Guida di OpenSpending
A cura dell’OpenSpending data team
Anders Pedersen, Rufus Pollock, Michael Bauer, Neil Ashton, Lisa Evans, Tony Hirst, Pierre Chrzanowski, Félix Ontañón, Oluseun Onigbinde, Vítor Baptista
Introduzione
Cos’è OpenSpending?
OpenSpending è una comunità di condivisione dati e applicazioni web che mira a tracciare ogni transazione finanziaria di governi e aziende di tutto il mondo, presentando i dati in una forma utile e coinvolgente. OpenSpending è un progetto open gestito da una comunità di contributori. Chiunque sia interessato a sfruttare dati di qualsiasi tipo è invitato a contribuire al database OpenSpending, a creare visualizzazioni con il software OpenSpending, e a utilizzare le API messe a disposizione.
Questo capitolo introduce i nuovi collaboratori OpenSpending ai concetti fondamentali del sistema. Esso descrive il tipo di dati finanziari che OpenSpending supporta, e spiega come vengano rappresentati i dati.
Vorresti tradurre questa guida?
Non vediamo l’ora di veder tradotta questa guida, per consentire al maggior numero di utenti di utilizzare OpenSpending.
Se stai cercando di tradurla abbiamo alcuni suggerimenti che si potrebbero prendere in considerazione:
- Crea una copia di questo documento. Puoi fare questo tramite il menu “File” di Google Docs
- Se siete un gruppo di traduzione, assicuratevi di essere d'accordo su alcune delle nozioni di base prima di iniziare
- Usate gli screen shot nell’ordine in cui appaiono
- Se avete delle correzioni per la guida, fatecelo sapere aggiungendo un commento alla sezione inglese
Quali tipi di dati finanziari entrano in OpenSpending?
OpenSpending è molto flessibile nel tipo di dati finanziari che supporta. Anche se il progetto OpenSpending ha un forte focus sulla finanza pubblica, questo non è un vincolo tecnico. OpenSpending supporta qualsiasi insieme di dati costituito da un insieme di transazioni, ciascuna associata ad una quantità di denaro e un periodo di tempo.
La maggior parte dei dati attualmente ospitati su OpenSpending possono essere classificati come dati transazionali o di bilancio. La differenza principale tra questi è il loro livello di granularità. Dati transazionali o di transazione tracciano singole operazioni, mentre i dati sul bilancio aggregano le transazioni in categorie.
Dati di spesa derivanti da transazioni
I dati di transazione, o semplicemente "i dati di spesa", tracciano singole operazioni finanziarie. Ogni pagamento tra singoli soggetti, in una determinata data, e per uno scopo specifico (ad esempio, un progetto o un servizio) è elencato singolarmente. Dati di spesa transazionali comprendono vari tipi di record, comprese le informazioni sui contributi pubblici, le obbligazioni, e le spese effettive.
Le informazioni aggregate (ad esempio la somma) non dovrebbero essere incluse nei dati di transazione. Dati che sono stati parzialmente o completamente aggregati richiedono una diversa modalità di analisi e devono essere trattati come dati di bilancio piuttosto che dati di transazione. Ciò non significa, tuttavia, che i diversi pagamenti "fisici", che si riferiscono ad una singola transazione "logica" non possano essere rappresentati da una singola operazione nella tipologia dei dati transazionali.
I dati di transazione in OpenSpending includono:
Un altro tipo correlato di dati si riferisce alle procedure di aggiudicazione degli appalti pubblici. Dati sugli appalti sono dati relativi a gare pubbliche: quanto è stato offerto, per quanto, e chi ha vinto la gara. Esso può essere visto come un sottoinsieme dei dati di transazione.
I dati sugli appalti comprendono:
Dati di bilancio
Nei dati di bilancio, le spese e i redditi sono aggregati per categorie. L'obiettivo di questa aggregazione è quello di aiutare il lettore nella comprensione del bilancio, che in genere è un documento di policy che viene utilizzato per fornire una panoramica sulle più importanti scelte finanziarie del governo. L'allocazione dei dati è tipicamente strutturata da uno schema di classificazione, piuttosto che tramite i destinatari effettivi dei fondi.
I dati di bilancio spesso presentano congiuntamente dati sui risultati del passato e sugli stanziamenti per un periodo futuro. In una tale presentazione, gli importi spesi negli anni precedenti su un particolare settore, sono utilizzati per informare su quanto dovrebbe essere assegnato per il prossimo periodo di programmazione finanziaria. Le informazioni di bilancio spesso si basano su stime e dati aggregati.
Diverse regioni riportano differenti tipi di informazioni di bilancio disponibili, tra cui: Dichiarazioni Pre-Budget, proposte di bilancio esecutivo, bilanci promulgati, e fondi stanziati per i cittadini (versioni semplificate di quote di bilancio a beneficio dei cittadini).
I dati di bilancio su OpenSpending includono:
Come vengono rappresentati i dati su OpenSpending.
OpenSpending mantiene una collezione di dataset, ciascuna delle quali rappresenta un insieme di dati derivanti da una sorgente separata. All'interno di ogni set di dati, le transazioni individuali sono rappresentate da un insieme di voci. Ogni set di dati ha un modello proprio che mappa la struttura dei dati stessi. Il modello codifica le proprietà di ogni set in termini di dimensioni.
Dataset
L'unità di base del sistema OpenSpending è il dataset. Le transazioni finanziarie che condividono un tema comune (ad esempio, la spesa di una particolare città, un bilancio per un determinato anno) vengono raggruppate e memorizzate come un set di dati. Un dataset è una raccolta di "voci", e ogni voce rappresenta una singola transazione associata ad una quantità di soldi e ad un periodo di tempo.
Modelli
La struttura di ogni dataset dipende completamente dal suo creatore. Questa struttura viene creata specificando un modello che fornisce le dimensioni lungo le quali i vari item possono differire l'uno dall'altro.
Un modello consiste in un insieme di dimensioni. Una dimensione è una proprietà che potenzialmente differenzia una voce da un’ altra. Se pensate ad un dataset come un foglio di calcolo, ciascuna dimensione può essere pensata come una colonna. Tuttavia le dimensioni possono avere più struttura di una normale colonna del foglio di calcolo.
