Несмотря на то, что совсем еще недавно виртуализация была неким трендом, зрелость технологии уже доказала, что виртуализация – это не просто самоцель, виртуализация - платформа для построения решений. Решений для бизнеса.
Сегодня я хотел бы рассказать вам об одном из решений в области защиты данных и сервисов, а именно – построение катастрофоустойчивого Центра обработки данных (ЦОД).
Как вы прекрасно понимаете, защита сервисов очень критична для современного бизнеса. Простой сервиса – это и прямые финансовые потери, и репутационный риск. И если с помощью, например, различных систем резервного копирования мы можем в той или иной степени гарантировать защиту (восстановление в случае сбоя) данных. То в области защиты самих сервисов нужны несколько иные решения.
Для защиты от катастроф – выход из строя части серверной комнаты, либо целого ЦОДа – одним из такого рода решений и является построение резервного ЦОДа.
Для начала, давайте поговорим о некоторых рисках внедрения систем, обеспечивающих катастрофоустойчивость. Те риски, которые могут свести на нет все усилия на построение решения.
Один из наиболее влиятельных рисков – это то, что резервный ЦОД может оказаться не актуальным по отношению к вашей текущей ИТ-инфраструктуре. И это касается не только актуализации самих данных. Ваша текущая инфраструктура «живет», развивается: вводятся новые сервисы, модернизируются старые. Если упустить отслеживание этих изменений, актуализацию резервного ЦОДа, не производить периодическое тестирование процедур восстановление – в критической ситуации резерв может просто не заработать.
Следующий риск – человечески фактор. Риск многогранен, если можно так выразиться.
План по восстановлению сложный и содержит много взаимосвязанных частей, и часто представляет собой комплекс работ, необходимых к выполнению вручную. В этом случаев вероятность человеческой ошибки, и её влияние становится крайне велика.
Кроме того, чем менее автоматизирован процесс восстановления, тем дольше и сам период восстановления. Т.е. увеличивается время простоя.
Добавим сюда еще и риск недоступности специалистов по восстановлению систем. Что если в критический момент один из ключевых специалистов окажется недоступным или не сможет прибыть на место для проведения работ? Есть ли замена каждой из ключевых фигур? Зависимость от конкретных людей – это риск в сценарии восстановления.
Как результат эти и другие риски сказывается на стоимости восстановления.
Конечно же, избавиться от всех рисков невозможно – разве что избавиться от самого бизнеса. :) Но если не избежать, то хотя бы минимизировать эти риски можно благодаря автоматизация системы восстановления.
И в этом поможет виртуализация.
Как?
Виртуализация уже своей идеологией несет принципы, которые позволяют нам строить отказоустойчивые решения.

На основе этих принципов лежат все технологические решения VMware. А через технологические решения происходит защита всех уязвимых компонентов ЦОДов. Таким образом, решения VMware в области защиты центров обработки данных несут в себе комплексный характер защиты: начиная от компонент подсистем до всего ЦОДа в целом.

Обратим внимание, что каждый уровень уже имеет свою защиту технологиями виртуальной платформы – программного продукта VMware vSphere. Это позволяет защититься от некоторых локальных сбоев, либо максимально сократить время простоя.
Венчает весь комплекс решения программный продукт VMware vCenter Site Recovery Manager – решение для построения катастрофоустойчивого ЦОДа.
Что из себя представляет этот продукт? Site Recovery Manager – приложение, интерфейсом управления встраиваемое в общую консоль управления виртуальной инфраструктурой vSphere Client. И занимается это приложение контролем всего процесса восстановления. Технически решения представляет собой набор скриптов, интегрируемых с компонентами ИТ-инфраструктуры для проведения работ по восстановлению, контролю за выполнением работ и т.п.
Одно из преимуществ выбора в пользу именно этого решения – возможность еще на этапе проектирования выбора различных топологий построения резервного ЦОДа.

Обратимся к обычной форме построения резервного ЦОДа. Как правило, необходимо сдублировать всю существующую инфраструктуру на резервной площадке. Причем, использовать часто необходимо абсолютно такое же оборудование, что и в основном ЦОДе. Тем самым удваиваются капитальные затраты на серверную инфраструктуру, причем половина затрат будет просто пылиться где-то в другом конце города.
А при необходимости защиты несколько филиалов, может понадобиться строительство резервных ЦОДов для каждого (по крайней мере по части оборудования), ввиду особенностей офисов или используемого там оборудования.
При этом хочется надеяться, что все это резервное оборудование так и будет простаивать – мы же не хотим катастроф в любом случае: есть ли у нас резервные ЦОДы, или их нет.
Решение на основе Site Recovery Manager позволит нам создать инфраструктуру, где:
- Множество филиалов могут быть защищены единым резервным ЦОДом.
- Благодаря аппаратной независимости виртуальных машин, для построения создаваемого резервного ЦОДа возможно использовать устаревшее оборудование, высвободившееся после обновления парка серверов основного ЦОДа или проведения процесса миграции на виртуальную инфраструктуру – если, конечно, вы еще не виртуализировали ваш основной ЦОД.
- Кроме того можно заставить работать резервный ЦОД. Возможно построение двух распределенных ЦОДов, при котором один резервирует второй и наоборот.
Кратко расскажу про техническую простоту решения:

- На двух площадках устанавливаются системы хранения данных, и между ними настраивается репликация данных. В данном случае реплицируются данные виртуальных машин.
Эту часть VMware отдает производителям решения по репликации между СХД – FalconStor, HP, IBM, Hitachi, EMC и т.д.
Далее слоями мы видим компоненты:
- Серверное аппаратное обеспечение подключается к системам хранения.
- На сервера устанавливается платформа виртуализации VMware vSphere.
- На платформе виртуализации разворачивается защищаемая нами виртуальная инфраструктура.
- Платформа виртуальных серверов управляется с помощью vCenter Server, а Site Recovery Manager, в виде встроенного плагина управляет процессом восстановления в случае катастрофы.

