Research Data Management:
A Primer
State University of New York
College of Environmental Science and Forestry
F. Franklin Moon Library
Alison Bressler, Master of Wetland and Water Resource Studies
Zachary Lafaver, Master of Professional Studies in Ecology
Jessica Clemons, Interim Director of College Libraries
About the authors:
Alison Bressler is studying the impact of shrub willow on ecosystem services in the Lake Ontario watershed in SUNY-ESF’s Graduate Program in Environmental Science. Alison’s research focuses on biogeochemical reactions that impact greenhouse gas emissions at the soil/atmosphere interface in managed agricultural ecosystems and she is passionate about minimizing the negative impacts of conventional agriculture on global water quality and on climate change. Alison became interested in data management while learning to manage extensive data collection during her undergraduate research with the River Basin’s Research Initiative in South Carolina.
Zachary Lafaver is pursuing a Master of Professional Studies in Ecology. Zach completed his B.S. in Biology at Nazareth College. His scientific interests lie in aquatic habitats where he can observe and study the interactions and characteristics among these diverse areas. Zach became interested in data management after realizing how much work it takes to effectively organize and manage the data that goes along with research.
Jessica Clemons is the Interim Director of College Libraries at SUNY ESF and has led the team that created this data management handbook. She has a strong background in digital collections in a variety of settings from oral histories to datasets. She is an open access advocate and teaches classes on research data management and information literacy. Jessica enjoys the challenge of thinking about the future of libraries and how we can balance traditional services with cutting-edge opportunities.
This project was funded by a I2NY Library as Publisher Grant in 2015. F. Franklin Moon Library is grateful for the support of that innovative grant as we look into sustainable methods of publishing and scholarly communication.
Table of Contents
- Managing and Sharing Data
- Documenting and Formatting Your Data
- File Naming Conventions
- Spreadsheets
- Organizing Fields
- Data Dictionary
- Quality Assurance/Quality Control and Project Management
- Databases and Queries
- Backing Up Data
- 3-2-1 Rule
- Choosing a Backup System
- Data Backup Locations
- Recommended Data Backup Services
- Metadata
- Metadata Standards
- Metadata Schema
- Controlled Vocabularies
- Best Practices
- Existing Metadata Standards
- Dublin Core
- Darwin Core
- EML - Ecological Metadata Language
- Geospatial Metadata Standards
- Morpho
- Data Management Plan (DMP)
- Citation
- Ownership
- ORP POLICY 10 - Ownership of Data
- Definitions Set by SUNY-ESF
- Data Repositories
- What is a data repository?
- How do they work?
- Examples
Managing and Sharing Data
Data that is loved tends to survive
– Kurt Bollacker, Data Scientist
Research data management and data management planning have been receiving a lot of attention in the past decade, and rightfully so. The National Institute of Health (NIH) has had data management requirements in place since 2003 and the National Science Foundation (NSF) followed with their own requirements in 2011. These two research funding agencies represent a large portion of available federal research funds. Simply put, if researchers will be funded by these agencies, they need to comply with the application requirements.
Research data management (RDM) or data management plans (DMPs) are processes that describe how data will be collected, described, documented, shared, and preserved as part of a project. DMPs may be created for personal use, as part of laboratory groups with multiple users, or federally mandated and required for funding agencies to distribute awards. From file naming to sharing datasets via data repositories, this multi-faceted process is an essential piece of the modern research process.
Even without the consideration of federal funding requirements, data management is an important practice. Data that are not represented in literature are essentially lost without management. Future research may be entirely dependent on the data management practices of today.
It is important to note that this primer just scratches the surface of what can be learned about managing data. The authors have included links and references to help those who want to learn more find some of the resources that we have found to be helpful.
You are part of a network of researchers and data managers. We hope that this resource will help you manage your data more confidently. Future researchers will thank you.
Documenting and Formatting Your Data
Keeping track of thousands of data points requires organization and planning. It is best to start good data management habits at the beginning of data collection, rather than trying to clean up and organize your data set at the end of data collection, when the task seems insurmountable. This section will provide you with tips on how to organize your data effectively, so that you can easily reference different data points and fields. This will aid other researchers in understanding your data once it is published in the data repository. This section will provide a framework for file naming, and will provide tips on creating spreadsheets that can be easily analyzed using multiple platforms.