Le dimensioni sono di diversi tipi. La più importante è il tipo di misura. Le misure sono dimensioni che possono contenere un singolo valore numerico. Un' altra importante tipologia di dimensione è il tempo, che rappresenta date e orari. Ogni dato necessita di almeno una misura e una dimensione di tempo, che rappresentano rispettivamente la quantità di denaro presente nella transazione e il momento in cui ha avuto luogo.
Le rimanenti tipologie di dimensioni sono utilizzate per rappresentare altre proprietà che gli item potrebbero avere, ad esempio: numeri di transazione, etichette provenienti da uno schema di classificazione,, oppure i nomi delle persone o le società coinvolte. Tali dimensioni comprendono gli attributi, che possono contenere un singolo valore, e le dimensioni composte, che possono contenere un insieme nidificato di valori. Le dimensioni composte sono utili quando una proprietà include diverse sotto-proprietà che potrebbero essere utilizzate per aggregare i dati.
Aggiungere dati ad OpenSpending
Overview
Uno dei contributi più importanti per il progetto OpenSpending è quello di aggiungere un nuovo dataset. Questa sezione della guida vi spiegherà il processo tramite cui aggiungere nuovi dati.
Un flusso di lavoro tipico per l'importazione di un insieme di dati in OpenSpending prevede le seguenti fasi:
- raccogliere dati leggibili da una fonte attendibile
- Convertire i dati in un file CSV nel formato atteso dal OpenSpending, pulendolo per rimuovere incongruenze ed errori
- Pubblicare i dati sul web
- Creare un dataset aggiungendo i dati pubblicati come nuova fonte
- Modella il dataset per assegnare un ruolo ad ogni colonna presente nella tabella di origine
- Caricare o rifinisci i dati in base al feedback fornito dalla piattaforma, in base alla coerenza dei propri dati.
Ognuno di questi passi sarà spiegato in dettaglio nelle seguenti sezioni.
Raccolta dati
Per aggiungere un dataset ad OpenSpending, è necessario disporre di alcuni dati. Se già li avete, si può procedere. In caso contrario, è necessario trovarli.
Inizia la tua ricerca dati consultando alcune risorse, come la School of Data e il Data Journalism Handbook. È inoltre possibile ottenere alcune idee su come strutturare la ricerca visitando l’ OpenSpending group su datahub.io, e porre domande sul canale IRC # openspending su Freenode.
I dati che troverete, si spera siano in un formato "leggibile", per esempio sotto forma di un foglio di calcolo di Excel o in un file CSV. Se trovate i dati in un formato come PDF o un documento Word, questo sarà molto difficile da lavorare, e si potrebbe considerare semplicemente di cercare dati diversi!
Formattare i dati
Openspending si aspetta che tutti i dati sian presentati in un formato semplice.
CSV
OpenSpending accetta dati in un formato di file singolo, il Comma Separated Value (CSV). CSV è un file di testo che rappresenta i dati in forma di tabella, simile a un foglio di calcolo. In una tabella, ciascun dato è rappresentato da una riga, e le proprietà di ciascun dato sono rappresentate da una colonna. I file CSV codificano le tabelle dando ad ogni riga una linea nel file di testo e separando le colonne tramite virgole.
I CSV accettati da OpenSpending sono denormalizzati, il che significa che essi non liberano spazio eliminando i valori ridondanti. Inoltre file CSV di OpenSpending sono a forma rettangolare, ovvero posseggono esattamente lo stesso numero di colonne in ogni riga.
Il format OpenSpending
I file CSV di OpenSpending devo avere le seguenti proprietà.
- Una riga di intestazione. La prima riga del file CSV deve contenere i nomi delle colonne, separati da virgole. Tutte le altre righe vengono trattate come righe dei dati.
- Almeno tre colonne. Valori indispensabili delle colonne sono: un importo, la data (in cui ci si potrebbe riferire solo all’anno), e un compratore o un destinatario (che potrebbe essere il nome di un account).
- Colonne corrispondenti. Ogni colonna deve rappresentare sempre un singolo tipo di valore per tutte le righe. (Non ci può essere nessuna riga sottointestata, per esempio.)
- Le righe sono punti dati. Le righe devono contenere un solo tipo di informazione: una transazione o una linea di bilancio. Una riga deve rappresentare al massimo un solo periodo di tempo. (Le righe non possono rappresentare più transazioni.)
- Nessun riga o cella vuota. Ogni riga di un file di dati importato deve contenere tutte le informazioni necessarie per costruire l'oggetto risultante.
- Nessun totale pre-aggregato (per es. totali parziali o "roll-up"). OpenSpending calcolerà questi automaticamente.
- Un identificatore unico. Ci deve essere una colonna (o una combinazione di colonne) il cui valore identifica in modo univoco ogni riga. Il modo più semplice per creare un tale identificativo è quello di aggiungere una colonna fittizia al dataset in cui si inserisce un numero che per ciascuna riga aumenta. È possibile farlo in Excel digitando i numeri nelle prime due file, selezionando entrambe le celle e trascinando verso il basso l'angolo inferiore destro della cella per estendere la serie. Se l'insieme dei dati ha troppe righe per Excel, è possibile aggiungere la colonna di identificazione unica usando mySQL.
- Le date nel formato corretto. Le date devono essere nel formato "aaaa-mm-gg".
- I numeri nel formato corretto. I numeri devono contenere solo cifre e un periodo opzionale - no virgole! (Numeri leggibili come "12,345.67" devono essere convertiti in numeri come "12.345,67".)
La comunità di OpenSpending ha raccolto qualche esempio di fogli di calcolo, al fine di illustrare come appaiono “buoni”o “cattivi” dati tabulari.
Qui sono presentati esempi di cattiva formattazione dei fogli di calcolo:
- transazioni multiple su una riga, (diversi anni su di una stessa riga)
- cattivi numeri, (i numeri hanno le virgole per leggibilità)
- Washington, DC (dati sulle transazioni)
- Minsk, Belarus (dati sui bilanci)
Pubblicare i dati sul web
I dati non possono (ancora) essere caricati direttamente su OpenSpending. Per essere aggiunti al database OpenSpending, i dati devono prima essere resi accessibili dal web. Questa sezione presenta due modi convenienti per pubblicare il dataset on-line.
Google Drive
È possibile rendere i dati accessibili sul web, trasformandoli in un foglio di calcolo di Google Drive.