В разработке решения по защите от катастроф, без относительно выбранной технологической составляющей решения необходима разработка плана восстановления. Будь то план, состоящий из организационно-административных действий, либо план запуска автоматизированных скриптов для выполнения процедур восстановления.
И именно эта составляющая – план восстановления является одной из особенностей данного решения.

После определения всех необходимых к защите компонентов и сервисов информационной системы, создается сам технологический план:
Планов может быть несколько. Для восстановления каких-то определенных корневых сервисов или всей инфраструктуры основного Центра обработки данных. Грубо говоря, вы можете защитить одну серверную стойку, на случай если она провалится под пол; отдельными планами защитить каждую серверную комнату основного ЦОДа; отдельный план на восстановление всех серверных комнат в резервном ЦОДе.
Каждый план представляет собой пошаговое выполнение инструкций по восстановлению. Тем самым определяется необходимая последовательность действий, зависимости одних действий от других, и критичность запуска.

План в SRM, представляет последовательность всех необходимых действий от выключения, по-возможности, сервисов на пораженном сайте, до пунктов, предназначенных только для проведения тестирования работы плана.
О тестировании.
Тестирование – это немаловажный, и часто сложный процесс проведение периодической проверки работоспособности плана восстановления.
При проверке работоспособности резервного ЦОДа на организационные вопросы накладываются серьёзные технологические проблемы. Например, как запустить сервис в тестовом режиме на резервной площадке, чтобы не помешать работе этого сервиса в основном, и не порушить готовность резерва к боевому включению.
К сожалению, зачастую, проверить работоспособность резервного ЦОДа удается только на момент сдачи его в эксплуатацию, в дальнейшем чаще всего тестирование производится только на бумагах.
Но в SRM и на счет этого есть решение.
Благодаря функции виртуальной среды – изоляции, возможно провести тестовое восстановление и проверить работоспособность всей защищаемой инфраструктуры без влияния на работу сервисов основного сайта. Проследить все шаги этого восстановления. А затем вернуть инфраструктуру резервного ЦОДа в состояние готовности к восстановлению.
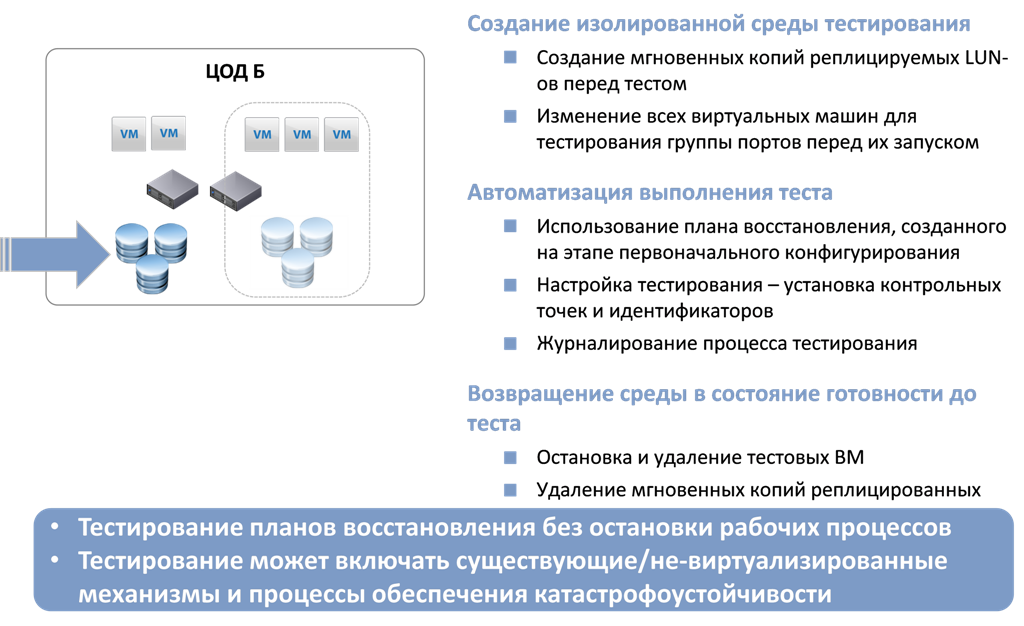
Это так просто, что можно проверять работоспособность хоть каждый день!
Но самое главное – простота процесса восстановления. Запуск работ по восстановлению производится нажатием одной кнопки.

Конечно же, автоматически процесс восстановления никогда не запуститься. Система может понять, что что-то произошло, оповестить об этом, но принятие решения всегда останется за человеком. Мы же не хотим восстания машин?
А запустить и следить за процессом ответственное лицо сможет не выходя из дома, удаленно.
Есть необходимость в защите сервисов от возможных катастроф, но не уверены, когда можно начать создание резервного центра обработки данных? Начните прямо сейчас, вне зависимости от того, внедрена ли у вас виртуализация, или нет. И если вы еще не виртуализировали свою инфраструктуру, то самое время начать.