- File Naming Conventions
It is important to name your files using a consistent system. This helps you find files later on and organize them in chronological order. Before collecting data, design a template to use for all of your data, and stick to it throughout the data collection process. Consistency is key.
- Start with the date. Each sample or group of samples is going to have a specific date attached to it. Following the International Organization for Standardization 8601 format, name the beginning of the file using one of the following methods:
- Date: YYYY-MM-DD
- Date and Time: YYYY-MM-DDTHH:MM:SS
- Week: YYYY-W
- Follow the date with the location of the data collection. For instance, the name of the forest or lake where you collected the data. If you have collected data from multiple locations, make sure you attach a recognizable name to each location.
- Follow the name with the lab number(s). For instance, if a file has lab numbers 137-190, include the range of numbers at the end of the file name.
- Keep the file name under 25 characters to avoid overly complicated names; this makes it easier to reference later.
- In addition to elements that should be included in the file name, other elements should be avoided. This will decrease the likelihood of complications when moving data to different platforms for analysis.
- Replace spaces with underscores (_)
- Avoid these characters: “ / \ : * ‘ < > { } $ &
- Generally avoid using punctuation
- If naming a file that does not contain data, you may use the following format to easily recognize the file later:
- Author Name_Year_Section of Title
Examples:
For Data: 2015-04-12-Tulley-234-698
2015-01-04-Vincent-1-320
For Documents: Smith_2014_Survey
Jones_2015_DataDictionary
Mattson_2013_Thesis
This will help you find specific data and documents later on without having to search through each file. This standardized method will also allow others to easily interpret your data.
B. Spreadsheets
A spreadsheet is most useful when it is simplified to the point that it can be plugged into a software analysis package and easily manipulated. The main goal is to remove extraneous information other than the necessary values and labels.
- Combine lots of little tables into one big table or create separate tabs in your Excel spreadsheet for each unique table. Remove graphs and charts, and place them in their own tab. Graphs and charts should be labeled so that you can go back and reference the raw data if necessary without having to place them in the same spreadsheet with the data.
- If you are color coding certain fields in your spreadsheet to indicate different qualities of the data, add another column to indicate which samples fall into specific categories. You will no longer be able to glean information from the data set simply by scanning it with your eyes, but will be able to conduct statistical analysis on the previously highlighted characteristic. The goal of this is to shift from human readability to computer readability.
- Assign null values as blank cells instead of zero. Zero is a value with meaning and does not imply that a data point was invalid or not collected. Software analysis tools will usually recognize blank cells as null values.
- You want to be able to easily import the table into analysis software to conduct statistical analysis. All explanatory information can be placed in a data dictionary or metadata for further reference.
C. Organizing Fields
- Each row should represent a new and unique record such as a sample; each column should contain a category that each record is analyzed for.
- Organized, clear data sets will save time down the road for your research team and other researchers accessing your data in a repository, helping them understand and analyze your data without altering the data sheets.
Example Excel Spreadsheet:
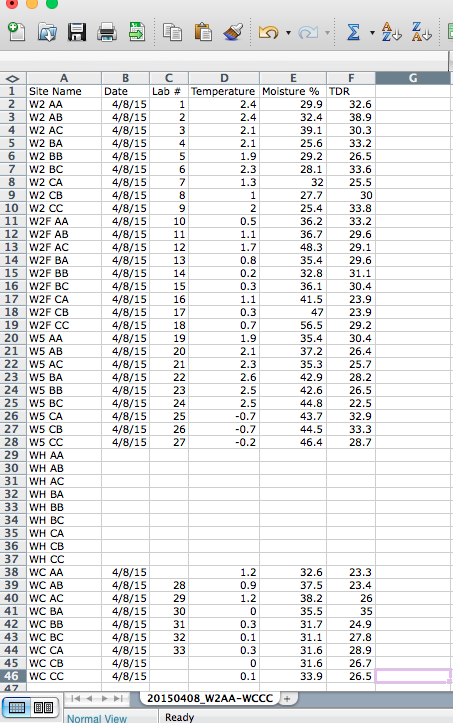
Leaving a cell blank or writing N/A signifies that data was not available. You can put a note in your data dictionary (explained in the next section) indicating why data is missing.