- Importa i tuoi dati. Crea un nuovo foglio di calcolo di Google Drive, quindi seleziona Import ... dal menu File. Selezionare Replace Spreadsheet, fai clic su Choose file, e sposta il file CSV.
- Assicurati che Google Docs non sfalsi le date dei vostri dati. Seleziona la colonna che contiene le date. Fai clic sul menu Format e selezionare Number -> More formats -> 2008-09-26. I dati dovrebbero apparire nel formato aaaa-mm-gg .
- Fai clic sul menu File e seleziona Publish to the web .... Nella finestra che appare, clic sul pulsante Start publishing. Sotto get a link to the published data , select CSV (comma separated values).
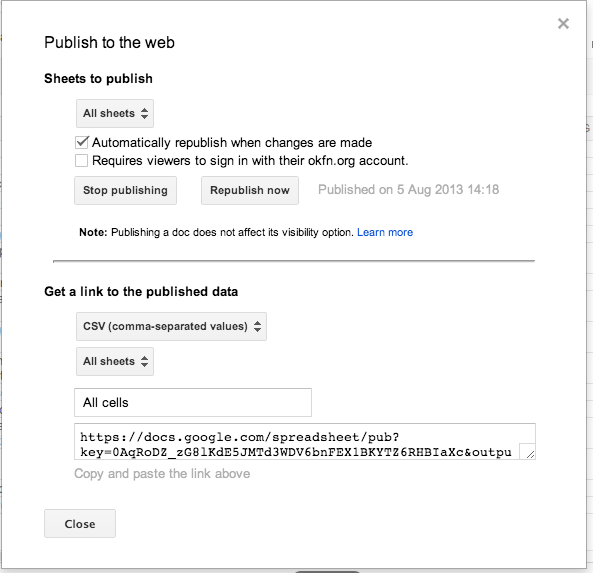
L’URL in fondo al box ora si riferisce ai tuoi dati.
Gist
GitHub Gist è un modo conveniente per ospitare piccole quantità di testo, inclusi i file CSV.
- Fai log-in su GitHub (o registrati se non l'hai già fatto), quindi naviga su gist.github.com.
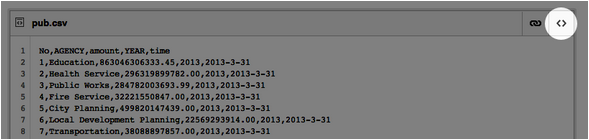
- Fai clic e trascina il file CSV dal file manager del tuo sistema operativo alla pagina di Sintesi GitHub del tuo browser. Verranno visualizzati il nome e il contenuto del file.
- Fare clic su Create Public Gist per essere trasportati nella homepage del vostro nuovo Gist. L'URL relativo ai tuoi dati è accessibile attraverso il pulsante "angle brackets (parentesi angolari)" nell'angolo in alto a destra del file.
Creare un dataset su OpenSpending
Per iniziare la condivisione dei dati sulla piattaforma OpenSpending, registrati su OpenSpending.org e crea un nuovo OpenSpending dataset. Per creare un set di dati, è sufficiente compilare alcuni metadati, che caratterizzano i propri dati, e fornire l'URL in cui i dati sono ospitati.
Crea un nuovo dataset
Accedi OpenSpending.org con le informazioni utente, o registrati se non l'hai ancora fatto. Arriverai alla Dashboard, dove vedrai un pulsante blu etichettato Import a dataset. Fai clic qui per avviare la creazione di un nuovo insieme di dati su OpenSpending.
La schermata successiva richiede di fornire i metadati che contraddistinguono i tuoi dati. Questo include i seguenti campi:
- Title: un nome descrittivo e significativo per il dataset. Può essere qualsiasi stringa.
- Identifier: un titolo più breve, utilizzato come parte dell'URL del dataset. Può contenere solo caratteri alfanumerici, trattini e underscore - senza spazi o segni di punteggiatura.
- Category: "Bilancio", "spese", e "Altro". Vedi la sezione guida riguardo i tipi di dati finanziari per i dettagli su queste categorie.
- Currency: la valuta in cui la spesa descritta dal dataset ha luogo.
- Paesi: l'elenco dei paesi di riferimento nel dataset. La scelta degli Stati è limitata da un elenco di paesi validi.
- Languages: l'elenco delle lingue utilizzate nel dataset. La scelta delle lingue è limitata da un elenco di lingue valide.
- Description: una caratterizzazione del dataset in semplice prosa. Può essere qualsiasi stringa.
Compila tutti questi campi. Assicurati di includere una descrizione che spieghi l'origine del dataset e riconosca tutte le modifiche introdotte (ad esempio, le operazioni di pulizia che hai fatto).
Una volta che tutti i metadati sono state inseriti, premi Next Step per procedere.
Aggiungere una nuova fonte di dati
Facendo clic su next step viene creato il tuo nuovo dataset OpenSpending che ti conduce alla pagina di Gestione. La pagina Gestione viene utilizzata per aggiungere sorgenti dati. E' utilizzato anche per fornire informazioni schematiche che permettono ad OpenSpending di interpretare i dati, un processo chiamato "modelling" che verrà trattato nella prossima sezione della guida.
Per aggiungere una fonte di dati al dataset, fai clic su Add source. Viene visualizzato un messaggio che vi chiederà di inserire un URL. Fornisci l'URL del file CSV che hai pubblicato sul web, nella sezione precedente della guida e fai clic su Create. Vedrai una finestra di testo blu che indica l’elaborazione dati di OpenSpending.
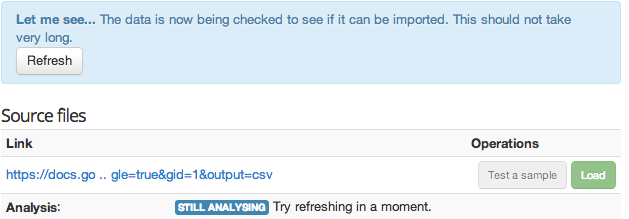
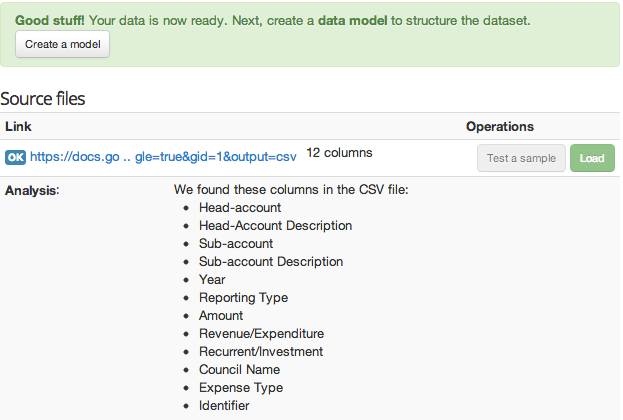
Clicca su Refresh o semplicemente usa il pulsante di aggiornamento del browser. Se OpenSpending riesce ad analizzare i dati, si dovrebbe vedere una casella di testo verde che indica che i dati sono pronti. Si dovrebbe anche vedere un elenco delle colonne del file CSV.
