도라 할 것이다.
[63] 컴퓨터와 네트워크 등 정보시스템의 발달로 방대한 정보가 축적되었고 따라서 정보화 시대의 핵심은 방대한 정보에서 자신에게 유용한 정보를 어떻게 찾아내고 효율적으로 접근하여 이용하느냐에 있다. 그러나 광대한 네트워크 안에 흩어져 있는 수많은 정보들은 그 자체가 구조화되어 있지 않고 자연어의 모임인 텍스트나 이미지 등으로 되어 있어 체계적으로 정리하고 찾아내기가 어렵다. 따라서 이러한 정보자원들을 컴퓨터가 해석할 수 있고 인간과 컴퓨터, 컴퓨터와 컴퓨터 사이에 일관된 커뮤니케이션이 가능하도록 할 필요가 있는데 이때 필요한 것이 컴퓨터 온톨로지이다. RDF(Resource Description Framework)는 컴퓨터 온톨로지 언어 중 하나로 주어부(subject), 목적부(object), 서술부(predicate)의 트리플(trifle) 구조를 취하고 있는 것으로, 개념 혹은 인스턴스 사이의 관계를 단순화해서 나타낸다. 일반적으로 복잡한 제약조건이 필요 없는 일반 응용을 산정할 경우에 RDF를 많이 사용한다. CC Korea, ‘CCL과 클린사이트가이드라인’, 저작권보호센터, 2009, 102, http://goo.gl/IEBhq 에서 다운받을 수 있다.
[64] URI는 웹 상의 자원을 식별하기 위한 것으로, 웹 사용자들에게 잘 알려진 URL을 일반화한 형태로 단순하면서 널리 알려졌고, 광범위한 주소표현이 가능하다. URL이 기본적으로 웹상에 리소스를 참조하는 것이라면, URI는 이 계층적인 명명체계 안에 있다면 무엇이든지 참조할 수 있도록 고안된 것이다.
[65] CC Korea, “CCL과 클린사이트가이드라인’, 103
[66] 가장 대표적인 링크드 데이타 허브는 구조화 된 웹 데이터의 전형인 위키피디아의 데이터를 링크드 데이터로 전환시킨 DBpedia www.dbpedia.org/ 이다.
[67] 오원석, “공공정보 활용, 링크드데이터로 똑똑하게”, http://www.bloter.net/archives/132627, 2013 3. 20. 최후 방문
[68] 링크드 데이터에 대한 추가적인 정보는 http://kdata.kr 을 참조
[70] 국립중앙도서관의 링크드 데이타 사이트인 http://nlk.linkeddata.kr/home/ 참조
[71] 허지성, “소셜 큐레이션, 마케팅의 변화 예고”, LG 경제연구원, 2012, 26
[73] 소프트웨어 개발자, 그래픽 디자이너, 기획자들이 모여 단기간 내에 집중적으로 소프트웨어 프로젝트를 협업으로 진행하는 행사를 말한다. 보통 하루에서 길게는 일주일 정도 한자리에 모여 밤낮으로 개발을 진행한다.
[83] http://codenamu.org/, 페이스북 그룹인 ‘열려라 공공데이터’를 함께 운영하고 있다. https://www.facebook.com/groups/243881459064203/
[87] 약 50명의 개발자와 디자이너, 기획자들이 모여 금요일 저녁에 모여 약 20시간 동안 밤을 새며 공공데이터를 이용한 어플리케이션 개발을 진행하였다. 처음 만난 사람들이 현장에서 팀을 구성하여 아이디어를 내고 선정된 아이디어를 구현하는 협업작업이었다.
[88] http://gilstar.com/watcher, 모바일 앱도 지원한다.
[89] http://ansim.me/, 모바일도 지원한다.