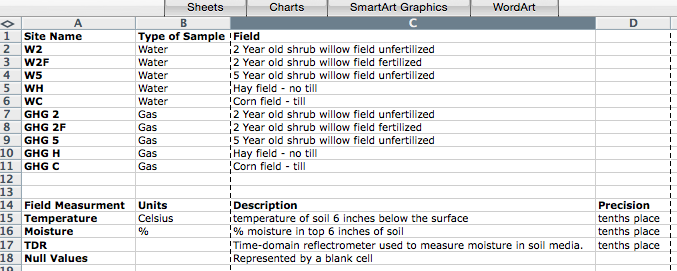
D. Data Dictionary
A data dictionary should provide a context within which anyone could interpret the variables in your data set. Instead of including notes and explanations in your data sheet, attach a separate file in the data repository with detailed information. Think of this as an expansion of the metadata attached to your data.
The following are examples of elements to include in your data repository:
- Variable Name
- Variable Meaning
- Variable Format
- Precision of Data
- Units
- Known Issues with the Data
- Relationship to Other Variables
- Null Values
Include anything else that someone looking at your data for the first time would need to know to understand the raw data. For instance, if data from one of your field sites is missing due to instrument failure or extreme weather conditions, add a note in the data dictionary explaining the anomaly. If you use acronyms in your spreadsheets, provide the full term and a brief explanation. If you use a coding system, explain how the system works.
E. Quality Assurance/Quality Control and Project Management
- QA/QC is a method used by many regulatory agencies to engage in quality control for products and environmental issues, such as emissions standards. Agencies will define their own standards to meet the needs of the issues they are working with. There is not one way to conduct QA/QC.
- Project management was developed to manage complex technical development and manufacturing projects, such as construction projects. Project management has evolved over time and is now used in the laboratory setting as well to help keep projects and data organized.
- Project management may be involved in every aspect of a project: conceptualizing, initiating, planning, executing/controlling, and closing out projects. A project management framework can be developed for a lab to keep research protocol consistent between projects. The framework defines how to manage the project by classifying and organizing project management concepts/methods. It also includes five management stages that each include activity definitions, templates, and examples.
Step 1: Plan - define start and end dates and establish line item resource budgets
Step 2: Organize - specify roles and responsibilities for project personnel
Step 3: Control - organizing, focusing, and motivating project personnel
F. Databases and Queries
Databases can be used as a way to organize, store, manage, and retrieve information. A database is an organized list of facts and information that can come in many forms, from simply text or numbers to images, sounds, and videos. You can import your data from spreadsheets and other formats into a database to make finding the data easier later. Relational database systems are likely what you work with in your research. They include one or more tables that are uniquely identified by the labels for the columns and rows. A database is searchable through a query, meaning that a specific term or number can be searched to find specific information quickly within the database.
Many databases use Structured Query Language (SQL) standard query format, which is the American National Standards Institute’s standard language for relational database management systems. SQL is used to communicate with a database. Standard SQL commands include: “select,” “insert,” “update,” “delete,” “create,” and “drop.” For instance, our course management system involves an interface where we enter commands into the course database to add and drop classes. For more information on how to use SQL visit http://www.sqlcourse.com/ for a tutorial.
Sources and further materials:
Data Management Video Series. File Naming Conventions. University of Wisconsin Data
Services. <https://www.youtube.com/watch?v=4NH1KIXV6qI> Accessed (Apr 13 2015).
Data Management Video Series. Data Dictionaries. University of Wisconsin Data
Services. <https://www.youtube.com/watch?v=Fe3i9qyqPjo> Accessed (Apr 13 2015).
Data Management Video Series. Spreadsheet Best Practices. University of Wisconsin Data
Services.< https://www.youtube.com/watch?v=f11-0Ce1i3I> Accessed (Apr 13 2015).
Dripdot. How to Create a Data Dictionary.
<https://www.youtube.com/watch?v=AeVJy-ow2b0> Accessed (Apr 14 2015).
File Naming Conventions. Data Management: Data. University of Nebraska, Lincoln.