Si noti che se si fornisce ad OpenSpending un file HTML invece di un file CSV valido, il software non si lamenterà, ma semplicemente cercherà di analizzare il codice HTML come se fosse un file CSV. Il risultato è simile al seguente.
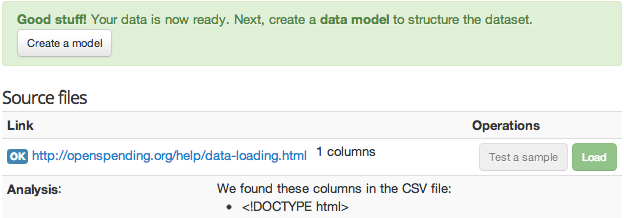
Se hai aggiunto una fonte dati non corretta, non ti preoccupare. Non è necessario utilizzare la fonte nel dataset finale: OpenSpending richiede di lavorare molto su una fonte di dati prima di poter essere pubblicata. Basta aggiungere una nuova, corretta sorgente e dimenticare quello sbagliata.
Modellare i tuoi dati su OpenSpending
Per caricare i dati in OpenSpending, è necessario costruire un modello - dati. Un modello serve a specificare come i dati si traducano in termini che OpenSpending comprenda. OpenSpending rappresenta le proprietà dei dati in termini di dimensioni. I dati di modello si realizzano elencando le dimensioni che si desidera studiare nel dataset caricato su OpenSpending, e specificando come questi si relazionino alle colonne presenti nei dati di origine.
Dimensioni obbligatorie: quantità e tempo
Ogni modello deve avere almeno due dimensioni: una quantità e un tempo. Questi specificano la dimensione della transazione e il momento in cui questa è avvenuta. La quantità e il tempo sono associati a particolari tipi di dimensioni. L'importo viene rappresentato da una misura, e il tempo è rappresentato da una data. Dimensioni generiche non possono rappresentare questi valori specifici.
Quando modelli i dati, non è una cattiva idea quella di iniziare con le dimensioni obbligatorie. Per iniziare, fai clic su Dimensions & Measures all'interno della pagina Manage the dataset.
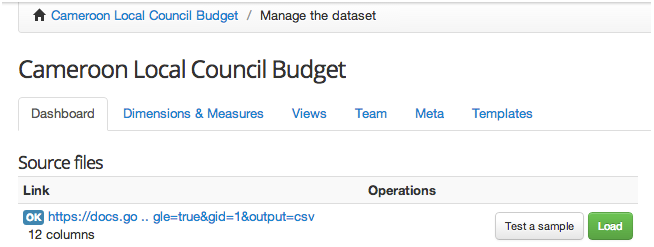
Successivamente, fai clic su Add Dimension per aprire il nuovo pannello Add new dimension. Clicca sul pulsante Date. Vedrai la casella Name box riempirsi automaticamente con il "tempo", come mostrato di seguito. Fai clic sul pulsante verde Aggiungi (Add).
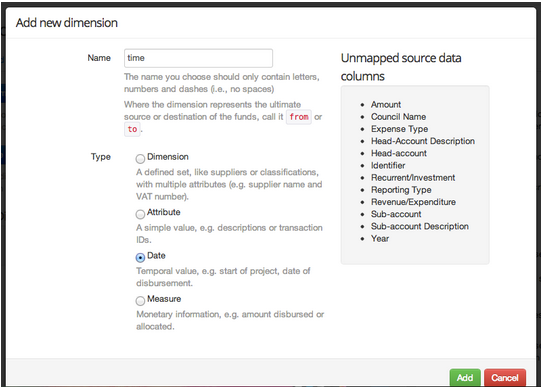
La prossima schermata fornirà alcune informazioni sul significato del tempo. Nella casella a discesa accanto alla Colonna, seleziona la colonna dei dati che rappresenta il valore del tempo.
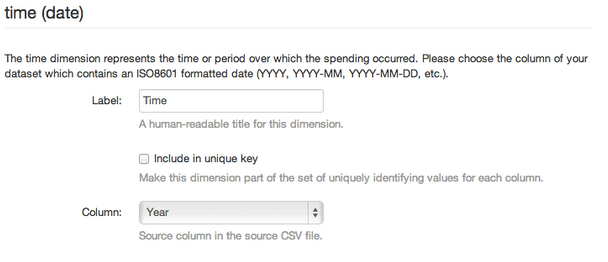
Dopo aver identificato la colonna tempo, fai clic su Add Dimension per aggiungere la dimensione quantità. Questa volta, selezionare il pulsante di opzione Misura, che riempirà automaticamente la colonna "amount", e clicca su Add. Scegli la colonna che rappresenta il valore della transazione tramite il box a discesa accanto alla Colonna.
Le dimensioni chiavi e di compound
Soltanto una dimensione supplementare è necessaria per rendere il modello valido: la dimensione (o insieme di dimensioni) il cui valore identifica ciascun punto dei dati, la chiave.
Un punto dati non deve essere identificato dal valore di una singola colonna. Esso può essere identificato dalla combinazione di varie colonne in una dimensione composta. Poiché le chiavi possono essere composte, il tipo di dimensione deve essere utilizzato per rappresentarle, anche se la chiave particolare non è composta.
Per aggiungere la dimensione chiave, clicca su Add Dimension e seleziona il pulsante Dimension. Inserisci un nome per la chiave, come "key", nel Name box. Fai clic su Add. Selezionare la casella include _ unique key per identificare questa dimensione come parte della vostra chiave.
Successivamente, date un'occhiata alla Field list, che contiene due file name e label. Una dimensione composta può contenere un numero arbitrario di campi, ciascuno dei quali ha un nome e una tipizzazione e ciascuno dei quali può essere associato a una colonna nei dati. Questo è il senso per cui tali dimensioni sono dette "composte": esse raggruppano colonne multiple derivanti dai dati di origine, in una singola proprietà del dataset di destinazione.
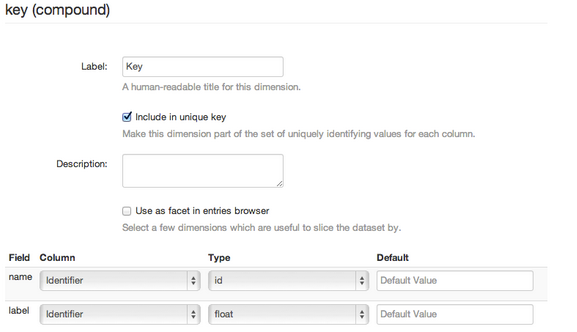
Una dimensione composta richiede almeno due campi, name e label, che devono essere rispettivamente di tipo id e di stringa. Il nome della dimensione viene utilizzato per dotarla di un URL funzionante, l'etichetta viene utilizzata per presentarla nell'interfaccia utente.
Per creare una dimensione composta minima, è sufficiente associare la stessa colonna dei dati di origine con nome ed etichetta. Scegliere la colonna appropriata per ciascuna dimensione e lasciare le tipologie predefiniti invariati.
Misure e altre dimensioni
Con quantità, tempo e chiave, il modello è sufficientemente ricco. Un modello veramente completo, tuttavia, comprenderà dimensioni per ogni proprietà significativa dei dati di origine. Seguendo alcune convenzioni questo diventa più conveniente.
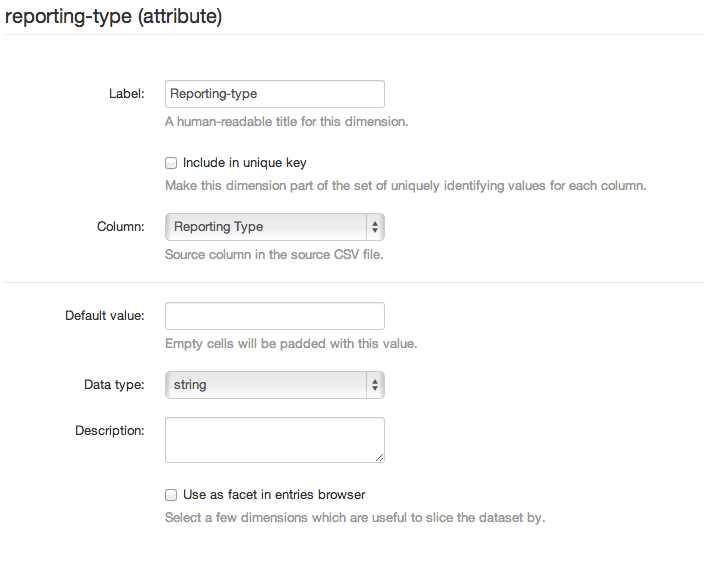
Un modello comune per i dati di origine sta diffondendo informazioni che identificano entità - gruppi, account, e così via - tramite diverse colonne. Le informazioni su un account associato a una transazione ad esempio possono essere visualizzate dividendo in una colonna "Account", con un numero di identificazione e una colonna "descrizione Account" con una descrizione verbale. "Head-account" e "Sub-account" nell'immagine qui di seguito presentano questo modello.
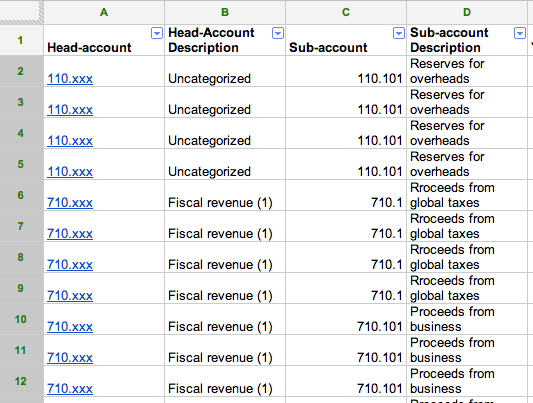
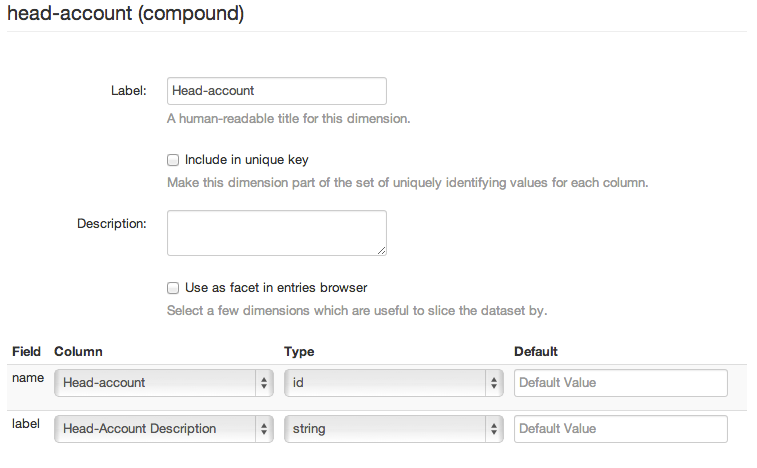
Le dimensioni composte di OpenSpending sono progettate per modellare questo tipo di informazioni sparse. Per farlo, aggiungi una nuova dimensione composta e associa ogni colonna ad uno dei campi della dimensione creata. Cerca di far corrispondere una colonna leggibile e una colonna più concisa per essere rinominata. Nell'immagine sottostante, "Head-account" è abbinato a name e " Head-account description" a label.
Alcune colonne di dati sono più autonome, rappresentando particolari attributi di ciascun punto dati. Una colonna che ordina ogni transazione in qualche categoria, per esempio, è di questo tipo. Nell'immagine sottostante le colonne Reporting Type, Revenue/Expenditure, e Recurrent/Investment sono di questo tipo.