<http://unl.libguides.com/c.php?g=51638&p=333885> Accessed (Apr 15 2015).
ISO 8601:2004(en). Data Elements and Interchange Formats - Information Interchange -
Representation of Dates and Times. <https://www.iso.org/obp/ui/#iso:std:iso:8601:ed-3:v1:en> Accessed (Apr 13 2015).
Portny, Stanley E. and Jim Austin. 2002. Project Management for Scientists. Science.
<http://sciencecareers.sciencemag.org/career_magazine/previous_issues/articles/200
2_07_12/nodoi.11589789757837229753> Accessed (April 23 2015).
Project Management Advisor. <http://www.pma.doit.wisc.edu/> Accessed (Apr 23 2015).
SQL Course Curriculum. Interactive Online SQL Training. <http://www.sqlcourse.com/>
Accessed (April 15 2015).
III. Backing Up Data
In addition to storing your data in a repository for the use of future researchers, it is also important to backup your data throughout the research process. Properly storing data in multiple locations will help prevent your data from being lost in case there is an accident involving your computer. Backing up data may have associated costs. However, these costs must be weighed against the cost of losing your data.
A. 3-2-1 Rule: 3 backup copies, 2 different storage media types, 1 of which is offsite.
- In addition to the copy on your lab computer or laptop (your primary data) keep at least two more backups. For instance, one on an external hard drive, cd, or flashdrive, and one in the cloud on one of the services listed below (this copy is off site in case of natural disaster). Since these two file storage methods are different, it is unlikely that both will fail at the same time.
- It is also good practice to keep a binder in your lab with hard copies of your spreadsheets along with the original hand-written field sheets.
B. Choosing a Backup System
- Look for a service that provides:
- unlimited storage
- file sharing - limit access to data to people with access passwords to prevent tampering or theft of data while providing secure access to the research team. If you don’t wish to share data, store it in a secure location such as a cloud service or a local backup server that cannot be shared online.
- file versioning - save different versions of files so if you accidentally delete something, it could be recovered easily.
- Timing backups - decide the frequency at which your data needs to be backed up. Once a week? Once a day? Online Cloud services can be set to automatically backup your data on a schedule.
- Security
- Secure Sockets Layer (SSL) - establishes an encrypted link between a server and a client; allowing sensitive information like social security numbers and login credentials to be transmitted securely. Asymmetric and Symmetric Encryption can both be used to encrypt and decrypt information.
- encryption of data being stored
- folder permissions and passwords
- geographic redundancy - store information on separate servers in different locations to avoid servers being destroyed by a natural disaster. For instance, store data on both the East Coast and the West Coast or in the Midwest. It is unlikely that all three places will get destroyed by a natural disaster at the same time.
- Mobile access
- Help and support availability
C. Data Backup Locations
- Local: CD/DVD, external hard drive, USB Flash drive
- Cloud: online, accessible from anywhere and from multiple devices. Secure, password protected.
D. Recommended Data Backup Services
Carbonite http://www.carbonite.com/
- relatively low cost for unlimited data backup
- capable of file sharing
- design your own backup schedule
- incremental backups occur when you make changes to files or add new files
- saves old versions of files for 30 days in case you goof
- 128-bit encryption, secure cloud storage, but limited mobile accessibility
- redundant storage - 15 independent disk drives
IDrive https://www.idrive.com/
- Maximum storage is 4 TB
- File sharing capacity and public link sharing
- redundant storage
- mobile access - sync between multiple devices.
- Help and support gets very high ratings
SugarSync https://www.sugarsync.com/
- If you want to be able to share files with your whole team, SugarSync is an easy, cheap, and secure means of doing so.
- Storage plans range from 60GB to 1TB, plans are scalable so that you only pay for what you need.
- Save up to five versions of a file, but only the most recent version counts towards storage limit.
- File sharing on multiple platforms and through public links.
Sources and further materials:
Behind the Scenes of SSl Cryptography: Everything You Want to Know About the
Cryptography Behind SSL Encryption. Digicert.
<https://www.digicert.com/ssl-cryptography.htm>. [Accessed April 30, 2015].
Carbonite. Personal Plans. <http://www.carbonite.com/online-backup/personal/how-it-works>.
[Accessed April 30, 2015].
2015 Best: Online Storage Services Review: Reviews and Comparisons.
<http://online-storage-service-review.toptenreviews.com/>. [Accessed April 30, 2015].
University of Oregon Libraries. “Data Storage and Backup.” Research Data Management.
<https://library.uoregon.edu/datamanagement/storage.html>. [Accessed April 30, 2015].
Levkina, Maria. 2014. How to follow the 3-2-1 backup rule with Veeam Backup & Replication.
<http://www.veeam.com/blog/how-to-follow-the-3-2-1-backup-rule-with-veeam-backup-replication.html>. [Accessed May 4th 2015].
IV. Metadata
Defined as “data about data” or more specifically, “structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource.”
Zeng & Qin (2008)
- Helps describe an information resource.
- Records information that will allow us to locate, describe, retrieve, and manage an information resource.
- When metadata guidelines or standards are followed, it becomes an extremely useful and effective tool.
- Metadata Standards:
- Facilitate the exchange of information in an accurate manner, maintaining the quality of the data so others can easily understand it.
- Guides the “design, creation, and implementation of data structure, values, content, and exchange in an efficient and consistent manner” (Zeng, 2008).
- Created by an organization or community with a focus on making metadata work smoothly by fitting specific criteria.
Metadata standards are able to work with help from controlled vocabularies, metadata schemas, and best practices.
B. Controlled vocabularies are used in order to achieve consistency in the description of information
resources
- Range in complexity from a short list to a thesaurus with thousands of terms and associated relationships among terms.
- Terms in a controlled vocabulary must have unambiguous, unique definitions.
- Allows for ease of translation of record to other languages
- Provides consistency/uniformity when describing a resource and an easy way to label and browse (to locate desired content objects), to retrieve information.
- One of the most commonly used controlled vocabularies is the Library of Congress Subject Headings: http://id.loc.gov/authorities/subjects.html
- There are different controlled vocabularies that can be used. Each discipline usually has its own specific vocabulary. The key is to be consistent and use the official terms.
C. Metadata Schema:
- Method for encoding metadata into XML or other machine readable languages. This is guided by the use of an element set.
- Element Set - defines each and every field of information that is required, repeatable, or optional in a metadata record.
- Dictionary/guide for a metadata schema with examples provided of how to encode the information.
- Include many different and specific elements depending on the schema.
- For example, the Dublin Core Metadata Standard has fifteen required fields: contributor, coverage, creator, date, description, format, identifier, language, publisher, relation, rights, source, subject, title, and type.
D. Best Practices
- The researchers, faculty and students, need to add metadata as completely as possible.
- Ideally, the metadata schema is determined in the project planning stages.
- Consult with librarians and/or information professionals early in the process to determine what language or schema will be used, which data can be collected or automated, and to streamline the process.
- Existing guides can help inform you of exactly how to create your metadata. Most metadata standards have active communities that constantly add to and amend best practices.
Scientists/researchers build off of each other’s work and constantly repeat experiments to check the validity of results. Metadata ensures that the information that you create and record has a way to be distributed properly, accurately, and effectively to members of your specific field of study.
References:
Zeng, M., & Qin, J. 2008. Metadata. New York: Neal-Schuman.
E. Existing Metadata Standards
1. Dublin Core
- Metadata initiative designed to describe information resources. Maintained and edited by the Dublin Core Metadata Initiative that works with many professionals to constantly improve the standard.
- Designed for simple and effective resource description.
- Simplified Dublin Core is comprised of 15 main elements needed for the minimal description of an information resource.
- Title
- Creator
- Subject
- Description
- Publisher
- Contributor
- Date
- Type
- Format
- Identifier
- Source
- Language
- Relation
- Coverage
- Rights
- For more information: http://dublincore.org/
2. Darwin Core
- Biodiversity informatics data standard adapted from the Dublin Core Metadata standard.
- Darwin core is a body of standards designed to facilitate the sharing of information about biological diversity.
- Designed to describe observations in nature, specimens, samples, and related information.
- Simple Darwin Core: smaller version of Darwin Core that provides a minimum element set that can be used to describe biodiversity informatics.