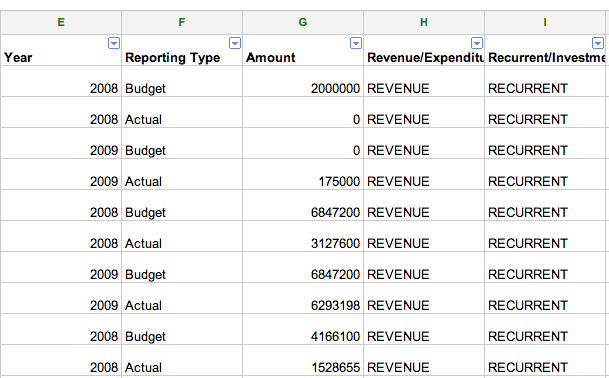
Colonne indipendenti che specificano attributi o categorie sono meglio modellate con le dimensioni attribute. Un attributo è essenzialmente una dimensione con un solo campo, che può essere di qualsiasi tipo. Per creare un attributo, è sufficiente selezionare il pulsante di opzione Attribute quando si aggiunge una dimensione.
Concludendo: salvataggio e caricamento
Quando ogni dimensioni è stato impostata e collegata alle rispettive colonne nei dati di origine, fai clic su Save Dimensions per salvare il modello. Se qualcosa è sbagliato con il modello, viene visualizzato un messaggio di errore che richiede di correggere i parametri. In caso contrario, verrà visualizzato un messaggio che ti invita a tornare alla dashboard, dove si può procedere a caricare i dati.
Una volta che i dati sono stati caricati, il modello creato sarà fisso e il montaggio sarà disattivato. Quindi,volendo, si può testare il modello prima di caricarlo. Per fare questo, clicca su Test nella riga dedicata alla fonte dati presente nella dashboard. Attendi alcuni secondi, quindi ricarica la pagina. Se viene visualizzato un messaggio con uno sfondo verde che dice COMPLETE, il modello è pronto a partire. Se vedi errori, sono necessarie alcune riparazioni.
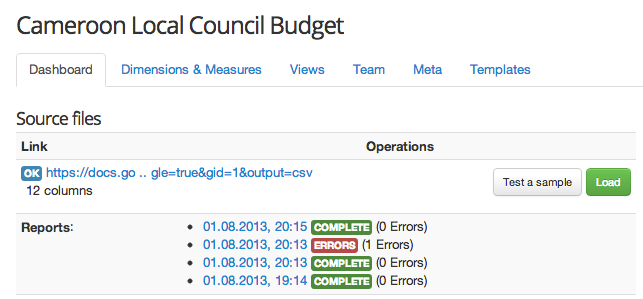
Se il vostro modello è privo di errori, fai clic su Load per caricare il dataset di origine e applicare il modello. Si può quindi tornare alla home page del dataset cliccando sul suo nome nella parte superiore della schermata, in cui è possibile procedere alla costruzione di effetti grafici e giocare con i vostri dati.
Visualizzazioni
Crea una Visualizzazione
La piattaforma OpenSpending rende facile creare e incorporare visualizzazioni di set di dati. Sono supportati tre tipi di visualizzazioni: BubbleTree, TreeMap, e la tabella di aggregati.
Tutte le visualizzazioni presenti in OpenSpending permettono di scegliere una serie di dimensioni lungo le quali aggregare i dati, aumentando il livello di particolarità qualora ve ne sia bisogno. Ogni visualizzazione viene creata nello stesso modo: con la scelta delle dimensioni da aggregare e l'ordine in cui eseguire il drill down.
Per iniziare a creare una visualizzazione, vai alla home page di un dataset e seleziona Create a visualization dal Visualizations menu.
BubbleTree
Il BubbleTree è una visualizzazione interattiva che presenta i dati di spesa aggregati come un cerchio a bolle. Ogni bolla rappresenta un aggregato (sub) totale. La bolla centrale rappresenta una somma aggregata, e le sue bolle circostanti rappresentano le altre somme da cui è composta. Cliccando su ogni bolla, viene mostrato all'utente come la somma si divida ulteriormente in sub-totali .
Per creare un BubbleTree, scegli le dimensioni da aggregare e l'ordine in cui aggregarle. Scegli la dimensione primaria dal menu a cascata. Si vedrà il totale aggregato per quella dimensione, come la bolla centrale, con i singoli valori totali che la circondano.
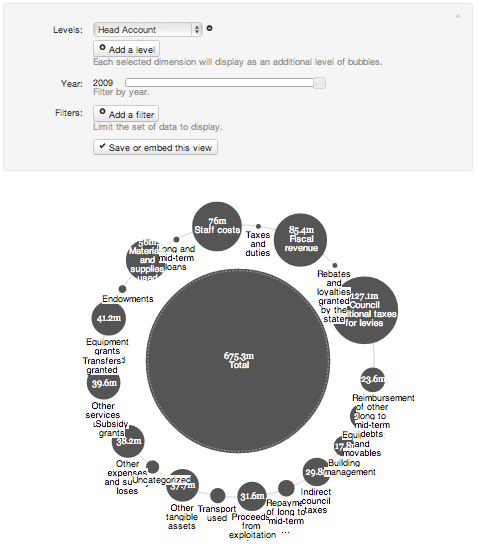
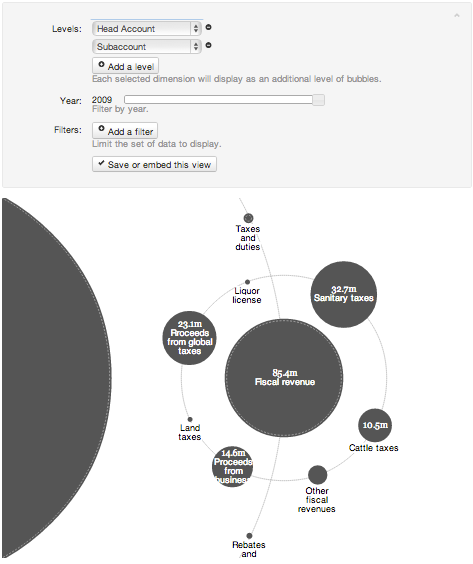
Per aggiungere un secondo livello, clicca su Add a level e scegli una nuova dimensione. Gli utenti saranno ora in grado di fare clic su le bolle di "drill-down" e vedere come i valori del primo livello si suddividono in i singoli valori totali nel secondo livello.
TreeMap
Il TreeMap presenta i dati di spesa aggregati come un rettangolo interattivo composto da rettangoli colorati. Ogni rettangolo rappresenta valori aggregati per una particolare dimensione dei dati. Cliccando su "zooms in" si mostra come è possibile scomporre ed esplorare le dimensioni aggregate.