- For more information: http://rs.tdwg.org/dwc/
http://tools.gbif.org/dwca-assistant/
3. EML - Ecological Metadata Language
- Based on work done by the Ecological Society of America.
- Uses Morpho as a platform
- Provides international, interactive maps with data
- Common language for scientists in the ecological discipline.
- Used for the Long Term Ecological Research Network (LTER), the National Center for Ecological Analysis and Synthesis, The Knowledge Network for Biocomplexity (KNB), and by the Global Biodiversity Information Facility (GBIF)
For more information:
http://www.dcc.ac.uk/resources/metadata-standards/eml-ecological-metadata-language
4. Geospatial Metadata Standards:
FGDC: ISO
- FGDC was inspired by CSDGM which was the US Federal Government's required metadata standard since 1995. It is designed as a replacement for this standard.
- Used for the description of geographic information and services. Specifically designed to be able to properly describe: geographic services, datasets, dataset series, individual geographic features and properties.
- For more information see: https://www.iso.org/obp/ui/#iso:std:iso:19115:-1:ed-1:v1:en
http://www.fgdc.gov/metadata/geospatial-metadata-standards
5. Morpho
Data management for earth, environmental and ecological scientists
- Created and maintained by KNB, the Knowledge Network for Biocomplexity, an international repository whose mission is to facilitate ecological and environmental research.
- Morpho is a data management software intended for generating metadata in EML format.
- Designed to aid in the creation and editing of EML Metadata, aid to search for existing data packages, view and download said packages, verify and edit your data, specify access options for your personal data, and share and publish your data on KNB.
- For more information: https://knb.ecoinformatics.org/#about
- User guide: https://knb.ecoinformatics.org/software/dist/MorphoUserGuide.pdf
https://knb.ecoinformatics.org/#about
V. Data Management Plan (DMP)
A DMP is a brief document that describes how the researcher will create and share their research results. DMPs are usually created to comply with federal funding requirements and they are excellent resources for lab groups to create to facilitate and coordinate data gathering. According to NSF policies, a DMP considers five main points:
1. The types of data, samples, physical collections, software, curriculum materials, and other materials to be produced in the course of the project;
2. The standards to be used for data format, metadata format, and content (where existing standards are absent or deemed inadequate, this should be documented along with any proposed solutions or remedies);
3. Policies for access and sharing including: provisions for appropriate protection of privacy, confidentiality, security, intellectual property, or other rights or requirements;
4. Policies and provisions for re-use, re-distribution, and the production of derivatives;
5. plans for archiving data, samples, other research products, and for preservation of access to them.
*The DMP plan and requirements will depend upon the funding agency, but most of them are very similar*
The Data Management Planning Tool (https://dmptool.org/) uses standards and templates from the requirements of various funding agencies to help create a DMP document. The DMP tool prompts you to create a login, and pick a funding agency. Once selected, fill in the different sections and answer the required questions and the DMP tool will create the document for you.
Here is an example taken from DMP tool: (https://dmptool.org/plans/8278.pdf)
VI. Citation

Citing datasets is just as important as citing journal articles. Give credit to the creator of the data set, the way you would give credit to an author. Citation styles for datasets and metadata differ from traditional citations of the written word. Although there are multiple citation standards (MLA, APA, Chicago…) to chose from for traditional citations, there are limited standards for citing data. Datacite Initiative (https://www.datacite.org/) is developing a set of standards outlined below:
DataCite Recommended format:
- Creator (PublicationYear): Title. Publisher. Identifier
- Creator (PublicationYear): Title. Version. Publisher.ResourceType. Identifier
Examples:
- Irino, T; Tada, R (2009): Chemical and mineral compositions of sediments from ODP Site 127‐797. Geological Institute, University of Tokyo.http://dx.doi.org/10.1594/PANGAEA.726855
- Geofon operator (2009): GEFON event gfz2009kciu (NW Balkan Region). GeoForschungsZentrum Potsdam (GFZ).http://dx.doi.org/10.1594/GFZ.GEOFON.gfz2009kciu
- Denhard, Michael (2009): dphase_mpeps: MicroPEPS LAF‐Ensemble run by DWD for the MAP D‐PHASE project. World Data Center for Climate.http://dx.doi.org/10.1594/WDCC/dphase_mpeps
Note: DataCite recommends that DOI names are displayed as linkable, permanent URLs. This will make finding the data later much easier. For easy reference, here is a link to a citation formatter that requires you to input a DOI: http://crosscite.org/citeproc/
If the journal article that describes the dataset is available, cite the article along with the data set.