Per creare un TreeMap, basta scegliere le dimensioni da aggregare e il loro ordine. Seleziona la dimensione primaria dal menu Tile. Vedrai un TreeMap che mostra come la spesa totale scompone attraverso quella dimensione.
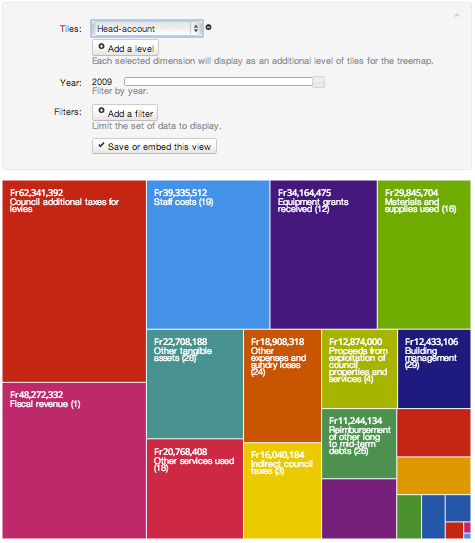
La visualizzazione non è ancora interattiva . L'aggiunta di ulteriori livelli ci mostra come sia possibile scomporre ed esplorare le dimensioni aggregate, permettendo di visualizzare in dettaglio come valori aggregati si scompongano in unità più piccole. Per aggiungere un secondo livello di rettangoli, clicca su Add a level e scegli una nuova dimensione. Gli utenti possono ora scegliere i rettangoli con i quali dividere il totale.
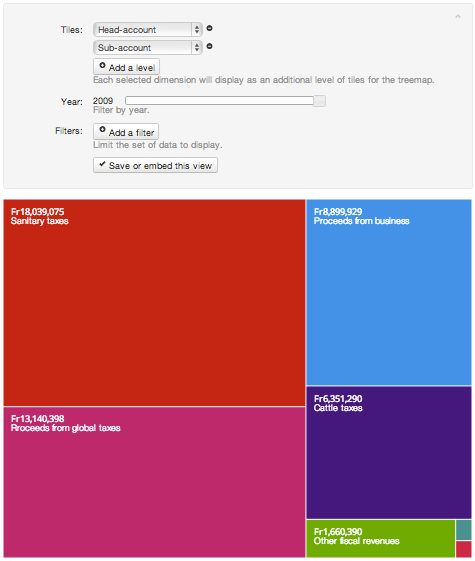
Table of Aggregates
La tabella di aggregati è una semplice rappresentazione tabellare di un dataset che aggrega i totali delle dimensioni scelte. Una tabella di aggregati si specifica scegliendo dimensioni da inserire nelle sue colonne.
La scelta di una dimensione primaria tramite il Column menu visualizza i dati in forma di tabella, con importi aggregati e percentuali del totale complessivo. Di default, le righe verranno ordinati in base a valori percentuali.
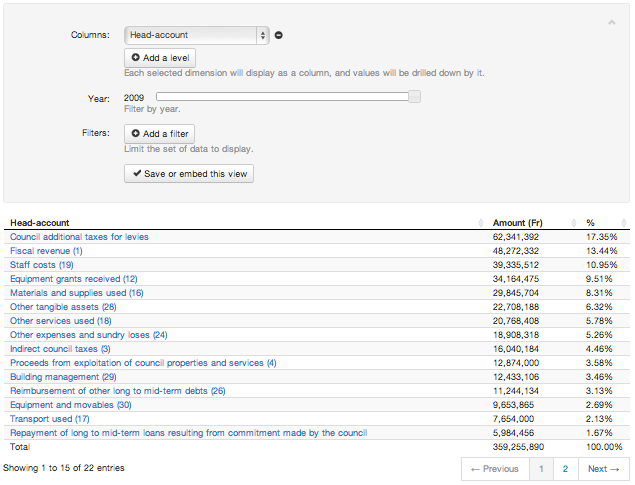
Aggiungendo un'altra colonna, cliccando su Add a level, si rompe ogni subtotale presente nella prima colonna tramite le somme aggregati della nuova colonna. Nota che questo in genere cambia i valori percentuali e riorganizza le righe della tabella.
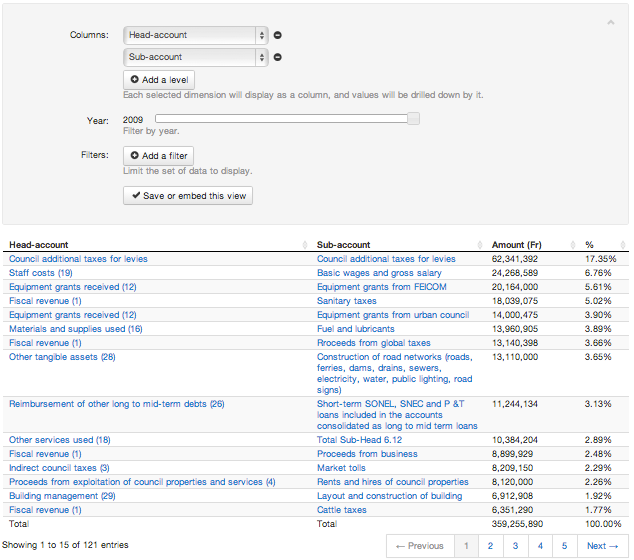
Inserisci una visualizzazione nel tuo sito web.
Si può facilmente incorporare sul prprio sito web una delle visualizzazioni create su OpenSpending. Questo significa che puoi avere i display interattivi anche sul tuo sito.
Presupponiamo che abbiate scelto una visualizzazione su Open Spending. Se noti sulla parte in basso a destra della pagina c'è un pulsante Embed. Fai clic su questo pulsante e ti verrà presentato il codice per incorporare la visualizzazione sul vostro sito web e alcune opzioni per le dimensioni (in pixel) . Per il resto bisogna solo tagliare e incollare questo codice nel tuo sito. Se non siete sicuri su come incollare correttamente il codice, contattare l'amministratore del sito.
Il motivo per cui è possibile incorporare un codice dipende dai widget. In termini molto semplificati, un widget è un pezzo di codice che è possibile aggiungere alla tua pagina web, e tira i dati - in questo caso, dal database di OpenSpending - in modo che non sia necessario memorizzare i dataset per proprio conto.