Citation Managers:
Through the use of research tools like Zotero, or Mendeley, citing your data can be much easier. These programs are citation managers, which consolidate your references and make writing up the citation sections of a paper much easier and faster. Zotero Versus Mendeley: https://www.youtube.com/watch?v=53QRA_SNSzE
VII. Ownership
SUNY TITLE J – Patents, inventions, and copyright policy: http://www.suny.edu/sunypp/documents.cfm?doc_id=88
A. ORP Policy 10 - Ownership of Data
Summary - Sections Pulled Directly from Original Document
This policy was developed by SUNY-ESF in order to provide the basis for identification of ownership of information. Data ownership can be complicated when a team of researchers collectively acquires, stores, analyzes, and publishes data. Regulations and standards associated with different funding sources may further complicate things. There is a need for clear policies on the rights and responsibilities of data ownership in the University setting. These policies may be specific to each university (ORP Policy 10). For example:
Eastern Michigan University’s Policy:
“Raw data (including laboratory notebooks) and processed data are generally owned by the University. University ownership is subject to conditions established by granting agencies or contracts with sponsors. Management of research data according to these conditions is implicitly delegated to the Principal Investigator and the Administrator of the unit in which he/she works.” (2009 Policy)
SUNY-ESF adopted Eastern Michigan’s principles of Data Ownership (ORP Policy 10).
B. Definitions Set by SUNY-ESF
“ Data: NIH Grants policy statement (2001) definition of data:
“Recorded information………including writings, films, sound recordings, pictorial reproductions, drawings, designs or other graphic representations, procedural manuals, forms, diagrams, work flow charts, equipment descriptions, data files, data processing or computer programs (software), statistical records and other research” materials.
We clarify further that other research materials include field notebooks, physical collections, biological specimens, cell lines, digital database files and other tangible artifacts.
Ownership: Termed a “bundle of rights” by Shores (2001-2). We define data ownership as:
The right to possess, use, manage, gain income from, copyright, patent, register, destroy, control indefinitely, and transmit data; and the duty to refrain from its use in ways harming others. (adapted from A.M. Honore 1961 and Washington State interagency agreement)
Usual University resources: Resources commonly provided or made available to faculty (University of Michigan 2007). These include, but are not limited to, libraries and other buildings, computers, secretarial and administrative support staff, and supplies.
Independent work: This is separate from extramurally-funded grants or contracts. It may be carried out utilizing University space, facilities, or usual University resources, by faculty or by students, but not as a directive from University administration or faculty.” (ORP Policy 10)
A full list of policies including this one can be found at the link below:
http://www.esf.edu/research/resources/
VIII. Data Repositories
A. What is a data repository?
A data repository is a location set for collecting data sets and metadata for the use of archiving and sharing. This allows others to view and search for data they may be interested in as well as preserving data for future use.
B. How do they work?
First, you must choose the repository that you would like to use. Certain repositories have guidelines for the type of data and files that can be shared within their repository. Once you choose the repository, you can view their guidelines for what types of files are accepted. You can search/view, or share your own data now by fulfilling their guidelines. It may useful to include a “read-me” file with metadata for others to read so they may understand the data sets that they’re observing.
C. Examples
There are many data repositories out there set for all types of data. Whether someone is interested in ecology, geographical systems, chemistry, etc. there are different repositories that one may utilize for searching, archiving, or sharing their data.
- ESF has an institutional repository for data and other scholarly output Digital Commons @ ESF (http://digitalcommons.esf.edu/)
- Figshare, Databasin, KNB, the ESA registry, Dataverse, and Dryad are repositories that have been popular when one is considering a repository to use. You can find more on the data repositories here: http://libguides.esf.edu/c.php?g=159873&p=1047092
- Choosing a data repository depends on the type of data you are generating.
- There are many repositories out there to choose from. Here is a list of some more suggested choices: http://libguides.esf.edu/data
Example of the types of data stored on Digital Commons @ ESF