Siti Satelliti
INESC - Orçamento ao seu Alcançe (Budget alla tua portata?)
Questa è stata una collaborazione tra OKF Brasil _ INESC (Istituto di studi socio-economici), una ONG brasiliano. L'obiettivo era quello di rendere più facile per il pubblico monitorare il bilancio federale brasiliano, e come è suddiviso tra i molti enti pubblici, con una particolare attenzione sui capitoli di spesa.
I dati provengono da SIGA Brasil, un aggregatore dei tanti sistemi utilizzati dal governo per organizzare il bilancio. Questo ci permette di scegliere le colonne che vogliamo, ad esempio ente pubblico, categoria, sottocategoria, budget, spese, ecc, _ esportare in un file CSV. dati dal 2001, fino alla data attuale, aggiornato quotidianamente. A parte alcuni problemi, come le righe con mese "00", non abbiamo dovuto modificare molto per caricarlo in OpenSpending.
Costruire il sito
Sapevamo di volerci concentrare su OpenSpending, cosa che ora avviene a vari livelli per tutti gli enti pubblici. Nel 2012, per esempio, il Ministero dell'Istruzione non ha speso il 16,3% del proprio bilancio (circa 6,1 miliardi di dollari). OpenSpending non aveva un grafico, out-of-the-box, che andrebbe bene per questo tipo di dati. Così abbiamo progettato il nostro software.
Dopo alcune ore di prove, abbiamo deciso di fare un grafico a serie cronologica, con barre e linee. Il grafico in figura X mostra i dati del 2012 del Ministero dell'educazione . L'area blu rappresenta il budget (nota che cambia nel corso dell'anno). Le barre mostrano quanto è stato speso in quel determinato mese, e la linea mostra il totale delle spese fino ad ora. Si può vedere, dalla distanza della linea rossa dalla punta dell'area blu, che a Dicembre è stato alquanto sotto utilizzato.
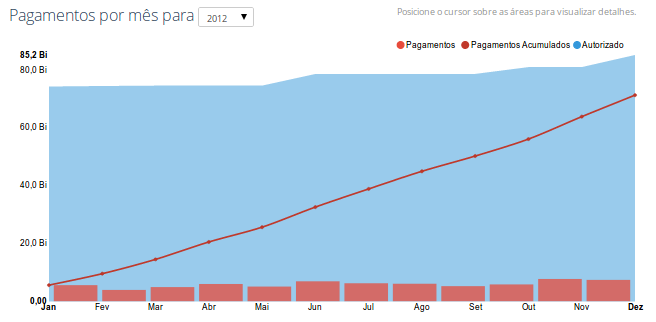
Per costruire questo grafico, stiamo usando NVD3, una libreria JavaScript con una raccolta di grafici riutilizzabili in D3. Il dato proviene da OpenSpending, utilizzando le API Aggregate. E 'ottimo e, dopo aver fatto un aggregazione, il risultato si memorizza nella cache e il programma diventa molto veloce. Ma esiste una limitazione che ci ha dato alcuni problemi: è possibile utilizzare solo una misura alla volta.
Per questo grafico, abbiamo 2 misure: il budget ed i pagamenti. Ma, internamente, i pagamenti sono divisi in due parti: quello che è stato pagato per l'anno in corso, ed i debiti pagati negli anni precedenti. Così, ci troviamo con 3 misure. Visto che l'API Aggregata ne consente solo una, abbiamo dovuto fare tre richieste per la costruzione di questo grafico.
Questo, ovviamente, crea un problema di prestazioni, sia per il nostro progetto sia per OpenSpending stesso. Ma, visto che le richieste vengono memorizzate nella cache dopo il primo utilizzo, si finisce per risolvere tutto. Esistono già piani per supportare più misure nelle API, quindi anche questo problema verrà risolto.
Per usare il Treemap
Nella pagina di indice, abbiamo voluto mostrare una visione ampia del il bilancio riguardante gli enti pubblici. Inoltre, abbiamo voluto mostrare la quantità di denaro che viene utilizzato sia per funzione che per sottofunzione, come l’istruzione generale e l'istruzione di base. Per dimostrare questo, abbiamo scelto il Treemap.
Tramite un widget è stato facile: basta crearlo in OpenSpending, prendere il codice e incollarlo nel sito. Ma abbiamo però incontrato alcune limitazioni.
I widget sono fatti per quando si vuole semplicemente mettere il grafico in un post sul blog o articolo di giornale. Non è possibile personalizzarlo. Abbiamo dovuto cambiare i caratteri e i colori, per farlo entrare all'interno del design del resto della pagina. Dato che è un iframe, non c'è modo di cambiarlo usando solo CSS. Ma c'è una soluzione semplice: copiare il codice iframe del widget nella tua pagina.

Non c'è bisogno di costruire un treemap, bastano poche righe di codice di inizializzazione. Quando è nella tua pagina, è possibile utilizzare anche CSS. Purtroppo, questo non funziona per tutto: i colori non possono essere modificati in questo modo. Ma è facile configurare un altro schema di colori: devi semplicemente cambiare il codice di inizializzazione. Abbiamo anche aggiunto un pulsante "Indietro", in modo da poter navigare facilmente tra funzioni e sottofunzioni.
Searching
Per aiutare l'utente a trovare gli enti pubblici, abbiamo implementato un motore di ricerca con il completamento automatico, utilizzando il plug-in di Twitter Bootstrap typeahead. Poiché non ci sono molte entità (circa 500), abbiamo deciso di caricarle tutte quando l'utente entra prima nella pagina, in modo che la ricerca sia istantanea.
Per farlo, avevamo bisogno di un lista con gli enti pubblici, ei relativi ID. L'API Aggregata, ancora una volta, ci ha aiutato. Con un semplice drill-down da ente pubblico, siamo stati in grado di ottenere tutti i dati di cui avevamo bisogno, e di costruire la ricerca. Se avessimo più entità, dovremmo dovuto utilizzare l'API di ricerca.
Conclusioni
<OpenSpending ci ha aiutato un sacco>
<Noi non abbiamo un database, la nostra pagina è al 100% memorizzabile nella cache. Avremmo potuto fare tutto con solo HTML + JS>
<INESC È in grado di aggiornare i dati, senza alcuna dipendenza da noi>
<Everyone's happy!>